 一種自監督同變注意力機制,利用自監督方法來彌補監督信號差異
一種自監督同變注意力機制,利用自監督方法來彌補監督信號差異
編者按:近日,計算機視覺頂會 CVPR 2020 接收論文結果揭曉,從 6656 篇有效投稿中錄取了 1470 篇論文,錄取率約為 22%。中科院VIPL實驗室共七篇論文錄取,內容涉及弱監督語義分割、活體檢測、手勢識別、視覺問答、行人搜索、無監督領域自適應方法等方面,本文將予以詳細介紹。
01
1. Self-supervised Equivariant Attention Mechanism for Weakly Supervised Semantic Segmentation (Yude Wang, Jie Zhang, Meina Kan, Shiguang Shan, Xilin Chen)
基于類別標簽的弱監督語義分割作為一個具有挑戰性的問題在近年來得到了深入的研究,而類別響應圖(class activation map,簡稱CAM)始終是這一領域的基礎方法。但是由于強監督與弱監督信號之間存在差異,由類別標簽生成的CAM無法很好地貼合物體邊界。
本文提出了一種自監督同變注意力機制(self-supervised equivariant attention mechanism,簡稱SEAM),利用自監督方法來彌補監督信號差異。在強監督語義分割的數據增廣階段,像素層級標注和輸入圖像需經過相同的仿射變換,自此這種同變性約束被隱式地包含,而這種約束在只有類別標簽的CAM的訓練過程中是缺失的。因此,我們利用經過不同仿射變換的圖片得到的類別響應圖本應滿足的同變性來為網絡訓練提供自監督信號。除此之外,我們提出像素相關模塊(pixel correlation module,簡稱PCM),通過發掘圖像表觀信息,利用相似像素的特征來修正當前像素的預測結果,從而增強CAM預測結果的一致性。我們的方法在PASCAL VOC 2012數據集上進行了充分的實驗,驗證了算法的有效性,并取得當前最好性能。

02
2. Single-Side Domain Generalization for Face Anti-Spoofing (Yunpei Jia, Jie Zhang, Shiguang Shan, Xilin Chen)
由于不同數據集之間存在差異,很多活體檢測方法進行跨數據集測試時性能下降明顯。現有的一些方法借用領域泛化的思想,利用多個已有的源域數據去訓練模型,以得到一個領域不變的特征空間,從而在未知的目標域中進行測試時能利用學習到的通用判別特征,去提升模型的泛化性能。但是,由于不同數據集之間,攻擊樣本相對于正常樣本存在更大的差異(比如說攻擊方式的不同,攻擊樣本之間采集的環境差異),努力讓這些攻擊樣本去學習一個領域不變的特征空間是比較困難的,通常會得到一個次優解,如下圖左邊所示。因此,針對這一個問題,我們提出來一個端到端的單邊領域泛化框架,以進一步提升模型的性能。
其中主要思想在于,對于不同數據集中的正常樣本,我們去學習一個領域不變的特征空間;但是對于不同數據集中的攻擊樣本,我們去學習一個具有分辨性的特征空間,使相同數據集中的攻擊樣本盡可能接近,而不同數據集中的攻擊樣本盡可能遠離。最終效果會使攻擊樣本在特征空間中張成更大的區域,而正常樣本僅僅處在一個緊湊的區域中,從而能夠學習到一個對于正常樣本包圍更緊致的分類器,以達到在未知的目標域上更好的性能,如下圖右邊所示。
具體來說,我們引用一個域判別器,利用一種單邊的對抗學習,讓特征提取器僅僅對于正常樣本提取更具有泛化性能的特征。并且,我們提出一個不均衡的三元組損失函數,讓不同數據集之間的正常樣本盡可能接近而攻擊樣本盡可能遠離,以使得攻擊樣本在特征空間中張成一個更大的范圍。同時,我們還引入了特征和參數歸一化的思想,進一步地提升模型的性能。大量實驗表明,我們提出的方法是有效的,并且在四個公開數據庫上均達到了最優的性能。

03
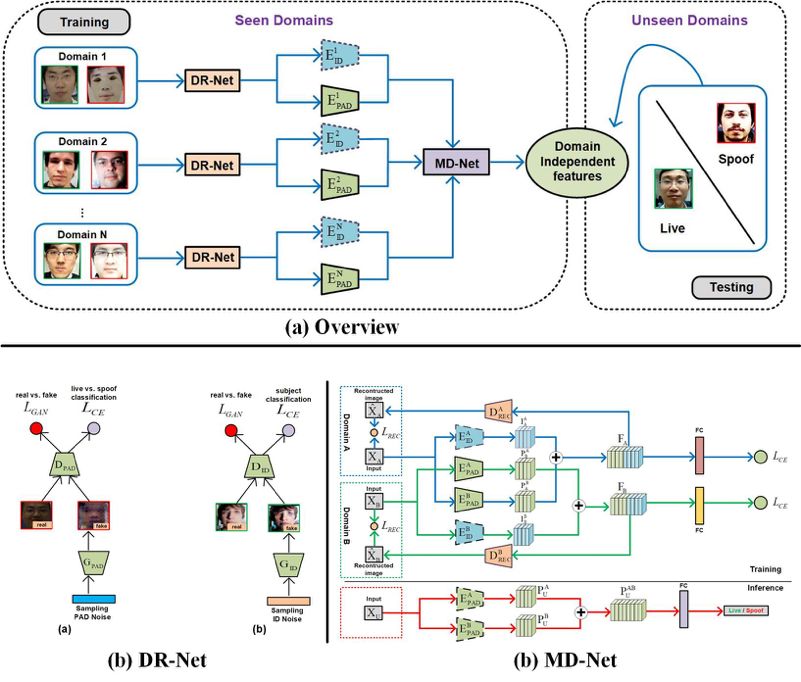
3. Cross-domain Face Presentation Attack Detection via Multi-domain Disentangled Representation Learning (Guoqing Wang, Hu Han, Shiguang Shan, Xilin Chen)
目前,人臉呈現攻擊檢測(Presentation Attack Detection, 簡稱PAD)成為人臉識別系統中一個亟待解決的問題。傳統的方法通常認為測試集和訓練集來自于同一個域,結果表明這些方法并不能很好的推廣到未知場景中,因為學到的特征表示可能會對訓練集中的身份、光照等信息產生過擬合。
為此,本文針對跨域人臉呈現攻擊檢測提出一種高效的特征解耦方法。我們的方法包含特征解耦模塊(DR-Net)和多域學習模塊(MD-Net)。DR-Net通過生成模型學習了一對特征編碼器,可以解耦得到PAD相關的特征和身份信息相關的特征。MD-Net利用來自于不同域中解耦得到的特征進一步學習和解耦,得到與域無關的解耦特征。在當前公開的幾個數據集上的實驗驗證了所提方法的有效性。
04
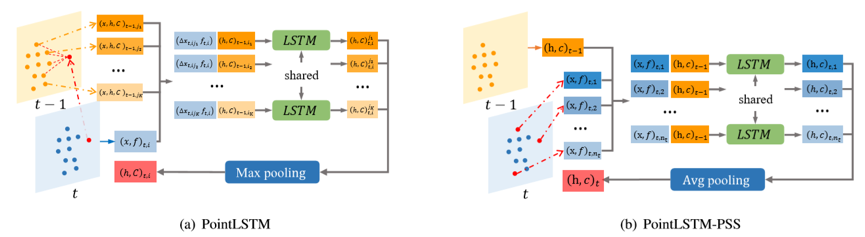
4. An Efficient PointLSTM Network for Point Clouds based Gesture Recognition (Yuecong Min, Yanxiao Zhang, Xiujuan Chai, Xilin Chen)
現有的手勢識別方法往往采用視頻或骨架點序列作為輸入,但手部在整張圖片中所占比例較小,基于視頻的方法往往受限于計算量并且更容易過擬合,而基于骨架點的方法依賴于獲取的手部骨架點的精度。
本文提出了一個基于點云序列的長短期記憶模塊 (PointLSTM),可以直接從手部點云序列中捕獲手型特征和手部運動軌跡。該模塊為點云序列中的每一個點保留了獨立的狀態,在更新當前點的狀態時,通過一個權值共享的LSTM融合時空相鄰點的狀態和當前點的特征,可以在保留點云空間結構的同時提取長時序的空間和時序信息。此外,本文還提出了一個幀內狀態共享的模塊(PointLSTM-PSS)用于簡化計算量和分析性能提升來源。我們在兩個手勢識別數據集 (NVGesture和SHREC’17) 和一個動作識別數據集 (MSR Action3D) 上驗證了方法的有效性和泛化能力,提出的模型在4096個點(32幀,每幀采樣128點)的規模下,優于目前最好的基于手部骨架點序列的手勢識別方法和基于點云序列的動作識別方法。
05
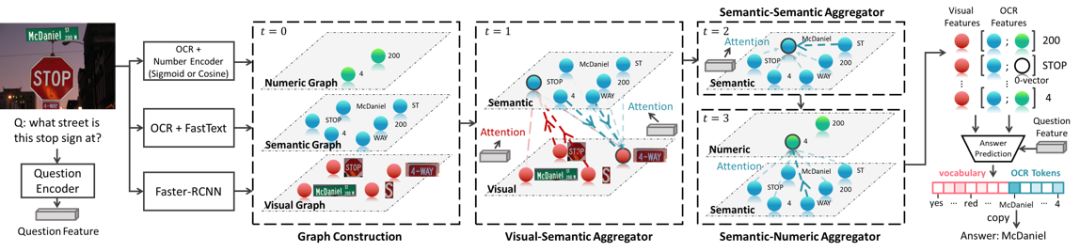
5. Multi-Modal Graph Neural Network for Joint Reasoning on Vision and Scene Text (Difei Gao, Ke li, Ruiping Wang, Shiguang Shan, Xilin Chen)
場景圖像中的文字通常會包含豐富的信息,比如,飯店的名字,產品的信息,等等。能夠理解這些場景文字,并回答與此相關的自然語言問題(即,場景文字問答任務,Text VQA)的智能體也將會有非常廣泛的應用前景。然而,對于當前的模型,場景文字問答任務仍十分具有挑戰。其關鍵的難點之一就是真實場景當中會出現大量的不常見的,多義的或有歧義的單詞,比如,產品的標簽,球隊的名稱等等。要想讓模型理解這些單詞的含義,僅僅訴諸于詞表有限的預訓練單詞嵌入表示(word embedding)是遠遠不夠的。一個理想的模型應該能夠根據場景中周圍豐富的多模態的信息推測出這些單詞的信息,比如,瓶子上顯著的單詞很有可能就是它的牌子。
根據這樣的思路,我們提出了一種新的視覺問答模型,多模態圖神經網絡(Multi-Modal Graph Neural Network,MM-GNN),它可以捕獲圖片當中各種模態的信息來推理出未知單詞的含義。具體來說,如下圖所示,我們的模型首先用三個不同模態的子圖來分別表示圖像中物體的視覺信息,文本的語言信息,以及數字型文本的數值信息。然后,我們引入三種圖網絡聚合器(aggregator),它們引導不同模態的消息從一個圖傳遞到另一個圖中,從而利用各個模態的上下文信息完善多模態圖中各個節點的特征表示。這些更新后的節點特征進而幫助后續的問答模塊。我們在近期提出的Text VQA和Scene Text VQA問答數據庫上進行了實驗,取得了state-of-the-art的性能,并驗證了方法的有效性。
06
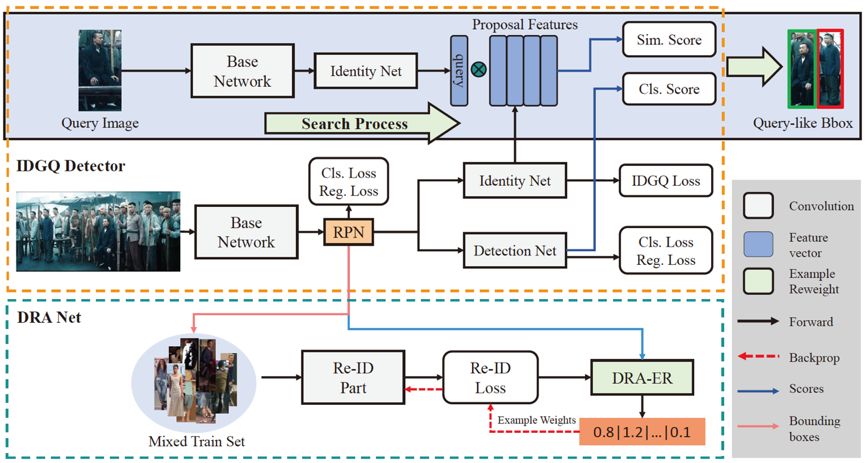
6. TCTS: A Task-Consistent Two-stage Framework for Person Search (Cheng Wang,Bingpeng Ma,Hong Chang, Shiguang Shan, Xilin Chen)
當前最先進的行人搜索方法將行人搜索分為檢測和再識別兩個階段,但他們大多忽略了這兩個階段之間的一致性問題。一般的行人檢測器對 query 目標沒有特別的關注;再識別模型是在手工標注的裁剪框上訓練的,在實際情況中是沒有這樣完美的檢測結果的。
為了解決一致性問題,我們引入了一個目標一致的兩階段的行人搜索框架 TCTS,包括一個 identity-guided query(IDGQ)檢測器和一個檢測結果自適應(Detection Results Adapted ,DRA)的再識別模型。在檢測階段,IDGQ 檢測器學習一個輔助的身份分支來計算建議框和查詢圖片的相似度得分。同時考慮查詢相似度得分和前景得分,IDGQ為行人再識別階段生成 query-like 的邊界框。在再識別階段,我們預測檢測輸出的 bounding boxes 對應的身份標簽,并用使用這些樣本為 DRA 模型構造一個更實用的混合訓練集。混合訓練提高了 DRA 模型對檢測不精確的魯棒性。我們在CUHK-SYSU和PRW這兩個基準數據集上評估了我們的方法。我們的框架在CUHK-SYSU上達到了93.9%的mAP和95.1%的rank1精度,超越以往最先進的方法。
07
7. Unsupervised Domain Adaptation with Hierarchical Gradient Synchronization (Lanqing Hu,Meina Kan, Shiguang Shan, Xilin Chen)
無監督領域自適應方法的任務是,將已標注的源域數據集上的知識遷移到無標注的目標域,從而減小對新目標域的標注代價。而源域和目標域之間的差異是這個問題的難點,大多方法通過對齊兩個域的特征的分布來減小域之間的差異,但是仍然很難做到兩個不同分布的每一個局部塊都完美對齊,從而保證判別信息的很好保留。
本文提出一種層級梯度同步的方法,首先在域、類別、類組三個級別通過對抗學習進行條件分布的對齊,然后通過約束不同級別的域判別器的梯度保證相同的方向和幅度,由此提高分布對齊的內在一致性,加強類別結構的保留,從而得到更準確的分類結果。該方法在當前主流測試集Office-31,Office-Home,VisDA-2017上的結果都驗證了其有效性。

-
算法
+關注
關注
23文章
4599瀏覽量
92643 -
計算機視覺
+關注
關注
8文章
1696瀏覽量
45927 -
數據集
+關注
關注
4文章
1205瀏覽量
24644
原文標題:CVPR2020 | 中科院VIPL實驗室錄取論文詳解
文章出處:【微信號:deeplearningclass,微信公眾號:深度學習大講堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
時空引導下的時間序列自監督學習框架

一種基于因果路徑的層次圖卷積注意力網絡

曙光公司成都云中心助力提升監督質效
一種創新的動態軌跡預測方法
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
旗晟機器人人員行為監督AI智慧算法

神經網絡如何用無監督算法訓練
深度學習中的無監督學習方法綜述
Meta發布新型無監督視頻預測模型“V-JEPA”
語言模型的弱監督視頻異常檢測方法

智慧消防在消防監督工作中的應用與發展
基于transformer和自監督學習的路面異常檢測方法分享

無監督域自適應場景:基于檢索增強的情境學習實現知識遷移

動態場景下的自監督單目深度估計方案





 工商網監
工商網監
評論