 對GraphQL APIs實現監控的步驟
對GraphQL APIs實現監控的步驟
作為REST的另一種選擇,GraphQL自2015年發布以來,為前端開發人員提供了他們渴望已久的靈活性。他們可以通過一次性查詢,來定義所有需要的數據,并能夠一次性地“打包”獲取,進而大幅減少了等待的時間。
除了簡化前端,REST也讓監控等方面變得更加簡單。據此,后端團隊可以考量每一個端點的狀態,并能夠及時地發現當前出現的問題。當然,在使用的過程中,我們需要考慮清楚的最關鍵問題是:如何使用GraphQL來準確地監控到目標系統的重要位置。下面,讓我們一起來討論那些有關GraphQL APIs監控的優秀實踐。
GraphQL架構
為了弄清楚上述問題件,讓我們首先來了解GraphQL的架構。通常,一個簡單的GraphQL系統會包括如下三個部分:
一種可定義所有數據類型的schema(結構模式)。
一個使用該schema將查詢到的每個部分都路由到某個解析器(resolver)的GraphQL引擎。
一到多個能夠被GraphQL引擎所調用的解析器。
通過解析schema,GraphQL后端會讓服務器了解到哪種解析器能夠處理哪種類型的查詢。也就是說,當一個查詢被發送到GraphQL端點時,GraphQL引擎會解析該查詢中的每一種請求類型,進而調用解析器來滿足其請求。可以想象,此類方法僅限于在與簡單查詢一起使用時,才能提供卓越的性能。
有時候,查詢的某些部分會被連接到同一個數據源(包括數據庫或第三方API等)。例如,如果我們加載某個用戶的賬號及其地址,它們可能在GraphQL的schema中具有兩種類型,而在數據源中卻只有一條記錄。那么我們同時發出請求的時候,當然不希望服務器對同一個數據源發出兩次查詢請求。
針對上述問題,業界會采用一種被稱為數據加載器(data-loader)的模式。該數據加載器是位于解析器和數據源之間的另一個GraphQL API層。通過簡單的設置,解析器將能夠直接訪問到數據源。而在更為復雜的迭代中,解析器則會告訴數據加載器它們到底需要什么,據此加載器也會針對該目的去訪問數據源。
那么,由此帶來的好處是:數據加載器可以持續等待,直到所有的解析器都已被調用,并且完成了對于數據源的訪問為止。針對上面提到的例子,如果有人想加載用戶的賬號和地址的話,那么只需對數據源發出一個請求便可。
可見,解析器只需了解其對應的需求,而數據加載器則需要知道所有解析器的目的,并據此來優化具體的訪問。
監控GraphQL
有了上面的理論基礎,我們就可以根據自己的架構,在如下多個位置監控GraphQL API了:
HTTP端點:針對那些影響到我們API的所有流量。
GraphQL查詢:針對每個特定的查詢。
GraphQL解析器或數據加載器:針對數據源的每個訪問。
全棧追蹤:針對每個查詢所影響到的解析器和數據加載器。
1. HTTP端點
在GraphQL架構中,通常只有一個HTTP端點,因此在該REST API級別上的監控,往往只能讓我們了解到有關API總體狀態的信息。
當然,這只是我們監控的一個起點。如果能夠提供低延遲、低錯誤率的全量信息,而且客戶端并無任何投訴產生的話,那么這些指標完全可以為我們節約后續花在深度監控上的大量時間和精力。但是,如果某個地方出現了問題,我們就需要更深入地進行探究了。
2. GraphQL查詢
下面,我們需要監控每一個查詢,當然主要針對的是那些靜態使用模式(static usage patterns)的API。
如果我們僅將API與自己的客戶端一起使用的話,那么針對固有查詢的變化一般不會經常發生。而如果我們的API需要處理不同客戶端的不同請求,那么查詢請求不但多,而且雜。這些只有細微差別的請求往往會拖慢整體的速度。而消除此類問題的一種做法是:檢查那些最常見的查詢,并對它們實施綜合監控。這就意味著我們需要事先定義一整套查詢和變量的組合,然后從測試客戶端運行之,以獲悉它們的用時。在此基礎上,我們能夠減少在更新時產生的,嚴重影響性能的風險因素。由于持久化查詢可以緩存那些最常用的查詢,因此我們可以用它來解決此類問題。
3. 解析器和數據加載器
如果我們能夠查看到后端所訪問的數據源位置,那么就能夠更好地獲悉如下方面:
是在訪問模式中使用了錯誤的數據源,還是需要改用其他類型的數據庫?
如果數據源類型沒問題的話,那么我們還需要改進對它們的請求方式嗎?我們是否需要添加數據加載器?
那些發送到外部API的請求是否太慢了?我們是否可以將數據復制到更接近后端的位置?
可見,只有當我們能夠看到后端具體查詢的是什么數據時,上述問題的答案才能迎刃而解。
正如我們在前面討論過的:解析器只能允許我們監控單個解析器的運作;而數據加載器使我們能夠在一個請求中查看到所有解析器的工作。那么,數據加載器的另一個附帶好處便是:我們能夠發現解析器之間的問題,并及時予以解決。
4. 全棧跟蹤
最為全面透徹的監控方式當屬:使用tracing-ID來標記查詢,將其傳遞給解析器以完成對該ID的解析,然后傳遞給數據加載器,并最終抵達數據源本身。據此,我們可以使用tracing-ID來記錄時間和錯誤,以便后續對其進行合并,以及了解局部狀態。
當然,在測量查詢時,我們所獲取到的有關解析用時的數據,實際上是數據被加載到解析器和/或數據加載器中進行的,而不是完成查詢解析的用時。畢竟,系統在加載數據時,已不再需要使用查詢了。這也就是GraphQL的核心思想之一:將查詢與實際數據的加載進行解耦(decoupling)。可見,我們通過全棧監控,可以全面地獲悉在發送查詢時,后臺究竟是如何運作的。
結論
總的說來,通過了解GraphQL API的后端結構,我們可以將REST API掛接到目標代碼的不同位置,進而清晰且全面地監控生產系統,以獲悉有關緩存和錯誤處理等方面的問題。
-
監控系統
+關注
關注
21文章
3860瀏覽量
173498 -
API
+關注
關注
2文章
1485瀏覽量
61817 -
GraphQL
+關注
關注
0文章
14瀏覽量
564
發布評論請先 登錄
相關推薦
LORA模塊如何實現遠程監控

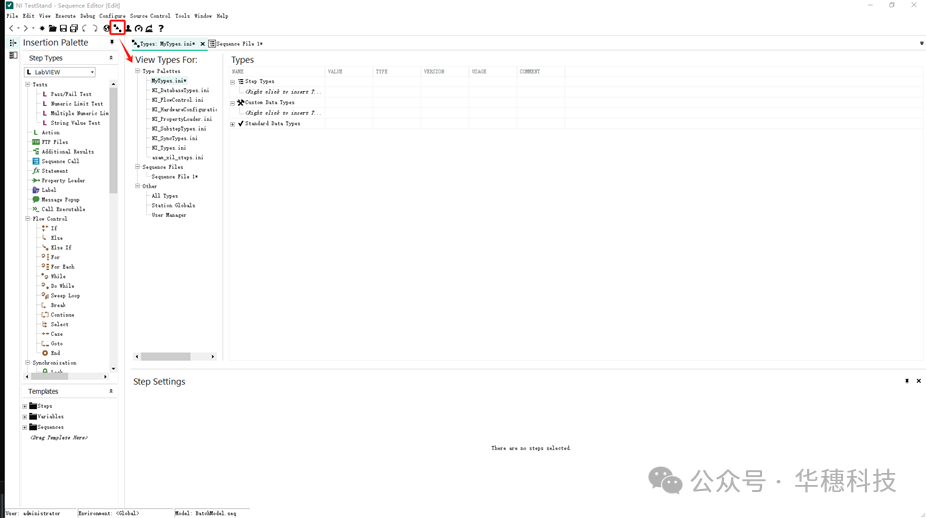
如何創建TestStand自定義步驟
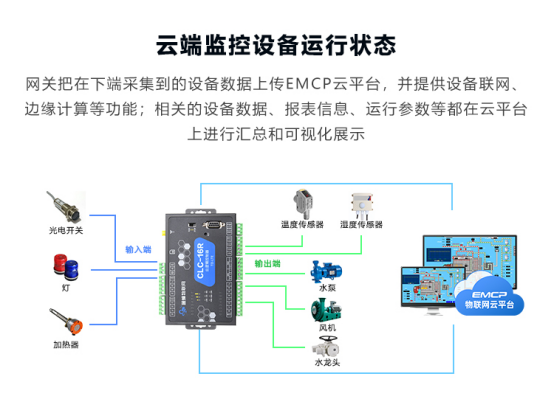
養豬管理如何實現遠程監控?
熔池監控相機的原理是什么
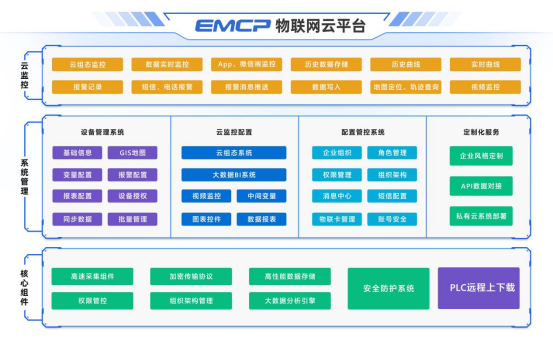
上位監控程序如何實現
水泥設備如何實現物聯網遠程監控?
淺談煤礦井下電力監控系統的應用
遠程監控PLC設備的作用
你的BurpSuite該更新了





 工商網監
工商網監
評論