 一文搞懂深度學習的精密率和召回率
一文搞懂深度學習的精密率和召回率
這里,我們將討論兩個重要的度量指標,即精度和召回率,它們被用于度量分類模型(即分類器)的性能。特別地,我們將討論如何用這兩個指標來評估決策樹模型。
一般來說,精確度度量針對的問題是“有多少選定的項目是相關的?”而召回率度量針對的問題是“有多少相關的項目被選中?”
精密率和召回率的定義
在定義精確度和召回率之前,我們首先需要澄清幾個概念。
假設我們有一個分類器來判斷一張圖片是否包含cat,目標標簽(class)有兩個值:[cat, non-cat]。分類器也會輸出兩個可能的值。例如,給定一組已標記的圖片,我們應用分類器為每幅圖片預測一個標簽。如下表所示,根據圖片實際標簽和預測標簽,有4種可能的情況。在許多文獻中,該表也稱為混淆矩陣。
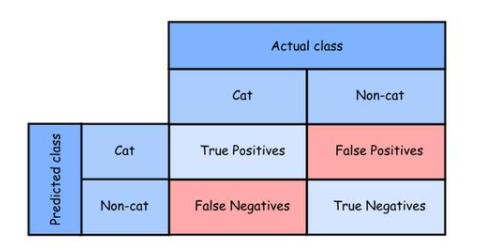
由于分類器的目的是預測圖片中是否有貓,所以當分類器以“cat”的形式給出預測結果時,我們稱預測結果為正,稱“not-cat”預測結果為負。我們將上表中的4種情況詳細說明如下:
True Positive (Tp)
對于一幅圖,如果預測的類別是正的(例如cat),而該圖的實際類別碰巧也是正的,則我們稱這種情況為真正
True Negative (Tn)
對于一個圖片,如果預測的類是負的(即not-cat),而實際的類碰巧也是負的,那么我們就稱這種情況為真負。
False Positive (Fp)
對于一幅圖,如果預測的類是正的(即cat),但該圖的實際類是負的(not-cat),則我們稱這種情況為假正。
False Negative (Fn)
對于一幅圖片,如果所預測的類別是否定的(即not-cat),但該圖片的實際類別是肯定的(即cat),則我們稱這種情況為假否定。
根據上述定義,我們現在可以定義精確度和召回率的度量。
精度(P)定義為真正(Tp)與所有是正預測(Tp+Fp)的比值,即真正的數與假正的數的比值。
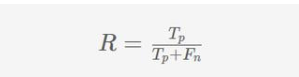
當分類器聲稱樣本為正時,我們可以將精度度量解釋為確定性。例如,一個標識符,如果Tp = Fp = 50,那么它的精度P = 50/(50 + 50) = 0.5 即我們可以說只要分類器聲稱,結果是正的,只有50%概率分類器實際上是正確的。
如果我們認為實際的正的項(樣本)是“相關的”,聲稱的正的項目是“被選擇的”,那么精度度量回答了多少被選擇的項目是相關的問題,正如文章開始所述的那樣。
召回率(R)定義為真正性(Tp)與所有正樣本(Tp+Fn)的比值,即真正的數量與假負的數量之和。
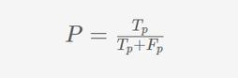
我們可以將召回度量解釋為分類器識別出的實際正性案例的百分比。例如,一個標識符,如果Tp = Fn = 50 ,然后召回率R = 50/(50 + 50) = 0.5,也就是說我們只能說分類器僅獲得50%實際正性案例的50%,而對另外50%的實際正案例進行了錯誤分類。
舉個例子
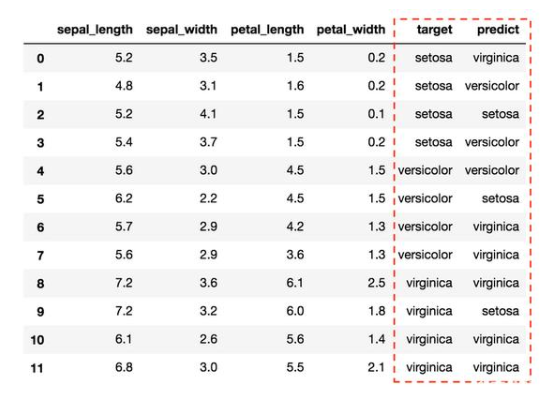
利用上述公式,我們可以得到每個標簽的精度和召回率,如下:
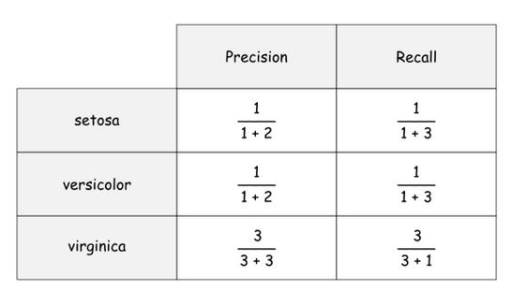
說明:我們以“setosa”這個標簽為例來說明詳細。對于“setosa”標簽,從第0行到第3行總共有4個實際正的樣本,模型給出了3個正預測(即在第2、5、9行),對于“setosa”標簽,只有一個真實正,位于第2行。setosa的假正位于第5行和第9行。最后,setosa的假負性為3例,分別位于第0、1、3行。
什么是準確度???
除了精確率和召回率之外,還有一個眾所周知的度量標準叫做準確度,它被用來衡量分類模型的性能。
準確性(A)定義為對所有預測(Tp+Tn+Fp+Fn)的真實結果(包括真正(Tp)和真負(Tn))的比例。
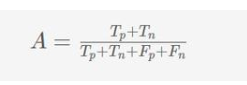
與精確率-召回率相比,準確率似乎是一種更加平衡的衡量標準,因為它同時考慮了真正的正因素和真正的負因素。然而,事實證明,準確性實際上是一個誤導的度量,特別是對于不平衡的數據集。例如,對于包含5封垃圾郵件(即正樣本)和95封普通郵件(即負樣本)的數據集,簡單地將所有樣本預測為負(非垃圾郵件)的低級的垃圾郵件分類器將獲得95%高精度。垃圾郵件分類器在使用精確率召回率度量時,其精確度和召回率為零,這更準確地反映了分類器的實際預測能力。因此,在實踐中,人們更喜歡精確率召回率來度量而不是準確度作為他們分類器的基準。
-
分類器
+關注
關注
0文章
152瀏覽量
13174 -
性能指標
+關注
關注
0文章
14瀏覽量
7894 -
深度學習
+關注
關注
73文章
5492瀏覽量
120977
發布評論請先 登錄
相關推薦


示波器的采樣率和示波器存儲深度
一文搞懂UPS主要內容
基于深度學習和3D圖像處理的精密加工件外觀缺陷檢測系統
如何估算深度神經網絡的最優學習率(附代碼教程)
數據外補償的深度網絡超分辨率重建

深度學習優化器方法及學習率衰減方式的詳細資料概述
AI垃圾分類的準確率和召回率達到99%
深度學習中的學習率調節實踐
什么是基于深度學習的超分辨率





 工商網監
工商網監
評論