 企業級內存條的Memory ECC
企業級內存條的Memory ECC
我們今天來簡單討論一下企業級內存條的Memory ECC。

圖 (1)
圖(1)是一個帶有ECC的RDIMM,圖中我們已經將各個組件和關鍵的金手指信號區域標示出來。首先,我們來認識一下這幾個關鍵詞: Device:內存顆粒,根據其存放內容不同,又分為數據顆粒和ECC顆粒。通常有X4,X8和X16,代表每個顆粒對外的數據線路是4 lane,8 lane和16 lane。
Channel:一個Channel由一個或者多個Rank組成,其寬度由控制器決定。當前主流的個人電腦和服務器中,一個Channel的寬度為64bit,可根據內存控制器是否支持ECC而擴展額外的8bit。也就是說如果不支持ECC的Channel,其寬度為64bit,而支持ECC的Channel,其寬度為72bit。市面上兩種內存條都有銷售。
Rank:一個Channel里面,同一個CS(Chip Select)信號選中的所有Device就是一個Rank。同一個Rank中所有的Device共用命令,地址和控制信號。拿讀操作舉例,內存控制器發起的一個讀操作,其實將作用于該Channel的某個Rank中所有的Device。所有Device的數據線共同輸出達到內存控制器所需的寬度。例如,采用X4的顆粒,組成不帶ECC功能的一個Rank則需要64/4 = 16個X4的Device。大家可以計算一下如果采用X8或者X16寬度的顆粒,需要多少個呢?
注:本文我們將主要以X4的Device來討論
注:X16的顆粒一般不被用來組成帶ECC的Rank
Cacheline:Cacheline通常是指是處理器中Cache Unit(緩存模塊)緩存一筆數據的標準大小。根據處理器的不同,Cacheline的大小是不一樣的。當前主流的個人電腦和服務器中,Cacheline的大小為64 Byte。為了設計方便,處理器內部搬運可被緩存的數據也采用同樣的大小64B。為了滿足該需求,一個Rank被設計成了64bit的數據位寬,而JEDEC(DDR標準組織)設計了burst傳輸。一個Burst的長度可以是8,從而一次讀操作,可以讓顆粒一次吐出8筆數據。從而達到64bit X 8 = 64B的大小。具體參考圖(2)。

圖(2)
CE(CorrectableError):可糾正錯誤是指硬件(芯片)可以直接糾正的錯誤。由于內存控制器設計不一樣,對于可糾正錯誤的能力可能存在不同。例如,主流x86服務器的內存控制器(支持帶ECC的內存條),在一次讀操作中,一個X4寬度的Device內的任意錯誤都是可糾正的,包括ECC的Device。如果Rank是X8寬度的Device組成,其糾正能力還是與X4的Device寬度及位置保持一致。在X8的一個Device中,只有DQ0-3,或者DQ4-7可以被糾正。如果是DQ2-5,雖然是X4寬度但位置與X4時不對應,也無法糾正。
注:DQ0即D0,或者D0_0,DQ63則是D63,或者D15_3
UCE(Uncorrectable Error):不可糾正錯誤是指硬件(芯片)無法直接糾正的錯誤。例如,在一次讀操作中,錯誤數據位分布在不同X4的Device范圍,以現有內存控制設計來看,屬于不可糾正錯誤。
下面我們簡單介紹一下內存控制器是如何偵錯和糾錯的。由于ECC具體算法屬于各家的IP,這里介紹的方法只是幫助大家理解該功能。首先,內存控制器能夠糾錯,就必須先能發現錯誤。如果每次消費的數據大小是64B,在不增加額外信息的情況下,我們是無法知道該數據是否有改變的,因為64B的數據可以是任何01的組合,即任意數據都是合法的。另一方面,額外的信息需要額外的存儲,從成本考慮,這額外信息應該越小越好。JEDEC組織提出增加額外8 x 8 = 64bit的數據來幫助一個64B的數據完成ECC。 從物理角度看,一個X4 Device組成的Rank將會增加兩個Device用于ECC。一種可行的做法是,其中一個Device負責存放CRC(Cyclic Redundancy Check)校驗信息用于偵錯,另一個Device負責存放奇偶校驗信息(Parity),配合糾正錯誤。
Parity:Parity基本功能是發現保護數據中是否有bit翻轉。保護方法是統計保護數據中1的個數,如果是偶校驗,當保護數據中1的個數是偶數時,Parity為0,否則為1,所以Parity只需要一個bit就能發現保護數據中是否有一個bit的數據翻轉(0到1或者1到0)。當然對于奇數個bit都有一樣的檢測效果。但當偶數bit翻轉的時候,Parity將無法知道。在了解了Parity基本功能后,我們來看看內存控制器是如何計算Parity并存放的。如圖(3)所示。

圖(3)
Burst傳輸中每一筆64bit數據,4bit Parity和4bit CRC的具體對應關系如下: P0=D0_0+D1_0+D2_0+…D15_0+C0 P1=D0_1+D1_1+D2_1+…D15_1+C1 P2=D0_2+D1_2+D2_2+…D15_2+C2 P3=D0_3+D1_3+D2_3+…D15_3 +C3
注:D15_3為Device15的DQ3信號,從Rank角度看,為圖中的D63
假設Device 2 在Burst的第三筆數據中有bit翻轉,則無論是D2_0, D2_1, D2_2, D2_3 或者都錯了,請參考圖(4),我們都可以通過Parity bits反算回來,前提是burst的第三筆數據中其他Device沒有出現錯誤。具體計算如下:
D2_0=P0(-)(D0_0+D1_0+D3_0…D15_0+C0)
D2_1=P1(-)(D0_1+D1_1+D3_1…D15_1+C1)
D2_2=P2(-)(D0_2+D1_2+D3_2…D15_2+C2)
D2_3=P3(-)(D0_3+D1_3+D3_3…D15_3+C3)
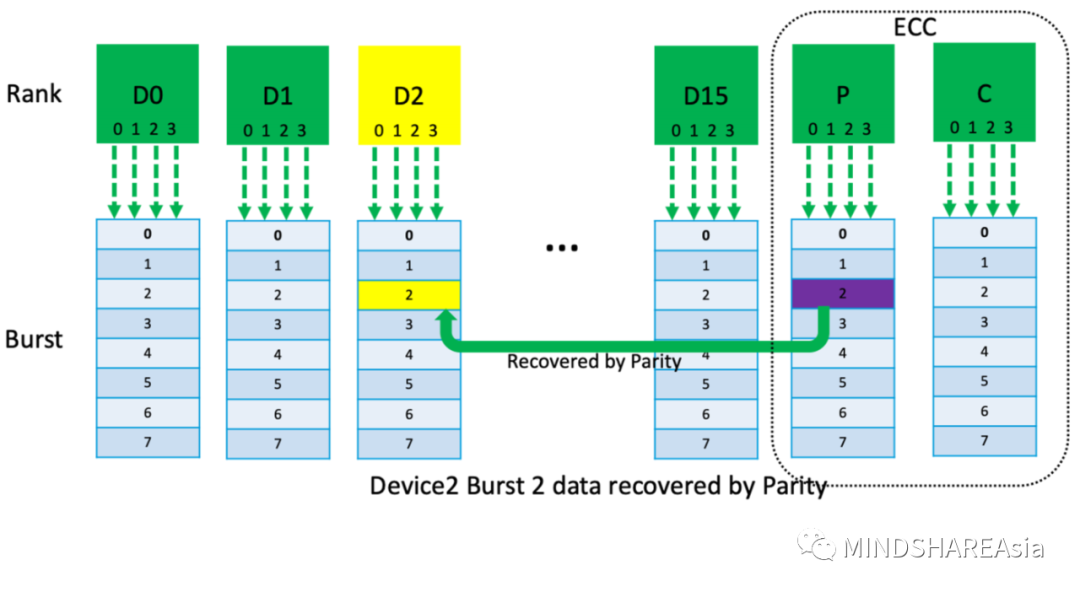
圖(4)
CRC:我們怎樣知道讀取的Cacheline數據是正確的還是錯誤的?這里將會用到CRC來進行校驗。一種比較簡單的校驗方式就是除法。我們設計一個除數,讓被保護數據(被除數)去除以這個除數,然后會得到商和余數。通常余數比設計的除數要小。在存儲一個Cacheline大小數據到內存條上的時候,內存控制器會計算CRC的值,并存放到CRC的Device中去。讀取的時候再計算一遍,然后和內存條讀回來的CRC的值進行比較。如果一致,則認為數據沒有發生變化。否則,認為數據出錯。 從上述理論可以推出,CRC校驗位越多,則偵錯能力越強。CRC設計不一樣,偵錯不同數據翻轉的能力不同。可能存在數據錯了,但偵錯不了的情況。 既然有漏測的情況,為什么我們還會繼續使用?這就和錯誤類型的概率有關了。通常情況下,一個bit翻轉的可能性比較高,多bit同時翻轉的可能性比較低。多bit翻轉在同一個device里的幾率比較高,多device同時翻轉的概率比較低。 舉個例子,當一個Cacheline的數據從內存條里讀出來后,通過CRC校驗,我們會發現數據有可能已經發生改變。這個時候,我們先假設出現了CE(Correctable Error)問題。則通過Parity信息反算Device數據,需要一個Device一個Device的假設,然后重新計算CRC和之前存儲的CRC進行比較。所以最多的情況可能要假設18次。 如果全部弄完仍然CRC對不上,則屬于UCE(Uncorrectable Error)問題啦。當然,大家會發現,ECC校驗過程會影響內存讀寫延時。
到這里,大家應該了解了Memory ECC的基本算法了,Parity針對的是每個Burst,CRC是以半個CacheLine或者其他大小為單位處理的。如果是跨Device的Error,真的無法糾錯嗎?如果有,請將你的實現方案發給我們吧,我們將在下期公布讀者的“可行”方案哦。
-
處理器
+關注
關注
68文章
19165瀏覽量
229130 -
服務器
+關注
關注
12文章
9021瀏覽量
85184 -
內存條
+關注
關注
0文章
143瀏覽量
19502
原文標題:真相!企業級內存條到底牛在哪兒?
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何選擇DDR內存條 DDR3與DDR4內存區別
佰維特存推出工業級ECC DDR4 SODIMM內存條,守護極端環境下的工業存儲需求

十銓科技推出首款工業級DDR5 6400MT/s內存條
金士頓發布FURY Renegade DDR5 CUDIMM內存條
金百達、精億、光威這三個品牌的內存條哪個好?
英睿達推出首批CUDIMM、CSODIMM內存條
電腦內存條的作用和功能
內存時鐘和內存條有什么不同
內存條接觸不良會導致哪些情況
卓越性能精億內存條赤龍銀甲系列DDR4 16G(8GX2) 3200 內存條測評 值得推薦價格親民質量過硬的國貨老牌
DDR5內存條上的時鐘走線

研華工控機購買指南:DDR3、DDR4、DDR5怎么選?如何選擇內存條?

服務器內存條和普通內存條的區別
企業級SSD-高性能系列固態硬盤推薦

詳解內存條和內存顆粒






 工商網監
工商網監
評論