 一種針對該文本檢索任務的BERT算法方案DR-BERT
一種針對該文本檢索任務的BERT算法方案DR-BERT
基于微軟大規模真實場景數據的閱讀理解數據集MS MARCO,美團搜索與NLP中心提出了一種針對該文本檢索任務的BERT算法方案DR-BERT,該方案是第一個在官方評測指標MRR@10上突破0.4的模型。
本文系DR-BERT算法在文本檢索任務中的實踐分享,希望對從事檢索、排序相關研究的同學能夠有所啟發和幫助。
背景提高機器閱讀理解(MRC)能力以及開放領域問答(QA)能力是自然語言處理(NLP)領域的一大重要目標。在人工智能領域,很多突破性的進展都基于一些大型公開的數據集。比如在計算機視覺領域,基于對ImageNet數據集研發的物體分類模型已經超越了人類的表現。類似的,在語音識別領域,一些大型的語音數據庫,同樣使得了深度學習模型大幅提高了語音識別的能力。 近年來,為了提高模型的自然語言理解能力,越來越多的MRC和QA數據集開始涌現。但是,這些數據集或多或少存在一些缺陷,比如數據量不夠、依賴人工構造Query等。針對這些問題,微軟提出了一個基于大規模真實場景數據的閱讀理解數據集MS MARCO (Microsoft Machine Reading Comprehension)[1]。該數據集基于Bing搜索引擎和Cortana智能助手中的真實搜索查詢產生,包含100萬查詢,800萬文檔和18萬人工編輯的答案。 基于MS MARCO數據集,微軟提出了兩種不同的任務:一種是給定問題,檢索所有數據集中的文檔并進行排序,屬于文檔檢索和排序任務;另一種是根據問題和給定的相關文檔生成答案,屬于QA任務。在美團業務中,文檔檢索和排序算法在搜索、廣告、推薦等場景中都有著廣泛的應用。此外,直接在所有候選文檔上進行QA任務的時間消耗是無法接受的,QA任務必須依靠排序任務篩選出排名靠前的文檔,而排序算法的性能直接影響到QA任務的表現。基于上述原因,我們主要將精力放在基于MS MARCO的文檔檢索和排序任務上。 自2018年10月MACRO文檔排序任務發布后,迄今吸引了包括阿里巴巴達摩院、Facebook、微軟、卡內基梅隆大學、清華等多家企業和高校的參與。在美團的預訓練MT-BERT平臺[14]上,我們提出了一種針對該文本檢索任務的BERT算法方案,稱之為DR-BERT(Enhancing BERT-based Document Ranking Model with Task-adaptive Training and OOV Matching Method)。DR-BERT是第一個在官方評測指標MRR@10上突破0.4的模型,且在2020年5月21日(模型提交日)-8月12日期間位居榜首,主辦方也單獨發表推文表示了祝賀,如下圖1所示。DR-BERT模型的核心創新主要包括領域自適應的預訓練、兩階段模型精調及兩種OOV(Out of Vocabulary)匹配方法。
圖1 官方祝賀推文及MARCO 排行榜相關介紹Learning to Rank在信息檢索領域,早期就已經存在很多機器學習排序模型(Learning to Rank)用來解決文檔排序問題,包括LambdaRank[2]、AdaRank[3]等,這些模型依賴很多手工構造的特征。而隨著深度學習技術在機器學習領域的流行,研究人員提出了很多神經排序模型,比如DSSM[4]、KNRM[5]等。這些模型將問題和文檔的表示映射到連續的向量空間中,然后通過神經網絡來計算它們的相似度,從而避免了繁瑣的手工特征構建。
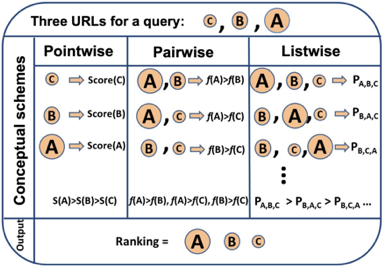
圖2 Pointwise、Pairwise、Listwise訓練的目標 根據學習目標的不同,排序模型大體可以分為Pointwise、Pairwise和Listwise。這三種方法的示意圖如上圖2所示。其中,Pointwise方法直接預測每個文檔和問題的相關分數,盡管這種方法很容易實現,然而對于排序來說,更重要的是學到不同文檔之間的排序關系。基于這種思想,Pairwise方法將排序問題轉換為對兩兩文檔的比較。具體來講,給定一個問題,每個文檔都會和其他的文檔兩兩比較,判斷該文檔是否優于其他文檔。這樣的話,模型就學習到了不同文檔之間的相對關系。 然而,Pairwise的排序任務存在兩個問題:第一,這種方法優化兩兩文檔的比較而非更多文檔的排序,跟文檔排序的目標不同;第二,隨機從文檔中抽取Pair容易造成訓練數據偏置的問題。為了彌補這些問題,Listwise方法將Pairwsie的思路加以延伸,直接學習排序之間的相互關系。根據使用的損失函數形式,研究人員提出了多種不同的Listwise模型。比如,ListNet[6]直接使用每個文檔的top-1概率分布作為排序列表,并使用交叉熵損失來優化。ListMLE[7]使用最大似然來優化。SoftRank[8]直接使用NDCG這種排序的度量指標來進行優化。大多數研究表明,相比于Pointwise和Pairwise方法,Listwise的學習方式能夠產生更好的排序結果。BERT自2018年谷歌的BERT[9]的提出以來,預訓練語言模型在自然語言處理領域取得了很大的成功,在多種NLP任務上取得了SOTA效果。BERT本質上是一個基于Transformer架構的編碼器,其取得成功的關鍵因素是利用多層Transoformer中的自注意力機制(Self-Attention)提取不同層次的語義特征,具有很強的語義表征能力。如圖3所示,BERT的訓練分為兩部分,一部分是基于大規模語料上的預訓練(Pre-training),一部分是在特定任務上的微調(Fine-tuning)。
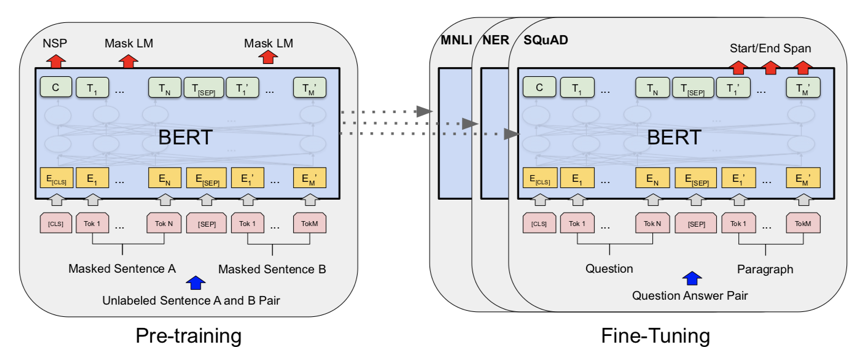
圖3 BERT的結構和訓練模式 在信息檢索領域,很多研究人員也開始使用BERT來完成排序任務。比如,[10][11]就使用BERT在MS MARCO上進行實驗,得到的結果大幅超越了當時最好的神經網絡排序模型。[10]使用了Pointwise學習方式,而[11]使用了Pairwise學習方式。這些工作雖然取得了不錯的效果,但是未利用到排序本身的比較信息。基于此,我們結合BERT本身的語義表征能力和Listwise排序,取得了很大的進步。模型介紹任務描述

基于DeepCT候選初篩由于MS MARCO中的數據量很大,直接使用深度神經網絡模型做Query和所有文檔的相關性計算會消耗大量的時間。因此,大部分的排序模型都會使用兩階段的排序方法。第一階段初步篩選出top-k的候選文檔,然后第二階段使用深度神經網絡對候選文檔進行精排。這里我們使用BM25算法來進行第一步的檢索,BM25常用的文檔表示方法包括TF-IDF等。 但是TF-IDF不能考慮每個詞的上下文語義。DeepCT[12]為了改進這種問題,首先使用BERT對文檔單獨進行編碼,然后輸出每個單詞的重要性程度分數。通過BERT強大的語義表征能力,可以很好衡量單詞在文檔中的重要性。如下圖4所示,顏色越深的單詞,其重要性越高。其中的“stomach”在第一個文檔中的重要性更高。

圖4 DeepCT估單詞的重要性,同一個詞在不同文檔中的重要性不同
DeepCT的訓練目標如下所示:
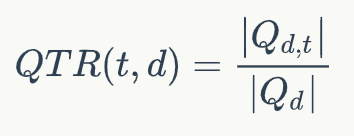
其中QTR(t,d)表示文檔d中單詞t的重要性分數,Qd表示和文檔d相關的問題,Q{d,t}表示文檔d對應的問題中包含單詞t的子集。輸出的分數可以當做詞頻(TF)使用,相當于對文檔的詞的重要性進行了重新估計,因此可以直接使用BM25算法進行檢索。我們使用DeepCT作為第一階段的檢索模型,得到top-k個文檔作為文檔候選集合D={D1,D2,...,Dk}。領域自適應預訓練由于我們的模型是基于BERT的,而BERT本身的預訓練使用的語料和當前的任務使用的語料并不是同一個領域。我們得出這個結論是基于對兩部分語料中top-10000高頻詞的分析,我們發現MARCO的top-10000高頻詞和BERT基線使用的語料有超過40%的差異。因此,我們有必要使用當前領域的語料對BERT進行預訓練。由于MS MARCO屬于大規模語料,我們可以直接使用該數據集中的文檔內容對BERT進行預訓練。我們在第一階段使用MLM和NSP預訓練目標函數在MS MARCO上進行預訓練。兩階段精調
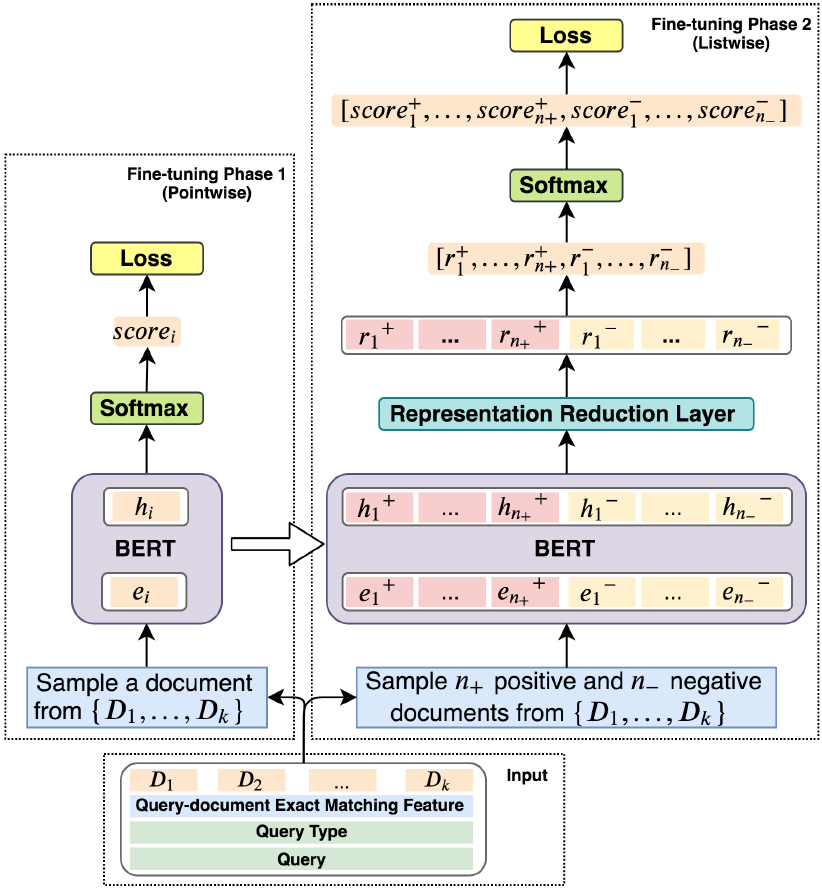
圖5 模型結構 下面介紹我們提出的精調模型,上圖5展示了我們提出的模型的結構。精調分為兩個階段:Pointwise精調和Listwise精調。Pointwise問題類型感知的精調
第一階段的精調,我們的目標是通過Pointwise的訓練方式建立問題和文檔的關系。我們將Query-Document作為輸入,使用BERT對其編碼,匹配問題和文檔。考慮到問題和文檔的匹配模式和問題的類型有很大的關系,我們認為在該階段還需要考慮問題的類型。因此,我們使用問題,問題類型和文檔一起通過BERT進行編碼,得到一個深層交互的語義表示。具體的,我們將問題類型T、問題Q和第i個文檔Di拼接成一個序列輸入,如下式所示:

其中

經過BERT編碼后,我們取最后一層中
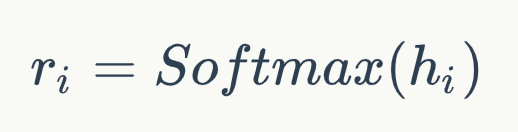
該分數Ti通過交叉熵損失函數進行優化。通過以上的預訓練,模型對不同的問題學到了不同的匹配模式。該階段的預訓練可以稱為類型自適應(Type-Adaptive)模型精調。Listwise 精調為了使得模型直接學習不同排序的比較關系,我們通過Listwise的方式對模型進行精調。具體的,在訓練過程中,對于每個問題,我們采樣n+個正例以及n-個負例作為輸入,這些文檔是從候選文檔集合D中隨機產生。注意,由于硬件的限制,我們不能將所有的候選文檔都輸入到當前模型中。因此我們選擇了隨機采樣的方式來進行訓練。
和預訓練中使用BERT的方式類似,我們得到正例和負例中每個文檔的表示,hi+和hi-。然后通過一個單層感知機將上面得到的表示降維并轉換成一個分數,即:
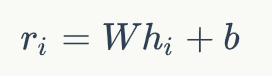
其中W和b是模型中可學習的參數。接下來對于每個文檔的分數,我們通過一個文檔級別的比較和歸一化得到:
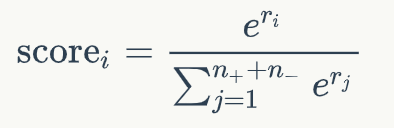
這一步,我們將文檔中的正例的分數和負例的分數進行比較,得到Listwise的排名分數。我通過這一步,我們得到了一個文檔排序列表,我們可以將文檔排序的優化轉化為最大化正例的分數。因此,模型可以通過負對數似然損失優化,如下式所示:
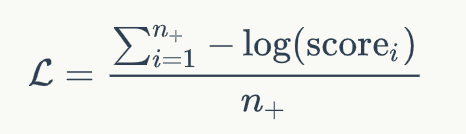
至于為什么使用兩個階段的精調模型,主要出于如下兩點考慮:
1. 我們發現首先學習問題和文檔的相關性特征然后學習排序的特征相比,直接學習排序特征效果好。
2. MARCO是標注不充分的數據集合。換句話說,許多和問題相關的文檔未被標注為1,這些噪聲容易造成模型過擬合。第一階段的模型可以用來過濾訓練數據中的噪聲,從而可以有更好的數據監督第二階段的精調模型。解決OOV的錯誤匹配問題在BERT中,為了減少詞表的規模以及解決Out-of-vocabulary(OOV)的問題,使用了WordPiece方法來分詞。WordPiece會把不在詞表里的詞,即OOV詞拆分成片段,如圖6所示,原始的問題中包含詞“bogue”,而文檔中包含詞“bogus”。在WordPiece方法下,將“bogue”切分成”bog”和“##ue”,并且將“bogus”切分成”bog”和“##us”。我們發現,“bogus”和“bogue”是不相關的兩個詞,但是由于WordPiece切分出了匹配的片段“bog”,導致兩者的相關性計算分數比較高。

圖6 BERT WordPiece處理前/后的文本 為了解決這個問題,我們提出了一種是對原始詞(WordPiece切詞之前)做精準匹配的特征。所謂“精確匹配”,指的是某個詞在文檔和問題中同時出現。精準匹配是信息檢索和機器閱讀理解中非常重要的一個技術。根據以往的研究,很多閱讀理解模型加入該特征之后都可以有一定的效果提升。具體的,在Fine-tuning階段,我們對于每個詞構造了一個精準匹配特征,該特征表示該單詞是否出現在問題以及文檔中。在編碼階段之前,我們就將這個特征映射到一個向量,和原本的Embedding進行組合:

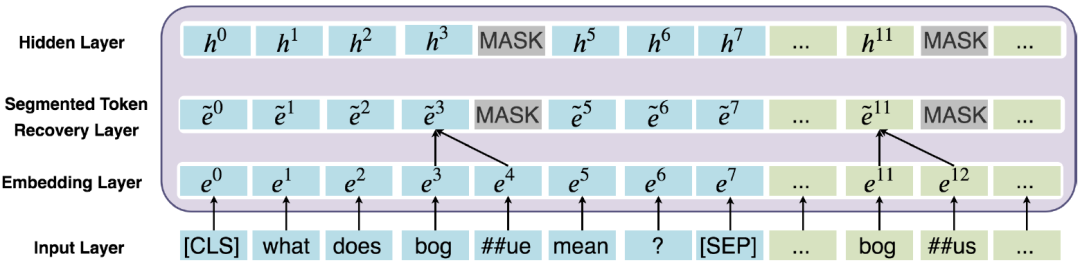
圖7 詞還原機制的工作原理 除此之外,我們還提出了一種詞還原機制如圖7所示,詞還原機制能夠將WordPiece切分的Subtoken的表示合并,從而能更好地解決OOV錯誤匹配的問題。具體來說,我們使用Average Pooling對Subtoken的表示合并作為隱層的輸入。除此之外,如上圖7所示,我們使用了MASK處理Subtoken對應的非首位的隱層位置。值得注意的是,詞還原機制也能很好地避免模型的過擬合問題。這是因為MARCO的集合標注是比較稀疏的,換句話說,有很多正例未被標注為1,因此容易導致模型過擬合這些負樣本。詞還原機制一定程度上起到了Dropout的作用。總結與展望以上內容就對我們提出的DR-BERT模型進行了詳細的介紹。我們提出的DR-BERT模型主要采用了任務自適應預訓練以及兩階段模型精調訓練。除此之外,還提出了詞還原機制和精確匹配特征提高OOV詞的匹配效果。通過在大規模數據集MS MARCO的實驗,充分驗證了該模型的優越性,希望這些能對大家有所幫助或者啟發。
-
微軟
+關注
關注
4文章
6572瀏覽量
103963 -
算法
+關注
關注
23文章
4601瀏覽量
92673 -
數據集
+關注
關注
4文章
1205瀏覽量
24649
原文標題:MT-BERT在文本檢索任務中的實踐
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
內置誤碼率測試儀(BERT)和采樣示波器一體化測試儀器安立MP2110A

M8020A J-BERT 高性能比特誤碼率測試儀
AWG和BERT常見問題解答
llm模型本地部署有用嗎
llm模型有哪些格式
llm模型和chatGPT的區別
自然語言處理是什么技術的一種應用
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
檢索增強生成(RAG)如何助力企業為各種企業用例創建高質量的內容?
斯坦福繼Flash Attention V1和V2又推出Flash Decoding
谷歌模型訓練軟件有哪些功能和作用
教您如何精調出自己的領域大模型

大語言模型背后的Transformer,與CNN和RNN有何不同






 工商網監
工商網監
評論