 page struct的三種存放方式
page struct的三種存放方式
隨著硬件能力的提升,系統內存容量變得越來越大。尤其是在服務器上,過T級別的內存容量也已經不罕見了。
如此海量內存給內核帶來了很多挑戰,其中之一就是page struct存放在哪里。
page struct的三種存放方式
在內核中,我們將物理內存按照頁大小進行管理。這樣每個頁就對應一個page struct作為這個頁的管理數據結構。
隨著內存容量的增加,相對應的page struct也就增加。而這部分內存和其他的內存略有不同,因為這部分內存不能給到頁分配器。也就是必須在系統能夠正常運行起來之前就分配好。
在內核中我們可以看到,為了應對這樣的變化進化出了幾個不同的版本。有幸的是,這部分內容我們現在還能在代碼中直接看到,因為這個實現是通過內核配置來區分的。我們通過查找_pfn_to_page的定義就能發現一下幾種memory model:
CONFIG_FLATMEM
CONFIG_SPARSEMEM
CONFIGSPARSEMEMVMEMMAP
接下來讓小編給各位看官一一道來。
1) FLATMEM
在這種情況下,宏_pfn_to_page的定義是:
#define__pfn_to_page(pfn)(mem_map+((pfn)-ARCH_PFN_OFFSET))
而這個mem_map的定義是
structpage*mem_map;
所以在這種情況下,page struct就是一個大數組,所有的人都按照自己的物理地址有序得挨著。
2) SPARSEMEM
雖然第一種方式非常簡單直觀,但是有幾個非常大的缺點:
內存如果有空洞,那么中間可能會有巨大的page struct空間浪費
所有的page struct內存都在一個NUMA節點上,會耗盡某一個節點內存,甚至是分配失敗
且會產生夸NUMA訪問導致性能下降
所以第二種方式就是將內存按照一定粒度,如128M,劃分了section,每個section中有個成員指定了對應的page struct的存儲空間。
這樣就解決了上述的幾個問題:
如果有空洞,那么對應的 page struct就不會占用空間
每個section對應的page struct是屬于本地NUMA的
怎么樣,是不是覺得很完美。這一部分具體的實現可以可以看函數sparse_init()函數。
有了這個基礎知識,我們再來看這種情況下_pfn_to_page的定義:
#define __pfn_to_page(pfn) ({ unsigned long __pfn = (pfn); struct mem_section *__sec = __pfn_to_section(__pfn); __section_mem_map_addr(__sec) + __pfn; })
就是先找到pfn對應的section,然后在section中保存的地址上翻譯出對應pfn的page struct。
既然講到了這里,我們就要對sparsemem中重要的組成部分mem_section多說兩句。
先來一張mem_section的整體圖解:
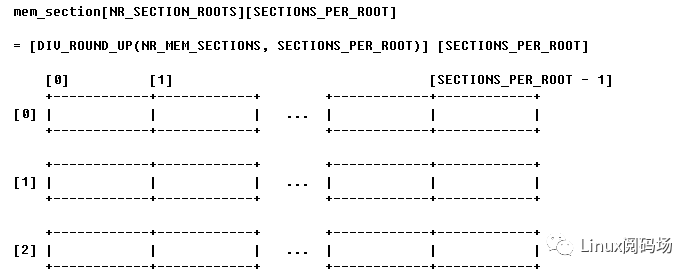
這是一個 NRSECTIONROOTS x SECTIONSPERROOT的二維數組。其中每一個成員就代表了我們剛才提到的128M內存。
當然最開始它不是這個樣子的。
其實最開始這個數組是一個靜態數組。很明顯這么做帶來的問題是這個數組定義太大太小都不合適。所以后來引進了CONFIGSPARSEMEMEXTREME編譯選項,當設置為y時,這個數組就變成了動態的。
如果上面這個算作是空間上的限制的話,那么接下來就是一個時間上的限制了。
在系統初始化時,每個mem_section都要和相應的內存空間關聯。在老版本上,這個步驟通過對整個數組接待完成。原來的版本上問題不大,因為整個數組的大小還沒有很大。但隨著內存容量的增加,這個數值就變得對系統有影響了。如果系統上確實有這么多內存,那么確實需要初始化也就忍了。但是在內存較小的系統上,哪怕沒有這么多內存,還是要挨個初始化,那就浪費了太多的時間。
commit c4e1be9ec1130fff4d691cdc0e0f9d666009f9aeAuthor: Dave Hansen
Dave在這個提交中增加了對系統最大存在內存的跟蹤,來減少不必要的初始化時間。
瞧,內核代碼一開始其實也沒有這么高大上不是。
3) SPARSEMEM_VMEMMAP
最后要講的,也是當前x86系統默認配置的內存模型是SPARSEMEM_VMEMMAP。那為什么要引入這么一個新的模型呢?那自然是sparsemem依然有不足。
細心的朋友可能已經注意到了,前兩種內存模型在做pfn到page struct轉換是有著一些些的差異。為了看得清,我們把這兩個定義再拿過來對比一下:
先看看FLATMEM時的定義:
#define__pfn_to_page(pfn)(mem_map+((pfn)-ARCH_PFN_OFFSET))
再來看看使用SPASEMEM后的定義:
#define __pfn_to_page(pfn) ({ unsigned long __pfn = (pfn); struct mem_section *__sec = __pfn_to_section(__pfn); __section_mem_map_addr(__sec) + __pfn; })
更改后,需要先找到section,然后再從section->memmap的內容中換算出page的地址。
不僅計算的內容多了,更重要的是還有一次訪問內存的操作
可以想象,訪問內存和單純計算之間的速度差異那是巨大的差距。
既然產生了這樣的問題,那有沒有辦法解決呢?其實說來簡單,內核開發者利用了我們常見的一個內存單元來解決這個問題。
頁表
是不是很簡單粗暴?如果我們能夠通過某種方式將page struct線性映射到頁表,這樣我們不就能又通過簡單的計算來換算物理地址和page struct了么?
內核開發者就是這么做的,我們先來看一眼最后那簡潔的代碼:
#define__pfn_to_page(pfn)(vmemmap+(pfn))
經過內核開發這的努力,物理地址到page struct的轉換又變成如此的簡潔。不需要訪問內存,所以速度的問題得到了解決。
但是天下沒有免費的午餐,世界哪有這么美好,魚和熊掌可以兼得的情況或許只有在夢境之中。為了達到如此簡潔的轉化,我們是要付出代價的。為了實現速度上的提升,我們付出了空間的代價。
至此引出了計算機界一個經典的話題:
時間和空間的轉換
話不多說,也不矯情了,我們來看看內核中實現的流程。
既然是利用了頁表進行轉換,那么自然是要構建頁表在做這樣的映射。這個步驟主要由函數vmemmap_populate()來完成,其中還區分了有沒有大頁的情況。我們以普通頁的映射為例,看看這個實現。
int __meminit vmemmap_populate_basepages(unsigned long start, unsigned long end, int node){ unsigned long addr = start; pgd_t *pgd; p4d_t *p4d; pud_t *pud; pmd_t *pmd; pte_t *pte; for (; addr < end; addr += PAGE_SIZE) { pgd = vmemmap_pgd_populate(addr, node); if (!pgd) return -ENOMEM; p4d = vmemmap_p4d_populate(pgd, addr, node); if (!p4d) return -ENOMEM; pud = vmemmap_pud_populate(p4d, addr, node); if (!pud) return -ENOMEM; pmd = vmemmap_pmd_populate(pud, addr, node); if (!pmd) return -ENOMEM; pte = vmemmap_pte_populate(pmd, addr, node); if (!pte) return -ENOMEM; vmemmap_verify(pte, node, addr, addr + PAGE_SIZE); } return 0;}
內核代碼的優美之處就在于,你可能不一定看懂了所有細節,但是從優美的結構上能猜到究竟做了些什么。上面這段代碼的工作就是對每一個頁,按照層級去填充頁表內容。其中具體的細節就不在這里展開了,相信有興趣的同學會自行去探索。
那這么做的代價究竟是多少呢?
以x86為例,每個section是128M,那么每個section的page struct正好是2M,也就是一個大頁。
(128M / 4K) * 64 = (128 * (1 < 20) / (1 < 12)) * 64 = 2M
假如使用大頁做頁表映射,那么每64G才用掉一個4K頁表做映射。
128M * 512 = 64G
所以在使用大頁映射的情況下,這個損耗的級別在百萬分之一。還是能夠容忍的。
好了,我們終于沿著內核發展的歷史重走了一遍安放page struct之路。相信大家在這一路上領略了代碼演進的樂趣,也會對以后自己代碼的設計有了更深的思考。
-
服務器
+關注
關注
12文章
9029瀏覽量
85205 -
數據結構
+關注
關注
3文章
573瀏覽量
40095 -
PAGE
+關注
關注
0文章
11瀏覽量
20173
原文標題:page結構體,何處安放你的靈魂?
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
systemd journal收集日志的三種方式

Windows管理內存的三種主要方式
typedef struct和直接struct的區別
計算機網絡中的三種通信方式
簡述斬波電路的三種控制方式
熱傳遞的三種方式是什么
介紹三種建模方式
通過TestStand三種主要運行方式探究TestStand開放式架構
自動控制的基本方式有三種是什么
分布式鎖的三種實現方式
伺服電機的三種控制方式 如何確定選擇伺服電機控制方式?
變頻器的三種控制方式 | 變頻器三種控制方式的優缺點






 工商網監
工商網監
評論