 三篇ACL2020論文即圍繞謠言判別中的可解釋性
三篇ACL2020論文即圍繞謠言判別中的可解釋性
引言
謠言始終與人類社會的發展形影相隨,隨著互聯網的發展和網上言論的開放,虛假的、未經證實的信息極易在社交網絡平臺上廣泛傳播,帶來不良社會影響。目前,網絡謠言常被定義為“廣泛流傳的、真實性受到質疑的、表面上可信但極具迷惑性難以辨別真偽的信息”(Zubiaga, 2018)。
對網絡謠言真實性進行判別是較為復雜的系統性任務,可粗粒度分為謠言檢測(rumor detection)、立場分類(stance classification)、謠言判別(rumor verification)流程式子任務。同時社交網絡中可追蹤的文本內容、用戶特征、信息傳播軌跡,為謠言檢測及真偽性判別提供了豐富的信息來源和建模思路,這也使得端到端的謠言判別更具挑戰。
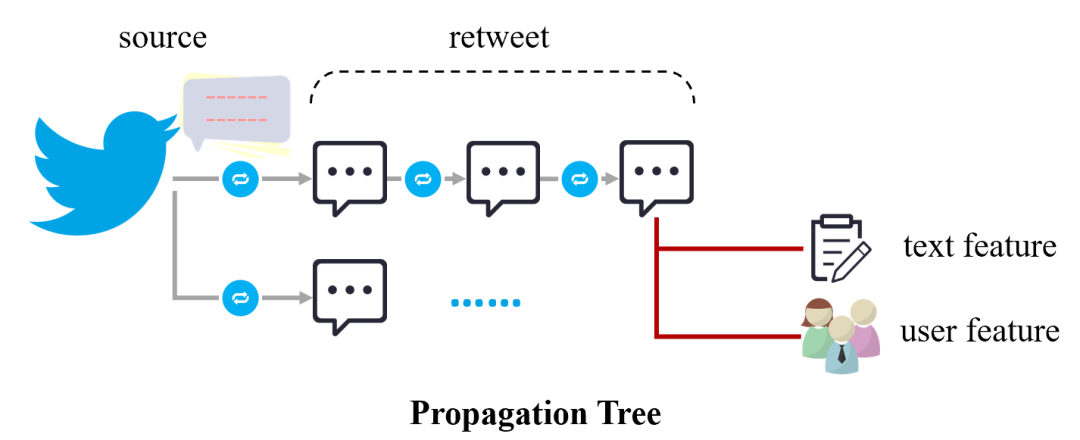
網絡謠言形成的信息傳播樹及特征來源
早期,學者們多采用從文本、用戶、傳播等方面提取特征的思路,盡可能的刻畫謠言傳播形態。隨著深度學習的發展,更具泛化性的文本表示方法(如詞向量、預訓練模型),更適配于消息傳播的信息整合模型(如基于消息發布時間的序列化模型、基于信息傳播軌跡的樹結構/圖結構模型),更簡便的子任務協同訓練框架(如多任務學習),使得神經網絡模型在謠言判別上的性能不斷提升。
然而,隨著深度模型復雜度增加,模型內部的決策過程卻愈加難以解釋和驗證,也對謠言判別的實際應用推廣帶來了限制。本次DISC小編分享的三篇ACL2020論文即圍繞謠言判別中的可解釋性,介紹網絡謠言傳播中易感用戶及話題挖掘、判別線索取證、數據及模型不確定性衡量的相關工作。
文章概覽
基于圖網絡和協同注意力機制的用于可解釋社交媒體虛假新聞檢測的模型(Graph-aware Co-Attention Networks for Explainable Fake News Detection on Social Media)
論文地址:https://www.aclweb.org/anthology/2020.acl-main.48.pdf
該篇文章延續了謠言判別中的傳統思路,盡可能準確的刻畫謠言的傳播模式。主要圍繞信源文本和參與傳播用戶的特征進行建模,并借助協同注意力機制捕捉信源文本中的敏感話題以及傳播過程中可疑度的用戶。
基于決策樹和協同注意力機制的可解釋的謠言判別的模型(Decision Tree-based Co-Attention Networks for Explainable Claim Verification)
論文地址:https://www.aclweb.org/anthology/2020.acl-main.97.pdf
該篇文章秉持謠言傳播中具有“自證性”,即假消息的相關評論或轉發中會出現對其真實性進行佐證的內容。通過決策樹篩選出可作為判別線索的消息,接著借助協同注意力機制探索信源文本與相關線索的交互關系,由此可呈現出模型在篩選佐證時的決策過程和更細粒度的關鍵文本和話題。
評估謠言判別模型中的預測不確定性(Estimating Predictive Uncertainty for Rumour Verification Models)
論文地址:https://www.aclweb.org/anthology/2020.acl-main.623.pdf
該篇文章立足于謠言判別的實際應用場景,認為訓練完好的模型在面對突發謠言事件依然面對跨領域遷移的挑戰,大部分現有模型泛化能力都較差,因此借助不確定性衡量及主動學習的思路,提出了謠言判別中可衡量數據和模型不確定性的指標,并以此指標拒絕對模型泛化不友好的訓練樣本,探索對模型性能的影響。
數據概覽
早期與謠言檢測有關的工作多集中于通過事件關鍵詞檢索的方式,獲取討論激烈、事實性難辨的社交網絡短文本,文本之間相對較為孤立。后有學者提出根據消息的轉發關系形成完善的信息傳播樹,從更為全局和全面的角度評估消息及相關討論的真偽性(Mou, 2015)。目前,謠言判別常采用的數據集也均以信息傳播樹的方式進行組織,每一個待判斷的傳播樹的完整的信息傳播結構以及樹層面的類別標簽,以上三篇文章涉及的數據集羅列如下。
Twitter15(Liu, 2016):從國外謠言公布網站(如snopes.com, emergent.info)獲取已進行判別的社交網絡信息,再由其發布的Twitter消息源爬取相關的轉發信息形成信息傳播樹,共包含1374個信息傳播樹;傳播樹標簽包含非謠言/真實信息/虛假信息/未被證實信息,各個類別比例較為均衡,訓練、驗證及測試集為隨機劃分。
Twitter16(Ma, 2016):構造思路與Twitter 15一致,根據當年熱門事件進行了擴充,包含735個信息傳播樹,每棵樹包含消息數目更少。
PHEME(Zubiaga, 2016; Zubiaga, 2017):從9個和政治、民生密切相關的主題出發,搜集了與這些主題相關的Twitter內容及其引發的討論信息,篩選社交討論性質更明顯的形成信息傳播樹,根據謠言檢測、立場分類、謠言判別的任務流程由新聞從業者進行標注,通過謠言檢測將6425個信息傳播樹分類為謠言/非謠言,對于2402個謠言信息傳播樹再判別為真實信息/虛假信息/未被證實信息;采用LOEO(leave one event out)的驗證方式,使其更貼近實際應用場景,但不同事件文本和類別差異都很大,極具挑戰性。
RumourEval(Derczynski, 2017):是PHEME數據集的子集,篩選了立場標簽較為完善的325個傳播樹,作為Semeval-2017 task 8的評測數據集,訓練、驗證及測試集為隨機劃分。
論文細節
1

基于圖網絡和協同注意力機制的用于可解釋社交媒體虛假新聞檢測的模型
論文動機
此前相關研究主要受到三方面的局限:
短文本社交網絡文本建模能力不足。大部分用戶在轉發信源時發表的言論都較為簡短,且許多僅為轉發行為缺少實質性新增話語,基于信息傳播樹僅對消息文本進行建模表示能力有限。
構建準確的信息傳播樹代價昂貴。部分社交網絡平臺對爬取轉發鏈數目進行了限制,并且部分用戶設置了閱讀權限,獲取的傳播樹常存在缺失或截斷的現象。
復雜模型的可解釋性不足。即使模型最終輸出真偽性標簽,但內部決策過程很難驗證,并且對于進一步實際應用,如挖掘潛在惡意用戶、造謠慣用話術等沒有幫助。
因此文章在對信源建模后,僅使用涉及的傳播用戶對信息傳播樹進行建模,并且融入協同注意力機制,對判決過程中的關鍵用戶和關鍵信息進行呈現。
模型
整體模型大致可拆解為4部分:
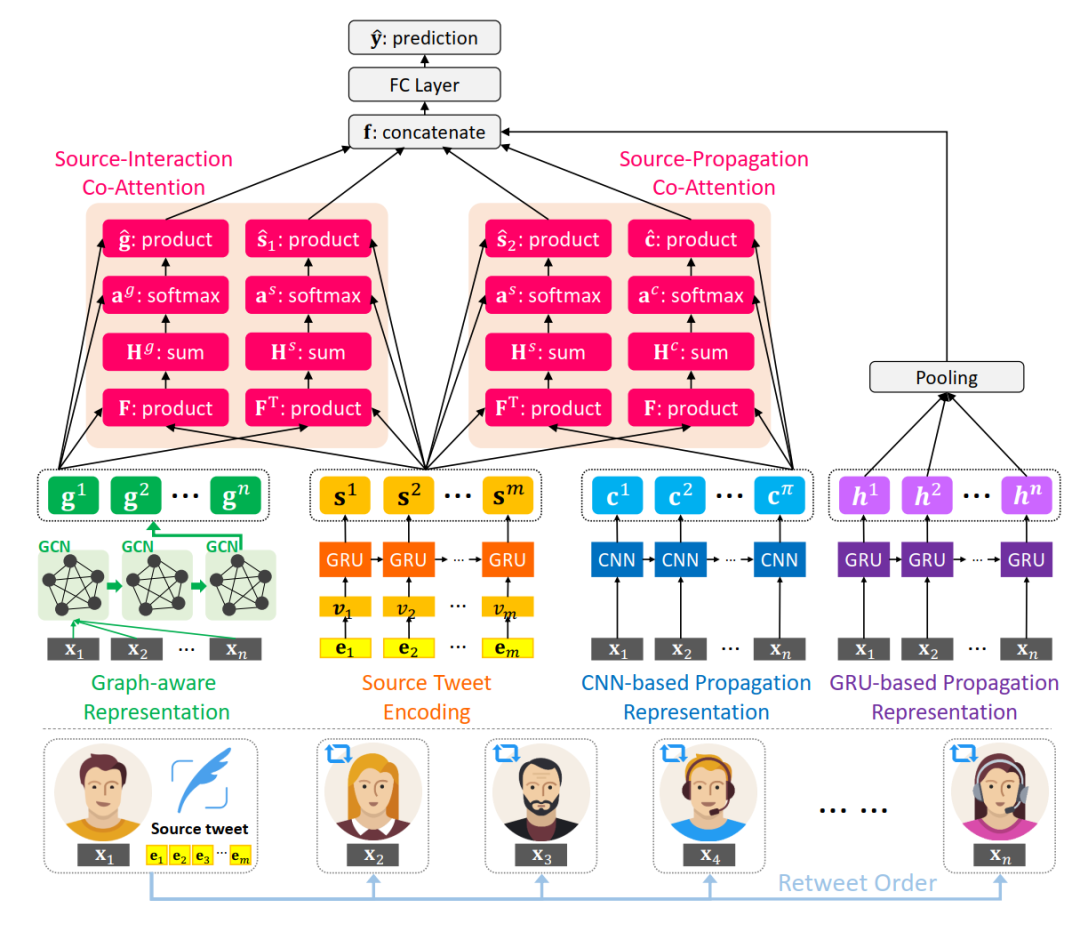
1. 信源文本表示
對原始消息文本中的詞語進行one-hot編碼,再使用GRU序列模型進行表示:
2. 用戶傳播特征表示
根據用戶的個人資料(個人簡介字數、昵稱字數、關注數、被關注數、是否認證、是否開啟地理定位、距離傳播樹中上一條消息的時間間隔、轉發所在樹的深度)提取用戶特征,根據用戶的發文時間形成序列,分別使用CNN和GRU得到傳播序列的表示。
分別使用兩個模型進行建模,經過CNN得到的序列表示在進行協同注意力融合時更為友好,而GRU能體現傳播過程中參與用戶類型的變化。
3. 用戶潛在交互網絡表示
除了在時間軸上用戶參與較為宏觀的表示,用戶之間點對點的交互關系也能刻畫信息的傳播模式。為了簡化傳播樹構造過程,文章直接將傳播樹內涉及的用戶組成全連接圖,以用戶之間的余弦相似度初始化邊權重以及圖的鄰接矩陣
,接著使用GCN得到具有交互特征的用戶表示。
4. 協同注意力網絡及預測
使用協同注意力機制得到融合表示,其中對信源和用戶傳播表示的融合表示計算如下:
對信源和用戶交互表示的融合計算方式類似。
再將信源和用戶交互表示的融合表示、信源和用戶傳播表示的融合表示、用戶傳播的序列化表示拼接,通過全連接層得到最終預測結果,以交叉熵損失函數作為優化目標來訓練。
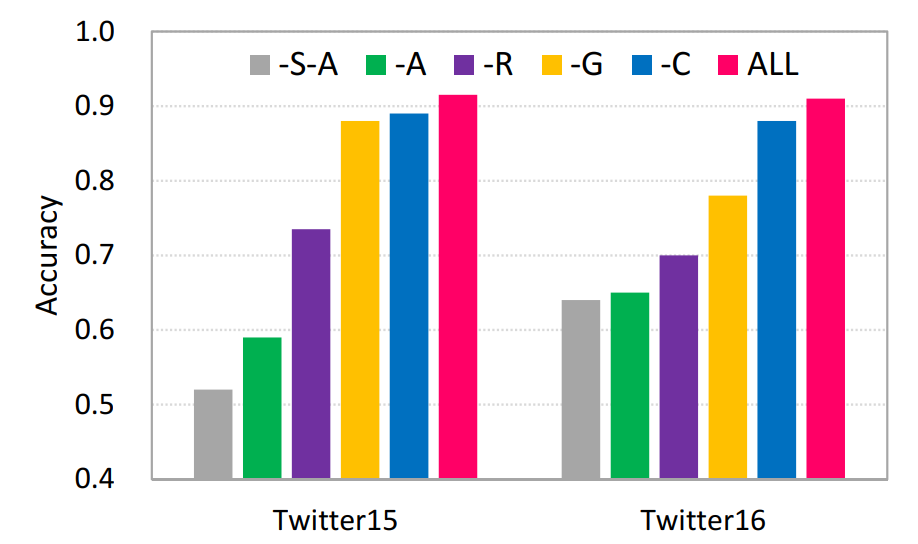
結果
模型在Twitter15、Twitter16兩個數據集上都取得了更優的性能。
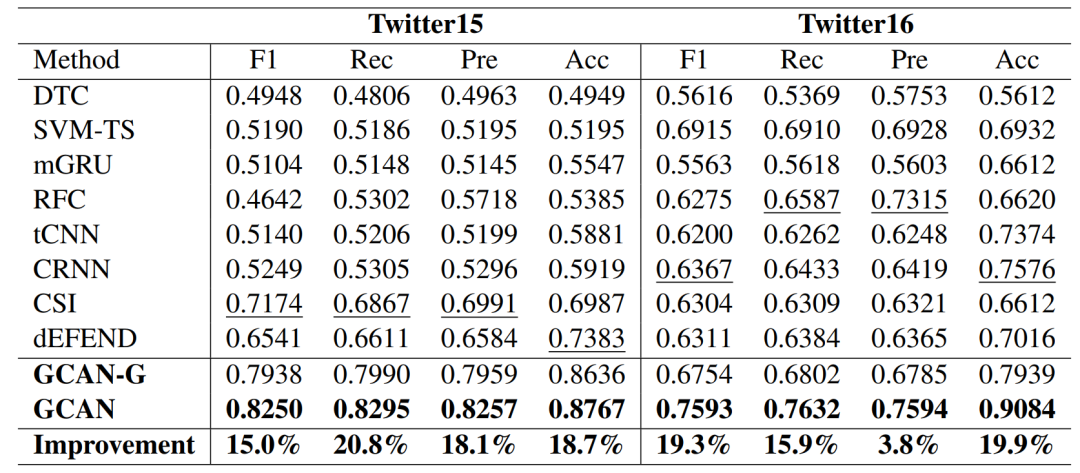
消融實驗也驗證了各個部件的有效性。
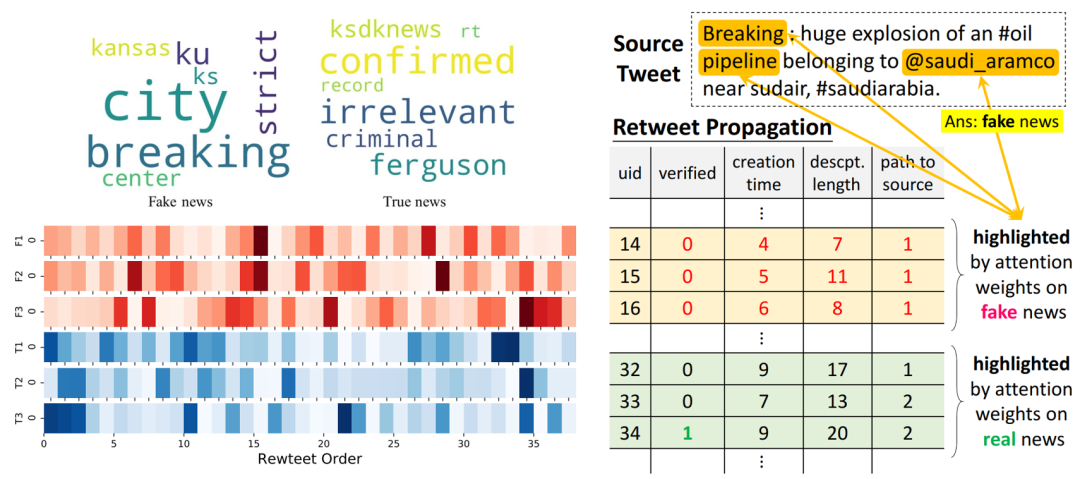
在可解釋性的論證方面,分別提取關于信源中基于詞的注意力權重、在用戶傳播表示中基于用戶的注意力權重,分析真實信息/虛假信息案例中的關鍵詞、傳播判別模式和更易參與虛假信息傳播的用戶特征。
2

基于決策樹和協同注意力機制的可解釋的謠言判別模型
論文動機
雖然此前研究大多表明信息傳播樹中的后續討論內容(如話題爭議點、對原始信息真實的質疑等)對于整體判斷有幫助,但缺少定位到具體有所呼應、有所論證單條消息的過程。此外,后續討論內容與原始消息之間具體的詞級別的交互未進行深入探索。
因此文章使用決策樹具有解釋性的呈現出篩選佐證的過程,并基于協同注意力機制探索信源與相關佐證之間詞級別的關聯,形成對信息傳播樹真偽性判別可解釋性的邏輯鏈條。
模型
模型可分為2個部件:
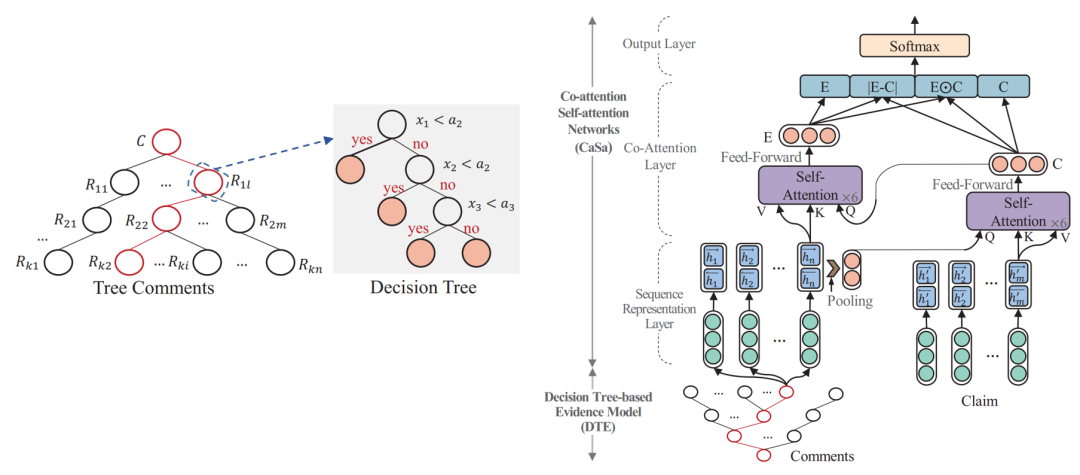
1. 基于決策樹模型篩選佐證信息
根據以往研究構造與后續討論相關性、可信度相關的3個數值型特征:消息與信源之間的語義相似度,發表消息用戶的可信度,該條的可信度。
多次試驗,分別設置3個數值特征的臨界值條件,只要3個特征之一小于其閾值則將該條消息納入佐證集合。
2. 基于協同注意力機制進行預測
對信息源文本使用雙向LSTM更新詞語表示;接著將第1步中提取出的佐證拼接起來,同樣使用雙向LSTM更新詞表示。
基于協同注意力機制或者兩者互相融合的表示。即在注意力權重計算公式中,保持關鍵字矩陣K、值矩陣V本身表示,將查詢矩陣Q更換為需要進行交互的表示。
以計算O的方式獲得兩者交互融合的表示E和C后,進行求差、求內積并拼接的操作,得到信息傳播樹的表示,最后使用全連接層輸出類別標簽,并使用交叉熵損失函數進行訓練。
結果
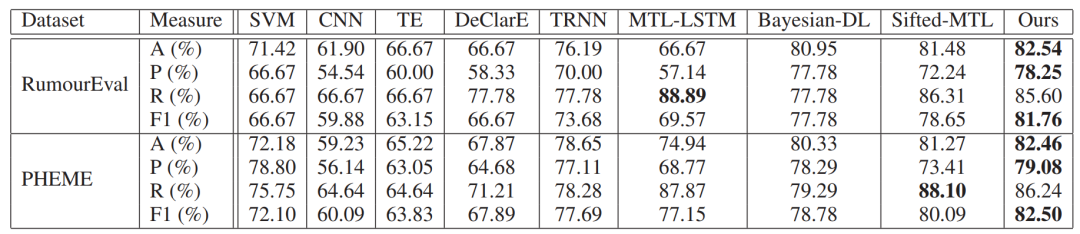
文章在RumourEval和PHEME數據集上進行測試(隨機劃分訓練、驗證、測試集),在大多數分類評價指標上都優于已有模型。
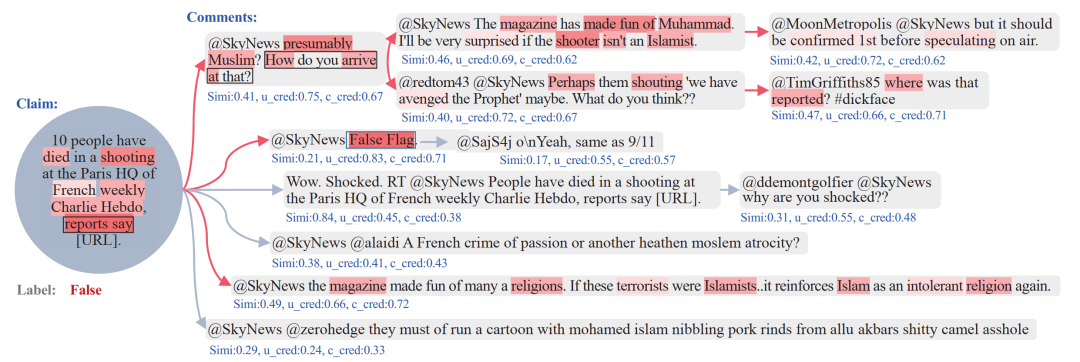
在可解釋性的論證方面,文章抽取出1個信息傳播樹的案例,可視化了提出模型的決策過程。圖中藍色文本代表決策樹模型中3個特征的具體數值,根據這些特征篩選出的佐證由紅色箭頭標記出來。同時,不同深色的紅色陰影代表了計算的協同注意力權重,可以看到一些與謠言判別更相關的事件描述詞。
3

評估謠言判別模型中的預測不確定性
論文動機
在實際應用場景下,謠言判別是極為復雜的系統性任務,智能化的謠言判別方法還不能完全取代人的細致全面的判斷,但能縮小人工核查的范圍。如果能更準確的找出對于模型難以判別的樣例,再交由人工判斷,將更加優化實際生活中對謠言的發現和判別。
另外,由于大多數模型是基于歷史數據進行訓練的,面對新產生的突發事件,模型的泛化能力往往不佳。若能剔除對整體泛化性能影響較大的訓練樣例,則有望進一步提升模型對新事件的泛化能力。
因此,文章借鑒在不確定性衡量方面相關工作以及主動學習的實驗設置,提出了一系列用于衡量數據和模型不確定性的指標,并探索這些指標與模型預測能力、訓練數據篩選之間的關聯。
方法
文章先基于謠言判別的基線模型獲取可比較的基礎性能,接著計算不同類型的不確定性指標,并以此剔除訓練樣本再次訓練,分析基線模型性能變化。
1. 基線模型
基線模型采用在RumourEval 2019任務上具有不錯性能的枝化LSTM模型(branchLSTM),即根據信息傳播的方向,將每條傳播序列抽取出來,對每個序列使用LSTM進行表示得到預測標簽后,再對所涉及的所有序列結果進行大多數投票得到傳播樹的預測標簽。
2. 不確定性衡量
不確定性可從數據和模型兩個層面進行考慮。數據的不確定性主要與所訓模型的分類邊界有關,距離分類邊界越近,數據層面的不確定性就越高,加入輕微擾動則容易使得分類結果轉變。模型的不確定性主要與各維表示對模型分類結果的代表性能相關,若僅保留部分維度的表示,預測結果依然穩定,則表明模型的不確定性較低。
在衡量模型不確定性(epistemic uncertainty)時,重復輸出預測結果前的dropout層N次,由于dropout具有隨機性,則每次預測結果將有所差異,用以下三個指標進行衡量:
變異比(variation ratio),即和主要預測類別不同的類別所占的比例,
熵(entropy),由于預測類別時得到的one-hot向量,對每一維度的概率求熵:
方差(variance),對于N次dropout的結果,計算代表類別概率的每一維度的方差,取最大值作為模型不確定衡量指標。
3. 數據篩選
在獲得每個樣例的數據和模型方面的不確定性數值指標后,通過非監督和監督方式舍棄樣本。
非監督的舍棄即根據樣本某一類型的不確定性進行排序,按一定比例舍棄掉不確定性高的樣本。
監督的舍棄即從訓練數據中再劃分一小部分數據訓練一個較為簡單的預分類器(SVM或隨機森林),輸入特征為各種類型的不確定性指標,原有的one-hot預測結果和真實標簽,分類錯誤的數據則打上被拒絕的標簽。由此對剩下的訓練數據通過預分類器判斷是否需要舍棄。監督的舍棄方法能盡可能的利用到不同類型的不確定性衡量指標,且舍棄數目由預分類器給出而不需要人為試驗多次。
結果
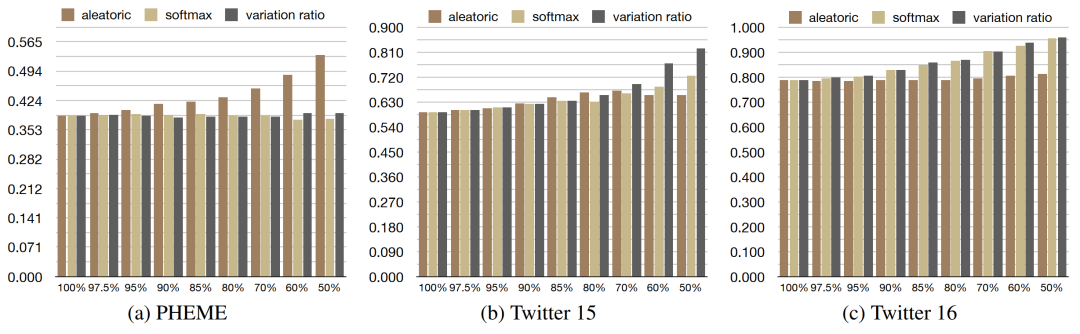
文章在PHEME、Twitter15、Twitter16數據集上進行了實驗,結果表明在進行了數據舍棄后,模型的性能均有提升,尤其采用有監督方式的舍棄,提升更為顯著。

在不同數據上,根據不同類型不確定性指標進行非監督的數據舍棄有明顯差別。由于PHEME數據集驗證方式為LOEO,測試集與驗證集語義差距、類別比例都較大,因此根據數據不確定性效果提升更為明顯。而Twitter15、Twitter16數據集較為均衡,針對模型不確定性的數據舍棄更為有效。
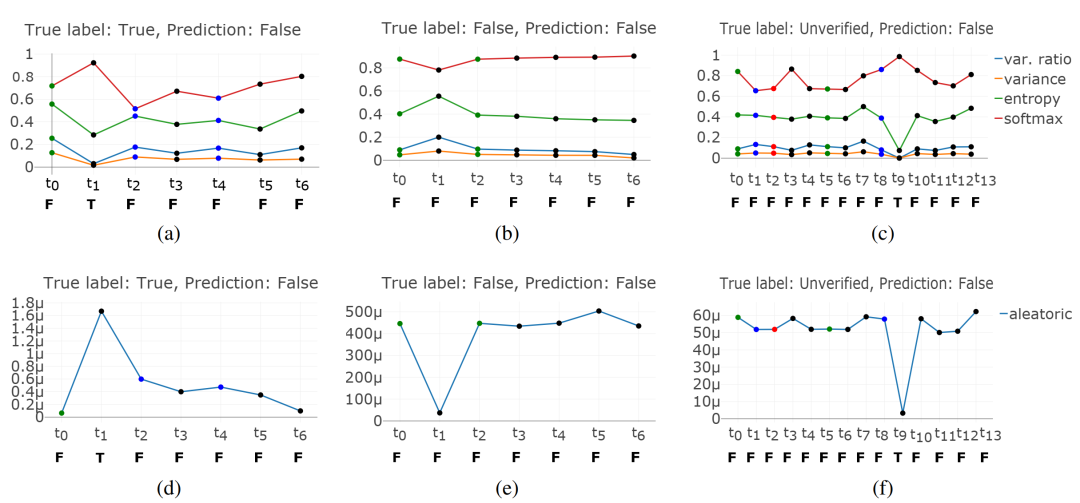
同時文章借助PHEME數據中傳播樹中部分消息的立場標簽,探究了隨時間變化,不斷增多傳播樹相關的討論,模型預測結果和不確定性的變化。圖中展示了3個真實標簽分別為真實/虛假/未經證實而預測標簽均為虛假的樣例,橫軸代表該傳播樹不同時刻的消息,橫軸下方的大寫字母代表僅將該時刻前數據輸入模型得到的預測標簽;縱軸表示僅將該時刻前數據輸入模型得到的不確定性的具體數值,圖中上半部分代表模型不確定性,下半部分代表數據不確定性,并且圖中每個圓點顏色代表不同立場(綠色-支持/紅色-反對/藍色-質疑/黑色-評論)。
可以看到,隨著傳播樹信息的不斷豐富,不確定性指標呈現出下降趨勢;觀察每一時刻的預測標簽,預測結果和僅利用原始消息差別不多,說明在此模型下信源信息對謠言判別尤為重要。
總結
以上三篇文章均為社交網絡謠言判別中可解釋性探索提供了不同的解決思路。其中,協同注意力機制的廣泛應用能有效的融合不同來源的信息(如信源和用戶之間,信源和佐證之間),并定位對于謠言判別更為關鍵的部分。另外,對數據和模型不確定性的細化衡量能使人更加認識數據集的內置偏差或是模型的自身缺陷。
-
數據集
+關注
關注
4文章
1205瀏覽量
24641 -
深度學習
+關注
關注
73文章
5492瀏覽量
120975 -
cnn
+關注
關注
3文章
351瀏覽量
22168
原文標題:【論文分享】ACL 2020 社交網絡謠言判別中可解釋性相關研究
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
機器學習模型可解釋性的結果分析
什么是“可解釋的”? 可解釋性AI不能解釋什么
斯坦福探索深度神經網絡可解釋性 決策樹是關鍵


機器學習模型的“可解釋性”的概念及其重要意義
機器學習模型可解釋性的介紹
圖神經網絡的解釋性綜述
《計算機研究與發展》—機器學習的可解釋性

文獻綜述:確保人工智能可解釋性和可信度的來源記錄





 工商網監
工商網監
評論