 彪悍的Graphcore第二代IPU!加速落地超大規模數據中心、金融、醫療健康等領域
彪悍的Graphcore第二代IPU!加速落地超大規模數據中心、金融、醫療健康等領域
電子發燒友網報道(文/黃晶晶)一家來自于英國的AI初創公司Graphcore,成立一年多時間里,融資超過4.5億美金,金融投資者包括紅杉資本、歐洲Atomico、以色列Pitango等,戰略投資者包括寶馬、Bosch、戴爾、微軟、三星等,受到資本的熱烈追捧。
最近,Graphcore發布第二代IPU芯片以及基于第二代IPU處理器的一系列的產品,性能對標市面上的主流產品。據了解,Graphcore IPU采用大規模并行同構眾核架構,其IPU Core是一個SMT多線程處理器,可以同時跑6個線程,類似多線程CPU,它與GPU的SIMD/SMIT架構不同。Graphcore IPU大量采用片上存儲SRAM,沒有外部DRAM。另外還采用了IPU-Fabric進行片間互聯。Graphcore第二代IPU芯片在SRAM存儲容量、計算吞吐量以及通信方面又有了大幅提升。
Graphcore第二代IPU三大顛覆性技術
Graphcore第二代IPU芯片Colossus Mk2 GC200采用臺積電7nm工藝。在計算、數據與通信方面實現了技術突破。無論與公司第一代IPU還是目前市面上主流的GPU相比,其性能表現突出。Graphcore高級副總裁、中國區總經理盧濤進行了詳細解析。
計算
Colossus Mk2 GC200處理器是目前世界上最復雜的單一處理器,基于臺積電7納米的技術,集成將近600億個晶體管,擁有250TFlops AI-Float的算力和900MB的處理器內存儲。處理器內核從上一代的1217提升到1472個獨立的處理器內核,這樣一個處理器有將近9000個單獨的并行線程。相對于第一代產品,其系統級的性能提升了8倍以上。
同時In-Processor-Memory從上一代的300MB提升到900MB。每個IPU的Memory帶寬是47.5TB/s。還包含了IPU-Exchange以及PCI Gen4跟主機交互的一個接口;另外有IPU-Links 320GB/s的芯片到芯片的互聯。
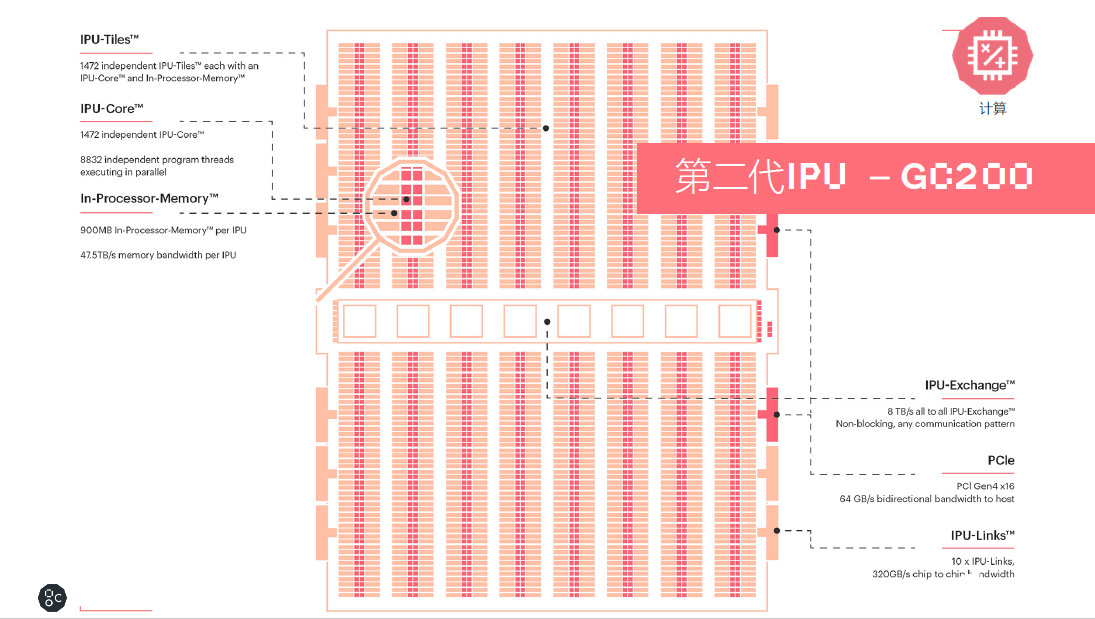
數據
IPU Exchange Memory是一個交換式存儲的概念。如果跟英偉達當前使用HBM技術的產品比較,Graphcore在M2000每個IPU-Machine里面通過IPU-Exchange-Memory技術,提供了將近超過100倍的帶寬以及大約10倍的容量,這對于很多復雜的AI模型算法是非常有幫助的。
通信
此次,Graphcore專門為AI橫向擴展設計了一個IPU-Fabric的結構。IPU-Fabric可以做到2.8Tbps超低延時,同時最多可以支持64000個IPU之間的橫向擴展。同時IPU-Fabric支持AI運算的集合通信或者all-reduce的操作,這也是Fabric的技術特性。
目前Graphcore有三種產品形態:一是IPU-Machine。二是IPU服務器,目前Graphcore已經在全球范圍內完成了浪潮和戴爾IPU服務器的產品適配。三是大規模橫向擴展的IPU-POD系統級產品。
IPU-MachineM2000是一個1U結構的即插即用的計算刀片,集成4個IPU Mk2GC200處理器,總共有1PFlops16.16的算力,和近6000個處理器的核心,以及超過35000個并行的線程,In-Processor Memory達到了3.6GB,Exchange Memory有450GB,以及2.8TbpsIPU-Fabric超低延時通信。非常易于部署,IPU-M2000可以滿足當前最苛刻的一些機器智能的工作負載。當前建議零售價是32,450美金。
IPU-M2000擁有多種配置形態,M2000是我們在構建超大規模的、彈性的AI計算集群中間的一個基本單元,可以從1個到4個、8個,到64個,最多可以到64000個,自由組合計算規模。
用于超算規模的IPU-POD,IPU-POD64是IPU-POD的一個基本組件,IPU-POD64總共支持了16個IPU-M2000,可以根據不同的工作負載進行不同的配置。另外,目前支持的2D-Torus拓撲,最大化IPU-Link的帶寬,全縮減(all-reduce)的效率比網狀拓撲的要快兩倍,這樣一個架構可以擴展到64000個GC200的IPU。
由于把AI的計算跟邏輯的控制進行了解耦,因此非常易于部署,網絡延時非常低,能夠支持大型的算法模型,以及安全的多用戶使用,
按64000個IPU集群計算,總共能提供16個EFlops FP16的算力,盧濤表示,日本前一陣發布的超算實現0.5 EFlops算力。而我們基于64000個IPU總共可以組建16個EFlops算力,這個是非常驚人的算力。
性能PK
IPU Mk2與Mk1進行對比,計算達到了兩倍以上的吞吐量峰值能力;數據方面,六倍以上的處理器內的有效存儲,超過了446GB的 IPU-Machine流存儲;通信方面,加入了基于大規模橫向擴展的IPU-Fabric的技術。
處理器內存儲從300MB到900MB,看起來是三倍的提升,但是片內存儲分為兩部分,程序占用的存儲空間以及供模型的激活、權重的存儲空間。因為對于程序代碼空間的占用情況在Mk1和Mk2是同樣的,這樣供算法模型可用的權重和激活容量有6倍以上的有效存儲。

Mk2與Mk1系統級的對比中,配備有IPU-Link的8個C2 PCIe的IPU服務器和Mk2配備有IPU-Fabric的8個IPU-M2000比較,在三個比較典型的應用場景,在BERT-Large訓練,MK2有9.3倍性能的提升。BERT三層推理,實現8. 5倍的性能提升。EfficientNet-B3這類計算機視覺應用模型,有7.4 倍的性能提升。
8個M2000與基于英偉達DGX-A100的整機(8個A100)對比中,后者FP32的計算能力是156TFlops,而8個M2000做到了2PFlops的算力,大約12倍的FP32性能的提升。對于AI計算,在GPU的平臺上是2.5PFlops,在M2000的平臺上是8PFlops,大約有三倍的提升。針對AI存儲部分,相對后者320GB,前面有3.6TB的存儲,將近10倍的提升。另外,從系統架構來說,花199K美金買到最新的GPU的算力和存儲空間,對于Graphcore的平臺,可能會花259k美金就能買到12倍的運算能力和10倍的存儲空間。
軟件與平臺生態
對于AI的落地應用,軟件生態可能比硬件更重要。Graphcore在提供高性能IPU芯片的同時,也在加速軟件和平臺生態的建設。
Graphcore 中國區技術應用總負責人羅旭介紹了Poplar軟件的最新版本特性。Poplar包括PopART和PopLibs,PopLibs相當于SDK,PopART相當于run time,通過PopART和PopLibs,連接到Poplar的compute graph,再通過graph compiler,相當于在整個處理器軟件跟硬件結合最緊密的地方轉成一個計算圖,然后把這個計算圖加載到對應的硬件,也就是IPU-Machine。
Poplar支持的算法框架包括PyTorch、TensorFlow、ONNX,mxnet,以及前段時間百度發布的PaddlePaddle。同一套軟件可以實現推理和訓練。

最新發布的SDK 1.2主要特性在于,與比較先進的機器學習框架做更好的集成;進一步開放低級別的API,上層的算法提供一個低層次的API接口,針對網絡的性能做一些特定的調優;增加框架支持,包括對PyTorch和Keras的支持。另外卷積庫和稀疏庫。PopART方面,可以做到多機的數據并行訓練。
羅旭還談到,我們把Exchange Memory也做了一些開放,包括API以及它的管理功能的開放。應用開發者可以基于Exchange Memory對模型的性能做極大程度的調優。
針對數據中心目前主流的操作系統ubuntu、RedHat、CentOS,現在Poplar SDK、drivers、工具鏈等也是完全支持的。
7月6號,PopLibs在GitHub上開源。用戶可以直接在GitHub上去搜索Graphcore下載對應鏈接。
Graphcore 在中國的首款IPU 開發者云部署在金山云之上,這里面使用了三種IPU產品,IPU-POD64,浪潮的IPU服務器NF5568M5,以及戴爾的IPU服務器DSS8440,目前這個是面向商業用戶進行評測以及面向高校研究機構,甚至個人開發者能夠提供免費的試用。
對于商業用戶來說,通常為三周或者按需適度延長,可以通用IPU極大優化現有模型,產品較競爭對手更早實現產品化和市場化。對大學、研究機構和個人研究者,可以提供6個月的免費訪問,直至完成研究項目并發表結果。
IPU與GPU不是競爭關系
盧濤認為,IPU是面向未來的另一大計算平臺,它與CPU、GPU不是競爭的關系,有交叉有不同。當前AI主流計算平臺仍是CPU和GPU,甚至一些算法也是基于GPU發展而來。Graphcore的愿景是畫第三個圓,我們認為CPU與GPU并沒有從根本意義上解決AI的問題。AI是一個面向計算圖的計算任務,跟CPU的標量計算以及GPU的矢量計算都不同。
從此,CPU、GPU、IPU有重疊相交的部分,必然會在某些領域進行競爭。例如,目前在NLP、CV這兩個領域的競爭會有一段膠著時期。但是未來會有更多IPU獨擋一面的應用,有待我們進行挖掘。
本文由電子發燒友網原創,未經授權禁止轉載。如需轉載,請添加微信號elecfans999。
-
數據中心
+關注
關注
16文章
4688瀏覽量
71956 -
IPU
+關注
關注
0文章
34瀏覽量
15549 -
AI芯片
+關注
關注
17文章
1859瀏覽量
34910
發布評論請先 登錄
相關推薦
寧德時代第二代鈉離子電池或將于2025年上市
拓展AI數據中心內存,第二代AMD Versal Premium系列自適應SoC,首發支持CXL 3.1、 PCIe Gen6

AMD推出第二代Versal Premium系列
一加正式發布第二代東方屏,獲全球首個DisplayMate A++認證
Zettabyte與緯創攜手打造臺灣首個超大規模AI數據中心
谷歌正在考慮在越南建設超大規模數據中心

有哪些技術影響超大規模數據中心建設
SAS 24G+規范發布,為超大規模數據中心HDD和SSD
燧原科技與清程極智攜手共創AI未來:共筑超大規模智算集群新篇章
Napatech IPU解決方案助力優化數據中心存儲工作負載
超大規模數據中心采用三星FDP SSD降低存儲成本





 工商網監
工商網監
評論