 在Rust被很多項目使用以后,其實際安全性表現到底如何呢?
在Rust被很多項目使用以后,其實際安全性表現到底如何呢?
近幾年,Rust語言以極快的增長速度獲得了大量關注。其特點是在保證高安全性的同時,獲得不輸C/C++的性能,讓系統編程領域難得的出現了充滿希望的新選擇。在Rust被很多項目使用以后,其實際安全性表現到底如何呢?
今年6月份,來自3所大學的5位學者在ACM SIGPLAN國際會議(PLDI'20)上發表了一篇研究成果,針對近幾年使用Rust語言的開源項目中的安全缺陷進行了全面的調查。這項研究調查了5個使用Rust語言開發的軟件系統,5個被廣泛使用的Rust庫,以及兩個漏洞數據庫。調查總共涉及了850處unsafe代碼使用、70個內存安全缺陷、100個線程安全缺陷。
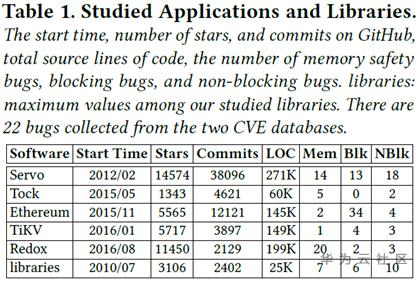
在調查中,研究員不光查看了所有漏洞數據庫中報告的缺陷和軟件公開報告的缺陷,還查看了所有開源軟件代碼倉庫中的提交記錄。通過人工的分析,他們界定出提交所修復的BUG類型,并將其歸類到相應的內存安全/線程安全問題中。
內存安全問題的分析
這項研究調查了70個內存安全問題。針對于每個問題,研究者仔細的分析了問題出現的根因(cause)和問題導致的效果(effect)。問題根因是通過修改問題時提交的patch代碼來界定的——即編碼的錯誤發生在哪兒;問題的效果是指代碼運行造成可觀察的錯誤的位置,比如出現緩沖區溢出的代碼位置。由于從根因到效果有個傳遞過程,這兩者有時候是相隔很遠的。根據根因和效果所在的代碼區域不同,研究者將錯誤分為了4類:safe -> safe、safe -> unsafe、unsafe -> safe、unsafe -> unsafe。比如:如果編碼錯誤出現在safe代碼中,但造成的效果體現在unsafe代碼中,那么就歸類為safe -> unsafe。
另一方面,按照傳統的內存問題分類,問題又可以分為空間內存安全(Wrong Access)和時間內存安全(Lifetime Violation)兩大類,進一步可細分為緩沖區溢出(Buffer overflow)、解引用空指針(Null pointer dereferencing)、訪問未初始化內存(Reading uninitialized memory)、錯誤釋放(Invalid free)、釋放后使用(Use after free)、重復釋放(Double free)等幾個小類。根據這兩種分類維度,問題的統計數據如下:
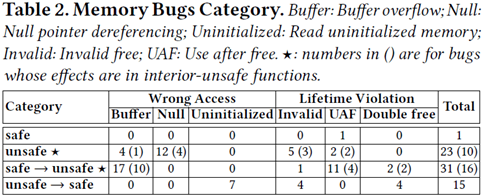
從統計結果中可以看出,完全不涉及unsafe代碼的內存安全問題只有一個。進一步調查發現這個問題出現在Rust早期的v0.3版本中,之后的穩定版本編譯器已經能攔截這個問題。因此可以說:Rust語言的safe代碼機制能非常有效的避免內存安全問題,所有穩定版本中發現的內存安全問題都和unsafe代碼有關。
然而,這并不意味著我們只要檢查所有unsafe代碼段就能有效發現問題。因為有時候問題根因會出現在safe代碼中,只是效果產生在unsafe代碼段。論文中舉了一個例子:(hi3ms沒有Rust代碼編輯功能,只能拿其他語言湊合下了)
Css代碼
pub fn sign(data: Option<&[u8]>) { let p = match data { Some(data) => BioSlice::new(data).as_ptr(), None => ptr::null_mut(), }; unsafe { let cms = cvt_p(CMS_sign(p)); } }
在這段代碼中,p是raw pointer類型,在safe代碼中,當data含有值(Some分支)時,分支里試圖創建一個BioSlice對象,并將對象指針賦給p。然而,根據Rust的生命周期規則,新創建的BioSlice對象在match表達式結束時就被釋放了,p在傳給CMS_sign函數時是一個野指針。這個例子中的unsafe代碼段沒有任何問題,如果只檢視unsafe代碼,不可能發現這個釋放后使用的錯誤。對此問題修改后的代碼如下:
Css代碼
pub fn sign(data: Option<&[u8]>) { let bio = match data { Some(data) => Some(BioSlice::new(data)), None => None, }; let p = bio.map_or(ptr::null_mut(),|p| p.as_ptr()); unsafe { let cms = cvt_p(CMS_sign(p)); } }
修改后的代碼正確的延長了bio的生命周期。所有的修改都只發生在safe代碼段,沒有改動unsafe代碼。 既然問題都會涉及unsafe代碼,那么把unsafe代碼消除掉是否可以避免問題?研究者進一步的調查了所有BUG修改的策略,發現大部分的修改涉及了unsafe代碼,但是只有很少的一部分修改完全移除了unsafe代碼。這說明unsafe代碼是不可能完全避免的。
unsafe的價值是什么?為什么不可能完全去除?研究者對600處unsafe的使用目的進行了調查,發現其中42%是為了復用已有代碼(比如從現有C代碼轉換成的Rust代碼,或者調用C庫函數),22%是為了改進性能,剩下的14%是為了實現功能而繞過Rust編譯器的各種校驗。
進一步的研究表明,使用unsafe的方法來訪問偏移的內存(如slice::get_unchecked()),和使用safe的下標方式訪問相比,unsafe的速度可以快4~5倍。這是因為Rust對緩沖區越界的運行時校驗所帶來的,因此在某些性能關鍵區域,unsafe的作用不可缺少。
需要注意的是,unsafe代碼段并不見得包含unsafe的操作。研究者發現有5處unsafe代碼,即使去掉unsafe標簽也不會有任何編譯錯誤——也就是說,從編譯器角度它完全可以作為safe代碼。將其標為unsafe代碼是為了給使用者提示關鍵的調用契約,這些契約不可能被編譯器檢查。一個典型的例子是Rust標準庫中的String::from_utf8_unchecked()函數,這個函數內部并沒有任何unsafe操作,但是卻被標為了unsafe。其原因是這個函數直接從用戶提供的一片內存來構造String對象,但并沒有對內容是否為合法的UTF-8編碼進行檢查,而Rust要求所有的String對象都必須是合法的UTF-8編碼字符串。
也就是說,String::from_utf8_unchecked()函數的unsafe標簽只是用來傳遞邏輯上的調用契約,這種契約和內存安全沒有直接關系,但是如果違反契約,卻可能導致其他地方(有可能是safe代碼)的內存安全問題。這種unsafe標簽是不能去除的。
即便如此,在可能的情況下,消除unsafe代碼段確實是個有效的安全改進方法。研究者調查了130個去掉unsafe的修改記錄,發現其中43個通過代碼的重構把unsafe代碼段徹底改為了safe代碼,剩下的87個則通過將unsafe代碼封裝出safe的接口來保證了安全性。
線程安全問題的分析
這項研究調查了100個線程安全問題。問題被分為了兩類:阻塞式問題(造成死鎖)和非阻塞式問題(造成數據競爭),其中阻塞式問題有59個,之中55個都和同步原語(Mutex和Condvar)有關:

雖然Rust號稱可以進行“無畏并發”的編程,并且提供了精心設計的同步原語以避免并發問題。然而,僅僅用safe代碼就可能導致重復加鎖造成的死鎖,更糟糕的是,有些問題甚至是Rust的特有設計所帶來的,在其他語言中反而不會出現。論文中給出了一個例子:
Css代碼
fn do_request() { //client: Arc
這段代碼中,client變量被一個讀寫鎖(RwLock)保護。RwLock的方法read()和write()會自動對變量加鎖,并返回LockResult對象,在LockResult對象生命周期結束時,自動解鎖。
顯然,該段代碼的作者以為client.read()返回的臨時LockResult對象在match內部的匹配分支之前就被釋放并解鎖了,因此在match分支中可以再次用client.write()對其加鎖。但是,Rust語言的生命周期規則使得client.read()返回的對象的實際生命周期被延長到了match語句結束,所以該段代碼實際結果是在read()的鎖還沒有釋放時又嘗試獲取write()鎖,導致死鎖。
根據生命周期的正確用法,該段代碼后來被修改成了這樣:
Css代碼
fn do_request() { //client: Arc
修改以后,client.read()返回的臨時對象在該行語句結束后即被釋放,不會一直加鎖到match語句內部。
對于41個非阻塞式問題,其中38個都是因為對共享資源的保護不當而導致的。根據對共享資源的不同保護方法,以及代碼是否為safe,這些問題進一步被分類如下:
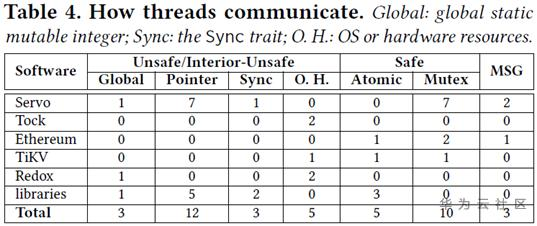
38個問題中,有23個發生在unsafe代碼,15個發生在safe代碼。盡管Rust設置了嚴格的數據借用和訪問規則,但由于并發編程依賴于程序的邏輯和語義,即使是safe代碼也不可能完全避免數據競爭問題。論文中給出了一個例子:
Css代碼
impl Engine for AuthorityRound { fn generate_seal(&self) -> Seal { if self.proposed.load() { return Seal::None; } self.proposed.store(true); return Seal::Regular(...); } }
這段代碼中,AuthorityRound結構的proposed成員是一個boolean類型的原子變量,load()會讀取變量的值,store()會設置變量的值。顯然,這段代碼希望在并發操作時,只返回一次Seal::Regular(...),之后都返回Seal::None。但是,這里對原子變量的操作方法沒有正確的處理。如果有兩個線程同時執行到if語句,并同時讀取到false結果,該方法可能給兩個線程都返回Seal::Regular(...)。 對該問題進行修改后的代碼如下,這里使用了compare_and_swap()方法,保證了對原子變量的讀和寫在一個不可搶占的原子操作中一起完成。
Css代碼
impl Engine for AuthorityRound { fn generate_seal(&self) -> Seal { if !self.proposed.compare_and_swap(false, true) { return Seal::Regular(...); } return Seal::None; } }
這種數據競爭問題沒有涉及任何unsafe代碼,所有操作都在safe代碼中完成。這也說明了即使Rust語言設置了嚴格的并發檢查規則,程序員仍然要在編碼中人工保證并發訪問的正確性。
對Rust缺陷檢查工具的建議
顯然,從前面的調查可知,光憑Rust編譯器本身的檢查并不足以避免所有的問題,甚至某些晦澀的生命周期還可能觸發新的問題。研究者們建議對Rust語言增加以下的檢查工具:
1. 改進IDE。當程序員選中某個變量時,自動顯示其生命周期范圍,尤其是對于lock()方法返回的對象的生命周期。這可以有效的解決因為對生命周期理解不當而產生的編碼問題。
2. 對內存安全進行靜態檢查。研究者們實現了一個靜態掃描工具,對于釋放后使用的內存安全問題進行檢查。在對參與研究的Rust項目進行掃描后,工具新發現了4個之前沒有被發現的內存安全問題。說明這種靜態檢查工具是有必要的。
3. 對重復加鎖問題進行靜態檢查。研究者們實現了一個靜態掃描工具,通過分析lock()方法返回的變量生命周期內是否再次加鎖,來檢測重復加鎖問題。在對參與研究的Rust項目進行掃描后,工具新發現了6個之前沒有被發現的死鎖問題。
論文還對動態檢測、fuzzing測試等方法的應用提出了建議。
結論
1. Rust語言的safe代碼對于空間和時間內存安全問題的檢查非常有效,所有穩定版本中出現的內存安全問題都和unsafe代碼有關。 2. 雖然內存安全問題都和unsafe代碼有關,但大量的問題同時也和safe代碼有關。有些問題甚至源于safe代碼的編碼錯誤,而不是unsafe代碼。 3. 線程安全問題,無論阻塞還是非阻塞,都可以在safe代碼中發生,即使代碼完全符合Rust語言的規則。 4. 大量問題的產生是由于編碼人員沒有正確理解Rust語言的生命周期規則導致的。 5. 有必要針對Rust語言中的典型問題,建立新的缺陷檢測工具。
-
編程
+關注
關注
88文章
3595瀏覽量
93606 -
代碼
+關注
關注
30文章
4752瀏覽量
68360 -
Rust
+關注
關注
1文章
228瀏覽量
6574
原文標題:前沿技術探討:Rust語言真的安全嗎?
文章出處:【微信號:Huawei_Developer,微信公眾號:華為開發者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Parker派克防爆電機在實際應用中的安全性能如何保證?

在電氣安裝中通過負載箱實現最大效率和安全性
socket編程的安全性考慮
UWB模塊的安全性評估
智能系統的安全性分析
NFC風險與安全性:揭示NFC技術高安全性的真相
藍牙模塊的安全性與隱私保護
開關電源安全性測試項目有哪些?如何測試?
M8_6pin公頭安全性怎樣

Rust效率領先C++兩倍,內存安全成國家安全議題
谷歌捐款100萬美元給Rust基金會,以增強C++與Rust的交互性
Git開發者關注內存安全問題,探討引入Rust語言






 工商網監
工商網監
評論