 阿里達摩院斬獲AI相關6大權威冠軍,部分能力已超越人類
阿里達摩院斬獲AI相關6大權威冠軍,部分能力已超越人類
讓AI模仿人類的學習方式,結果會怎樣?
8月26日,阿里達摩院語言技術實驗室取得一系列突破,斬獲自然語言處理(NLP)領域6大權威技術榜單冠軍。據介紹,參與競賽的6項自研AI技術均采用模仿人類的學習模式,全方位提升了機器的語言理解能力,部分能力甚至已超越人類。目前,這些技術均已大規模應用于閱讀理解、機器翻譯、人機交互等場景。
據悉,過去幾年,AI在圖像識別、語音識別等方面已逐步超越人類水平,但在復雜文本語義的理解上,AI與人類尚有差距,其主要原因就是傳統AI學習文本知識效率較低。
為此,業界提出了一種模仿人類的學習思路,即先讓AI在大規模的網頁和書籍文字中進行訓練,學習基本的詞法、語法和語義知識,然后再在固定領域內的文本上進行訓練,學習領域專有知識。
這一思想就是預訓練語言模型的核心創新。自Google提出模仿人類注意力機制的BERT模型以來,預訓練語言模型已成為NLP領域的熱點研究方向。
達摩院早在2018年就開始布局通用的預訓練語言模型,并逐漸將該思路拓展到了多語言、多模態、結構化和篇章文本理解和文本生成領域,如今已建立一套系統化的深度語言模型體系,其自研通用語言模型StructBERT、多語言模型VECO、多模態語言模型StructVBERT、生成式語言模型PALM等6大自研模型分別刷新了世界紀錄。
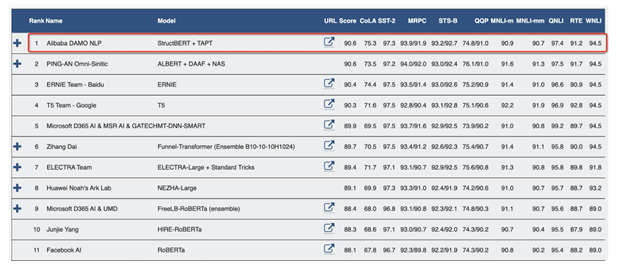
達摩院自研模型位居GLUE榜單第一名
其中,StructBERT能讓機器更好地掌握人類語法,使機器在面對語序錯亂或不符合語法習慣的詞句時,仍能準確理解并給出正確的表達和回應,大大提高機器對詞語、句子以及語言整體的理解力。該模型以平均分90.6分在自然語言處理領域權威數據集GLUE Benchmark中位居第一,顯著超越人類水平(87.1分)。
達摩院語言技術實驗室團隊表示:“實驗室的目標是讓AI掌握人類知識的基礎技術,預訓練語言模型的誕生使得AI像人一樣學習新知識成為可能,未來達摩院會全面對外開放這些技術,讓特定領域的AI變得更加智能。”
過去兩年,阿里獲得了30多項NLP領域頂級賽事世界冠軍,有100多篇相關頂會論文; 阿里自然語言技術已在金融、新零售、通訊、互聯網、醫療、電力、客服等領域服務超十億用戶和數萬企業客戶。
-
人機交互
+關注
關注
12文章
1200瀏覽量
55321 -
AI
+關注
關注
87文章
30146瀏覽量
268415 -
阿里達摩院
+關注
關注
0文章
29瀏覽量
3322
發布評論請先 登錄
相關推薦
亞馬遜推新,阿里達摩院退出,融資規模大幅下滑后量子計算還是好生意嗎?
阿里達摩院發布玄鐵R908 CPU
AI具備特定任務中接近甚至超越人類的心理狀態能力
阿里達摩院提出“知識鏈”框架,降低大模型幻覺
馬斯克預測明年或2026年AI將超越最聰明的人類
潤開鴻榮膺達摩院“玄鐵優選伙伴”獎
玄鐵RISC-V生態大會深圳召開,達摩院引領RISC-V創新應用







 工商網監
工商網監
評論