") Linux kernel同步機制及原子操作,自旋鎖,信號量和互斥鎖
Linux kernel同步機制及原子操作,自旋鎖,信號量和互斥鎖
在現(xiàn)代操作系統(tǒng)里,同一時間可能有多個內(nèi)核執(zhí)行流在執(zhí)行,因此內(nèi)核其實像多進程多線程編程一樣也需要一些同步機制來同步各執(zhí)行單元對共享數(shù)據(jù)的訪問,尤其是在多處理器系統(tǒng)上,更需要一些同步機制來同步不同處理器上的執(zhí)行單元對共享的數(shù)據(jù)的訪問。在主流的Linux內(nèi)核中包含了如下這些同步機制包括:
原子操作
信號量(semaphore)
讀寫信號量(rw_semaphore)
Spinlock
Mutex
BKL(Big Kernel Lock,只包含在2.4內(nèi)核中,不講)
Rwlock
brlock(只包含在2.4內(nèi)核中,不講)
RCU(只包含在2.6內(nèi)核及以后的版本中)
seqlock(只包含在2.6內(nèi)核及以后的版本中)
本文章分為兩部分,這一章我們主要討論原子操作,自旋鎖,信號量和互斥鎖。
一、原子操作
原子操作的概念來源于物理概念中的原子定義,指執(zhí)行結(jié)束前不可分割(即不可打斷)的操作,是最小的執(zhí)行單位。
原子操作與硬件架構(gòu)強相關(guān),其API具體的定義均位于對應(yīng)arch目錄下的include/asm/atomic.h文件中,通過匯編語言實現(xiàn),內(nèi)核源碼根目錄下的include/asm-generic/atomic.h則抽象封裝了API,該API最后分派的實現(xiàn)來自于arch目錄下對應(yīng)的代碼。
Structure Definition
typedefstruct{intcounter;}atomic_t;
原子操作主要用于實現(xiàn)資源計數(shù), 許多引用計數(shù)(refcnt)就是通過原子操作實現(xiàn),例如TCP/IP協(xié)議棧的IP碎片中,struct ipq中的refcnt字段,類型即為atomic_t。
atomic_add
原子操作的實現(xiàn)比較簡單,以下為例。
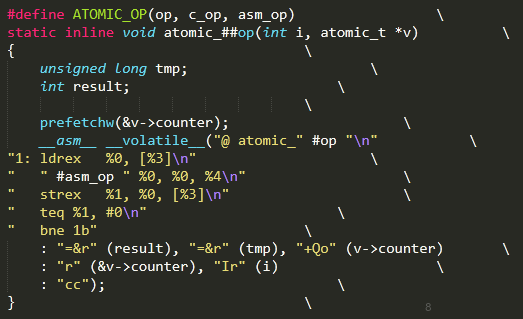
原子操作的原子性依賴于ldrex與strex實現(xiàn),ldrex讀取數(shù)據(jù)時會進行獨占標記,防止其他內(nèi)核路徑訪問,直至調(diào)用strex完成寫入后清除標記。自然strex也不能寫入被別的內(nèi)核路徑獨占的內(nèi)存,若是寫入失敗則循環(huán)至成功寫入。
API
原子操作的API包括如下, 以arm平臺為例:

二 、自旋鎖(spinlock)
自旋鎖是這樣一種同步機制:若自旋鎖已被別的執(zhí)行者保持,調(diào)用者就會原地循環(huán)等待并檢查該鎖的持有者是否已經(jīng)釋放鎖(即進入自旋狀態(tài)),若釋放則調(diào)用者開始持有該鎖。自旋鎖持有期間不可被搶占。
Structure Definition

從定義出發(fā), spinlock根本的實現(xiàn)依賴于具體架構(gòu)實現(xiàn)中slock這個變量,由于spin_lock是大多l(xiāng)ocking機制的基礎(chǔ),我們看一看它的實現(xiàn)。
Lock & Unlock

核心unlock函數(shù),使owner自增,保持數(shù)據(jù)同步。
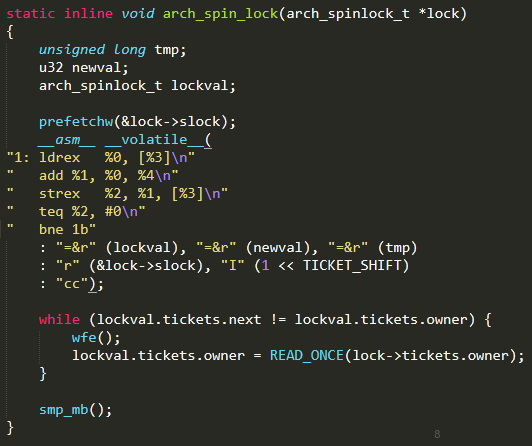
核心lock函數(shù),使slock +2^16, 當next==owner時,釋放鎖,否則進入循環(huán)等待。Prefetchw用于cache預(yù)加載數(shù)據(jù)。
由于slock與tickets共享同一塊內(nèi)存(union),slock 占32位4字節(jié),tickets內(nèi)部變量next與owner各16位2字節(jié)。以大端序為例,slock 高2字節(jié)與next共享,低2字節(jié)與owner共享,因此arch_spin_lock實際上是將tickets.next+1。假設(shè)初始時next與owner皆為0,此時next與owner不等,通過wfe指令進入一小段時間等待狀態(tài),而后讀取新的owner值檢查與next是否相等,不等則繼續(xù)等待,相等則結(jié)束等待。
而owner的值由arch_spin_unlock控制,即unlock控制何時結(jié)束等待。
Spin_lock basic API
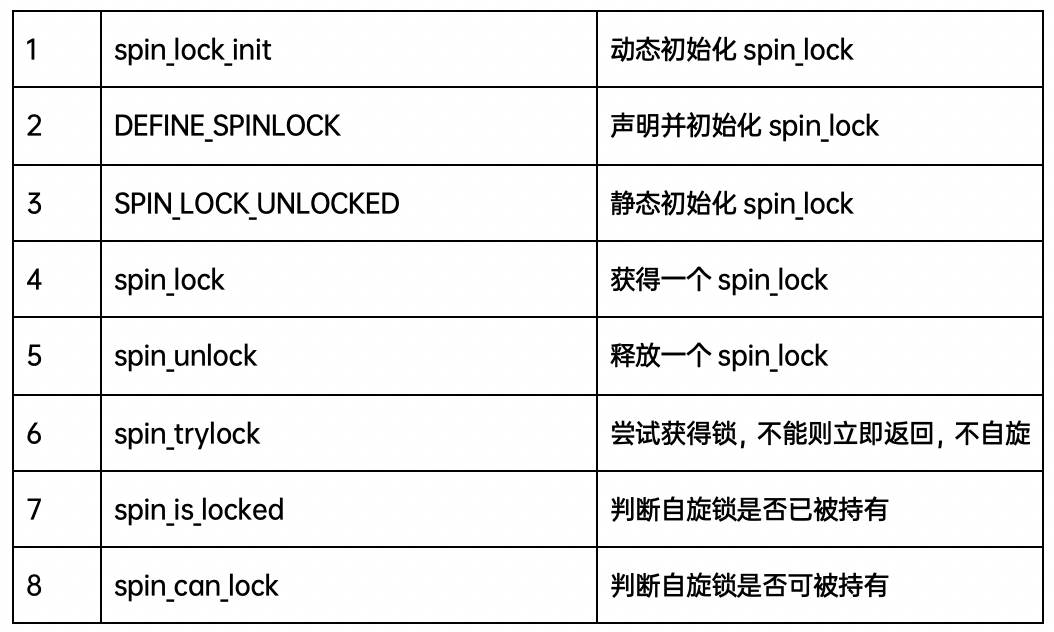
Spin_lock API & irq
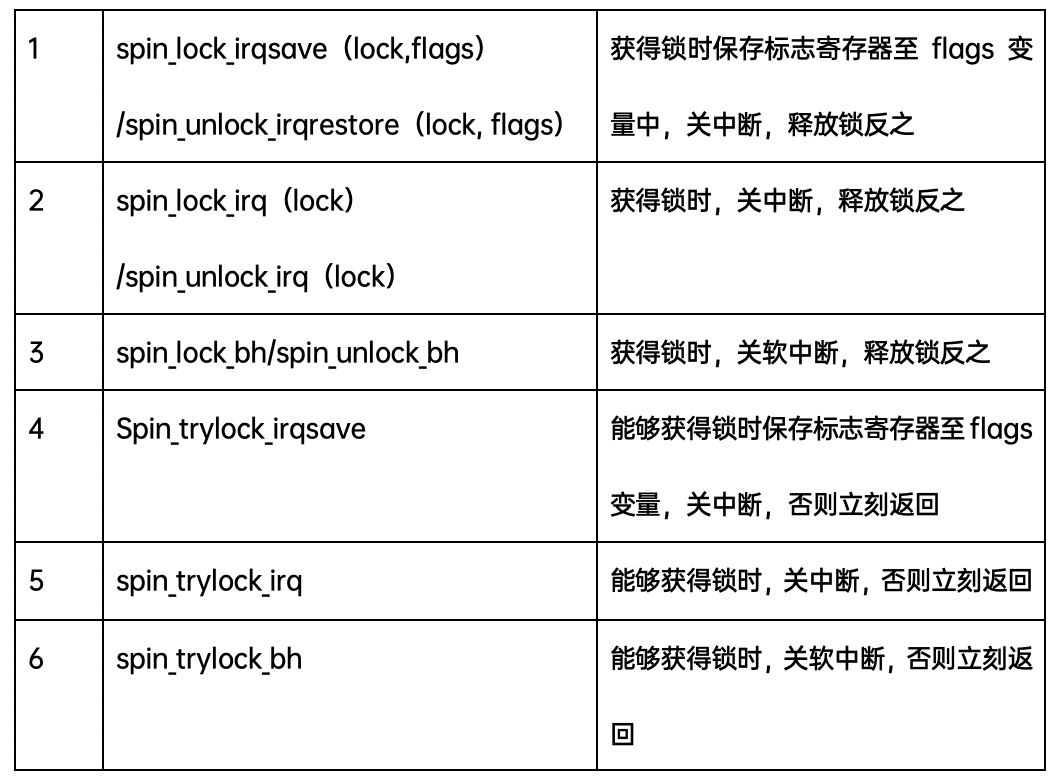
性能上,spin_lock > spin_lock_bh > spin_lock_irq > spin_lock_irqsave。
安全上,spin_lock_irqsave > spin_lock_irq > spin_lock_bh >spin_lock。
Spin_lock 不同版本的使用
spin_lock用于阻止在不同CPU上的執(zhí)行單元對共享資源的同時訪問以及不同進程上下文互相搶占導(dǎo)致的對共享資源的非同步訪問,而中斷失效(spin_lock_irq)和軟中斷失效(spin_lock_bh)卻是為了阻止在同一CPU上軟中斷或中斷對共享資源的非同步訪問。
如果被保護的共享資源只在進程上下文訪問和軟中斷上下文訪問,那么當在進程上下文訪問共享資源時,可能被軟中斷打斷,從而可能進入軟中斷上下文來對被保護的共享資源訪問,因此對于這種情況,對共享資源的訪問最好使用spin_lock_bh和spin_unlock_bh來保護。
如果被保護的共享資源只在進程上下文和tasklet或timer上下文訪問,那么應(yīng)該使用與上面情況相同,因為tasklet和timer是用軟中斷實現(xiàn)的。
如果被保護的共享資源只在兩個或多個tasklet或timer上下文訪問,那么對共享資源的訪問僅需要用spin_lock和spin_unlock來保護,不必使用_bh版本,因為當tasklet或timer運行時,不可能有其他tasklet或timer在當前CPU上運行。如果被保護的共享資源只在一個軟中斷(tasklet和timer除外)上下文訪問,那么這個共享資源需要用spin_lock和spin_unlock來保護,因為同樣的軟中斷可以同時在不同的CPU上運行。
如果被保護的共享資源在軟中斷(包括tasklet和timer)或進程上下文和硬中斷上下文訪問,那么在軟中斷或進程上下文訪問期間,可能被硬中斷打斷,從而進入硬中斷上下文對共享資源進行訪問,因此,在進程或軟中斷上下文需要使用spin_lock_irq和spin_unlock_irq來保護對共享資源的訪問。
在使用spin_lock_irq和spin_unlock_irq的情況下,完全可以用spin_lock_irqsave和spin_unlock_irqrestore取代,那具體應(yīng)該使用哪一個也需要依情況而定,如果可以確信在對共享資源訪問前中斷是使能的,那么使用spin_lock_irq更好一些,因為它比spin_lock_irqsave要快一些。
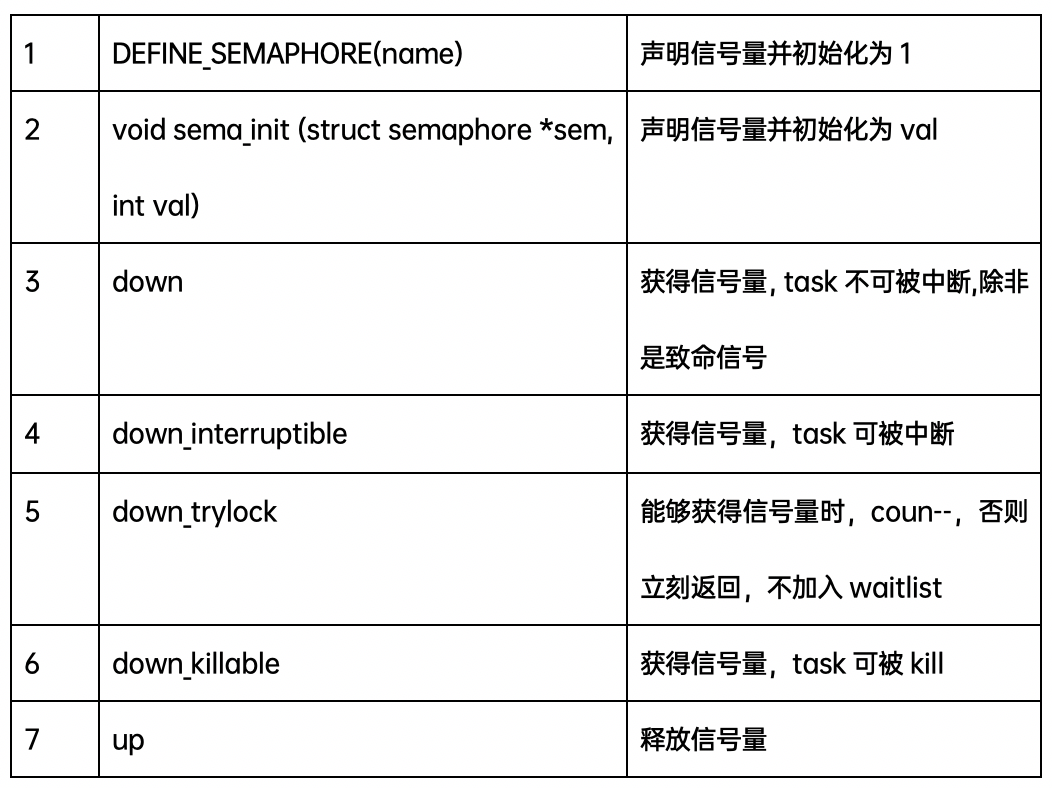
三、信號量(Semaphore)
Linux內(nèi)核的信號量在概念和原理上與用戶態(tài)的System V的IPC機制信號量是一樣的,但是它不可能在內(nèi)核之外使用,因此它與System V的IPC機制信號量完全不同。
信號量是這樣一種同步機制:信號量在創(chuàng)建時設(shè)置一個初始值count,用于表示當前可用的資源數(shù)。一個任務(wù)要想訪問共享資源,首先必須得到信號量,獲取信號量的操作為count-1,若當前count為負數(shù),表明無法獲得信號量,該任務(wù)必須掛起在該信號量的等待隊列等待;若當前count為非負數(shù),表示可獲得信號量,因而可立刻訪問被該信號量保護的共享資源。當任務(wù)訪問完被信號量保護的共享資源后,必須釋放信號量,釋放信號量通過把count+1實現(xiàn),如果count為非正數(shù),表明有任務(wù)等待,它也喚醒所有等待該信號量的任務(wù)。
Structure Definition

可以發(fā)現(xiàn),信號量是基于spinlock實現(xiàn)的,對其封裝以滿足高級的功能,例如全局共享資源的配置,并通過等待隊列較為靈活的調(diào)度。信號量與接下來要講的mutex都建立在自旋鎖實現(xiàn)的執(zhí)行同步上。
了解了信號量的結(jié)構(gòu)與定義,我們來看看最核心的兩個實現(xiàn)down ,up。
down & up

down用于調(diào)用者獲得信號量,若count大于0,說明資源可用,將其減一即可。

若count<0,將task加入等待隊列,并進入等待隊列,并進入調(diào)度循環(huán)等待,直至其被__up喚醒,或者因超時以被移除等待隊列。

up用于調(diào)用者釋放信號量,若waitlist為空,說明無等待任務(wù),count+1,該信號量可用。
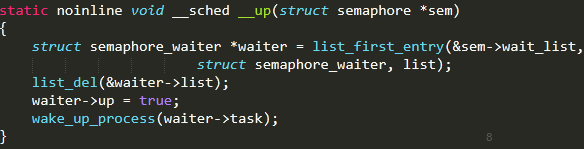
若waitlist非空,將task從等待隊列移除,并喚醒該task,對應(yīng)__down條件。
Semaphore API
四、互斥鎖(Mutex)
Linux 內(nèi)核互斥鎖是非常常用的同步機制,互斥鎖是這樣一種同步機制:在互斥鎖中同時只能有一個任務(wù)可以訪問該鎖保護的共享資源,且釋放鎖和獲得鎖的調(diào)用方必須一致。因此在互斥鎖中,除了對鎖本身進行同步,對調(diào)用方(或稱持有者)必須也進行同步。當互斥鎖無法獲得時,task會加入等待隊列,直至可獲得鎖為止。
Structure Definition

互斥鎖從結(jié)構(gòu)上看與信號量十分類似,但將原本的int類型的count計數(shù),改成了atomic_long_t的owner以便同步,保證釋放者與持有者一致。
mutex_lock & mutex_unlock
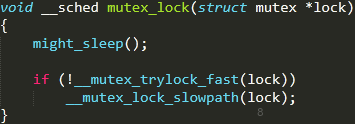

上圖簡單的表現(xiàn)了mutex_lock與mutex_unlock實現(xiàn)的對稱性,___mutex_trylock_fast用于owner為0的特殊狀態(tài),用于快速加鎖,實現(xiàn)核心在slowpath版本上。
*might_sleep指在之后的代碼執(zhí)行中可能會sleep。
由于mutex實現(xiàn)的具體步驟相當復(fù)雜,這里選講比較核心簡單的兩塊。Mutex有關(guān)等待隊列的處理比較復(fù)雜,有興趣閱讀相關(guān)內(nèi)核書籍。

當且僅當lock當前的owner沒有變化時(沒有其他mutex搶先擁有該鎖),此時獲得鎖,返回NULL, owner 為 curr | flags,owner本身對應(yīng)task指針。若該鎖已被占用,owner和當前task不匹配,返回owner對應(yīng)指針。
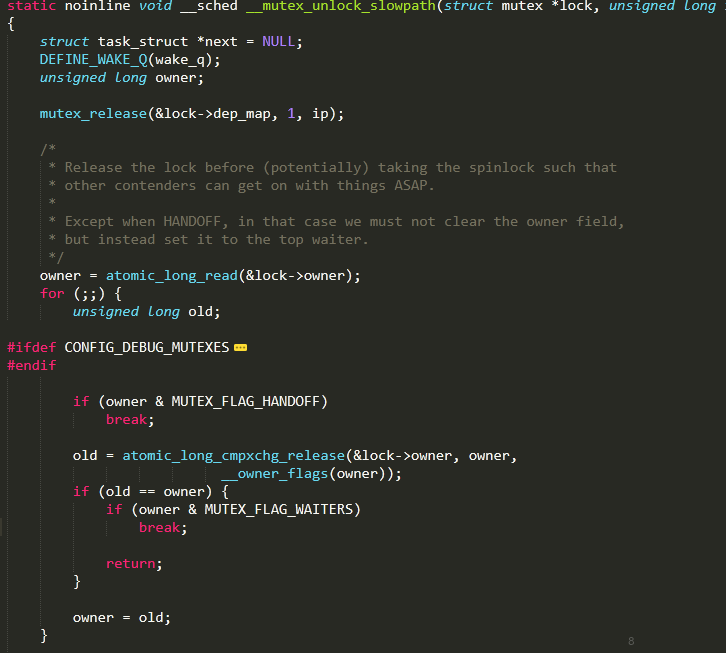
當unlock時,不考慮等待隊列的影響,則與上述類似,當且僅當之前持有鎖的owner可以解鎖,解鎖時本來應(yīng)將lock的owner置為初始0,但是這里保留了mutex的flag以便后續(xù)操作。
*這里的owner實際上是task_struct的指針,也就是地址,由于task_struct的地址是L1_cache對齊的,因此實際上指針地址后三位為0,因此linux內(nèi)核利用這三個比特位用于設(shè)置mutex的標志位,不影響指針地址的表示也更高效利用了冗余的比特位。
Mutex 的改進
最初的互斥鎖僅支持睡眠等待,然而經(jīng)過漫長時間的改進,如今的互斥鎖已經(jīng)可以支持自旋等待,通過MCS鎖機制實現(xiàn)。在內(nèi)核中可以選擇配置以支持,CONFIG_MUTEX_SPIN_ON_OWNER。

如上是4.9內(nèi)核中mutex中常用有效的字段,目前最常用的算法是OSQ算法。自旋等待機制的核心原理是當發(fā)現(xiàn)持有者正在臨界區(qū)執(zhí)行并且沒有其他優(yōu)先級高的進程要被調(diào)度(need_resched)時,那么mutex當前所在進程認為該持有者很快會離開臨界區(qū)并釋放鎖,此時mutex選擇自旋等待,短時間的自旋等待顯然比睡眠-喚醒開銷小一些。
在實現(xiàn)上MCS保證了同一時間只有一個進程自旋等待持有者釋放鎖。MCS 的實現(xiàn)較為復(fù)雜,具體可參考一些內(nèi)核書籍。MCS保證了不會存在多個cpu爭用鎖的情況,從而避免了多個CPU的cacheline顛簸從而降低系統(tǒng)性能的問題。
經(jīng)過改進后,mutex的性能有了相當大的提高,相對信號量的實現(xiàn)要高效得多。因此我們盡量選用mutex。
Mutex 的使用條件
Mutex雖然高效,靈活,但存在若干限制條件,需要牢記:
同一時刻只有一條內(nèi)核路徑可以持有鎖
只有鎖持有者可以解鎖
不允許遞歸加鎖解鎖
進程持有mutex時不可退出
Mutex 可能導(dǎo)致睡眠阻塞,不可用于中斷處理與下半部使用
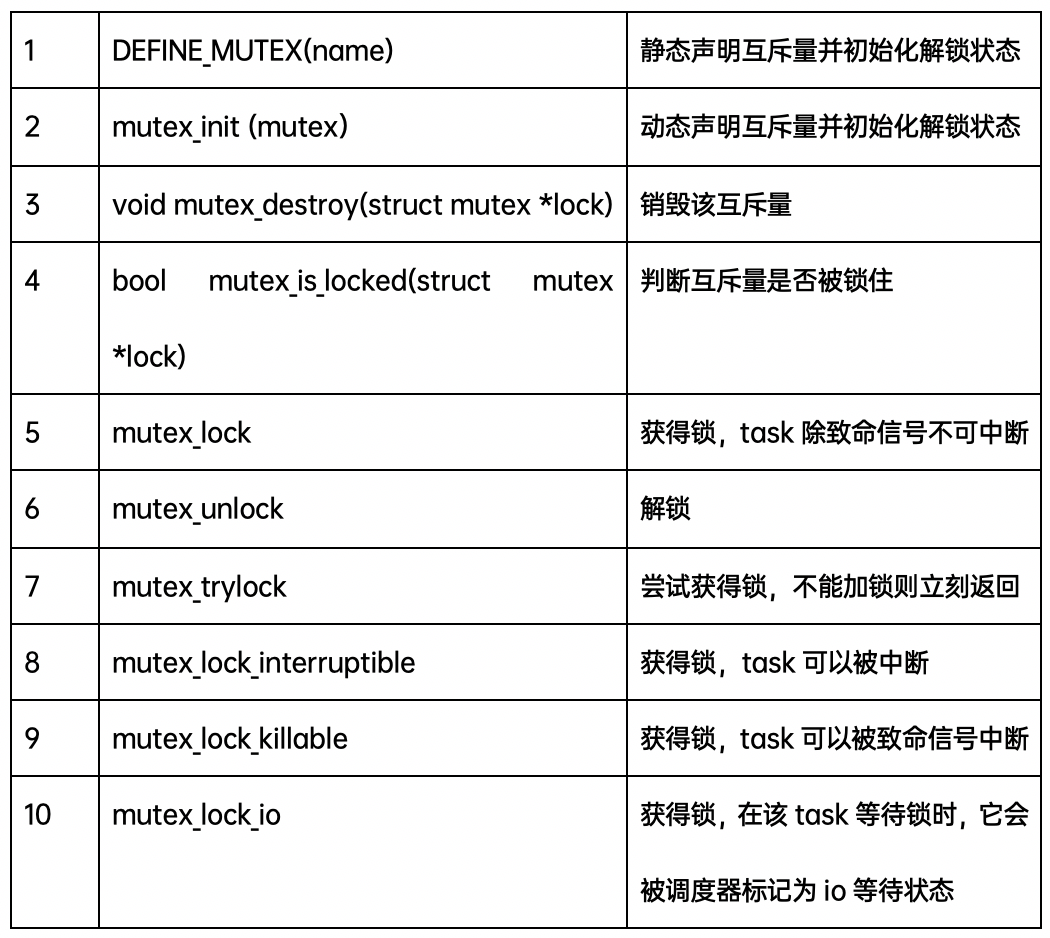
Mutex API
-
處理器
+關(guān)注
關(guān)注
68文章
19178瀏覽量
229201 -
Linux
+關(guān)注
關(guān)注
87文章
11232瀏覽量
208960 -
Kernel
+關(guān)注
關(guān)注
0文章
48瀏覽量
11140
原文標題:Linux kernel同步機制(上篇)
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
Linux驅(qū)動開發(fā)筆記-自旋鎖和信號量
信號量、互斥鎖、自旋鎖
芯靈思SinlinxA33開發(fā)板的Linux內(nèi)核信號量學習
Linux內(nèi)核同步機制的自旋鎖原理是什么?
Linux內(nèi)核同步機制的自旋鎖原理
可以了解并學習Linux 內(nèi)核的同步機制
信號量和自旋鎖
詳談Linux操作系統(tǒng)編程的互斥量mutex






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論