 從四個方面分析云游戲自動音視頻測試
從四個方面分析云游戲自動音視頻測試
在日益臨近的5G時代下,5G網絡和新的流視頻游戲服務將在未來幾年內讓云游戲的增長一觸即發,云游戲已漸成行業熱點。英特爾基于OWT(Open WebRTC Toolkit)也對云游戲使用場景所需要的高分辨率,高比特率和高幀率的視頻超低延時的實時傳輸做了深入研究和廣泛優化。云游戲中音視頻延時,音畫同步尤為重要。游戲中最為關注的音視頻檢測是怎么實現的?音視頻同步檢測是通過什么方式自動化實現的呢?本次講座將圍繞上述幾個問題從痛點,難點和解決方案一一展開。
1. 項目背景介紹
大家看到這些圖會想到什么?會不會想到我們最近疫情在家工作的場景。隨著流量包的提升和帶寬計費的下降,長短視頻最近非常火爆,疫情期間,在家上班、小朋友在家學習、在家會議已經成為了一種生活的常態,它們從生活的可選項瞬間變成了生活的必需品。上圖左邊的云游戲作為一種新的游戲視頻服務方式,在未來幾年云游戲的增長一定會因為各種原因一觸即發。云游戲已然成為了業界追蹤的熱點,我們英特爾基于OWT對于云游戲使用場景所需要的高分辨率、高幀率的視頻,同時又需要滿足低延時的實時傳輸,在這方面我們做了深入的研究和廣泛的優化。其實無論是音視頻會議系統還是云游戲場景中,音視頻的質量,用戶的體驗比如說音視頻的延時、音視頻的卡頓、音畫是否同步都極為重要。那么最為關注的音視頻的檢測是怎么實現的呢,比如說音畫同步怎么做?音視頻的檢測方法和算法有哪些呢?怎么融入到我們檢測體系中呢?這就是我將一一展開和大家講解的內容。
2. 音視頻傳播流程分析 2.1 傳統音視頻傳輸流程和問題分析

傳輸流程
上圖是一個傳統的音視頻傳輸的流程,左邊是發送方,我們可以想像成一個一對一的會議模式,右邊是接收方。發送方首先要進行視頻的采集,不管是用什么設備,用瀏覽器、用中間設備、用虛擬攝像頭、用真正的文件傳輸或是用真正的Camera傳輸或者視頻,首先都得進行采集。采集之后進行前處理降噪,加水印或美顏的功能,再進行編碼,通過網絡的傳輸,編碼后的視頻傳輸到中間服務器,服務器會進行視頻的中轉、處理,比如說會議模式會將多路收集到的視頻進行合并、壓縮、轉碼等等。在服務器會進行解碼壓縮再編碼,隨后視頻通過網絡傳輸送到接收方,接收方拿到這個視頻后會進行后處理和渲染。
問題分析
在整個流程中哪些地方會對音視頻的質量或者說發送給接收方的音視頻造成偏差呢?首先是發送方的采集,采集會有有損的損耗;其次是前處理;再然后是編碼,最后是發送方到接收方網絡因素的干擾,可能是網絡帶寬,網絡丟包等等影響。服務端這邊如果進行一個轉碼,解碼,再編碼,或者進行編碼的轉變,或者進行一個壓縮都是有損的。接收方這邊處理渲染也會帶來一部分的損耗,可以看到視頻從發送方到接受方的過程會經過各種各樣的曲折。 2.2 云游戲音視頻傳送流程分析
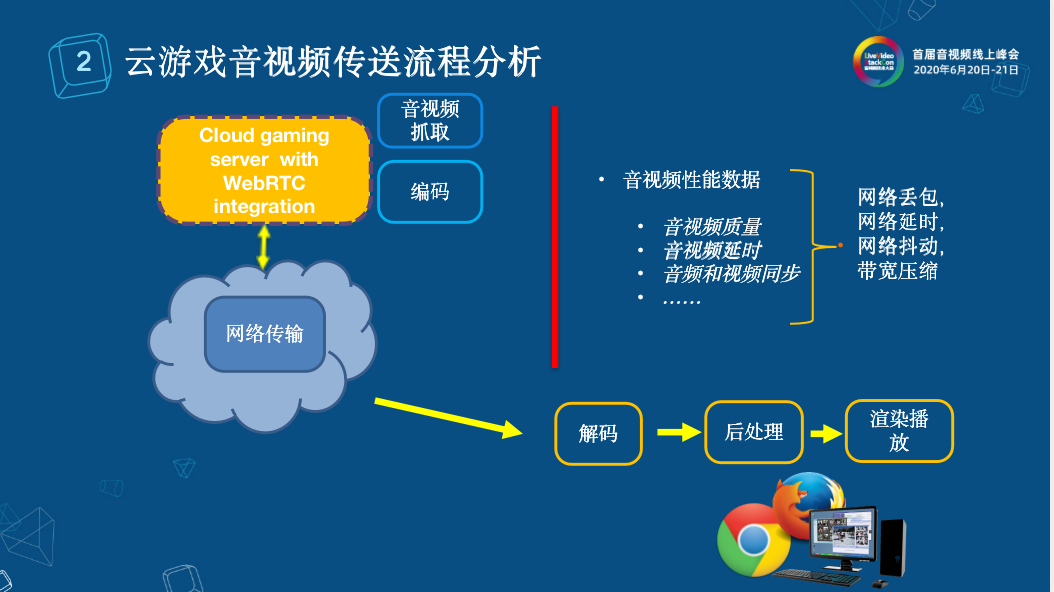
其實云游戲和上述傳統音視頻傳輸流程很類似,它們不同的點在于在云游戲的云端會有個終端游戲服務器,終端游戲服務器會進行游戲音視頻的捕捉,在捕捉之后將游戲音視頻進行一個編碼,編碼之后傳輸到客戶端,客戶端可能是瀏覽器,也有可能是終端設備,再解碼、后處理、渲染播放。那么整個流程中哪些會對音視頻有影響呢?一是服務端音視頻的捕捉和編碼;二是網絡傳輸;三是終端的解碼,后處理,渲染播放等等。
3. 音視頻評估標準和方法

在了解到了傳統的音視頻傳輸流程中一些步驟會導致音視頻偏差,我們需要思考如何做音視頻的評估,評估時的方法和標準及其使用。我將音視頻評估標準和方法分為了以下幾個部分:視頻質量評估、音頻質量評估、音畫同步、音視頻延時。 3.1 視頻質量評估 視頻的質量評估分為兩種:主觀評估和客觀評估。

主觀評估顧名思義就是用人工評估,那么人工評估并不是我們聽一聽就好了這么簡單。人工評估目前來說在各種協會比如說IEC、EBU、ITU等等國際電信聯盟都有相應的標準,以上的圖是我截取它們標準文檔的形式,首先是左上角的一個音頻設備,如果要搭建一個音視頻的實驗室,需要注意廣播設備的設置位置、廣播設備的距離、分貝的大小。那我們對視頻評估要注意音視頻實驗室觀看距離的設定、觀看視頻序列的設定、對觀測人員人數的限定(男女比例,老少比例,國籍比例等)。 由此可以看出搭建一個主觀評估的音視頻實驗室所需要耗費的時間、財力、人力成本是比較高的。評估之后會得出什么樣的結論呢?通常是一個1分到6分的結果:一分表示非常差、3分表示還可以接受,5分之后是非常好了。除了人力財力消耗比較高以外,主觀評估問題還有:我們要對非專業人員以專業標準進行培訓;隨機選取的人員也會導致主觀的差異、重復性低、數據無法量化,缺乏參考性、受到測試客觀環境的影響,比如如果視頻觀看遠近的切換,順序的切換有可能會影響最終的結果。當然它也有優點,這樣的結果始終是人的感官,而評估的目標就是為了知道這個音視頻給人感官的最后結果。

視頻客觀評估,通常稱為VQA(Video Quality Assessment),而Video通常是用一幀一幀的視頻幀數來組成的,每個視頻幀其實就是一張張圖片,我們會將VQA轉成IQA(Image Quality Assessment)。IQA的研究算法其實有很多,目前有很多學者會將IQA加入時域的特性,再轉成VQA的結果,進行客觀評估。客觀評估分為兩類:有參考評估和無參考評估。
客觀評估-有參考評估

有參考評估是什么?從字面上非常好理解,就是將參考視頻和待評估視頻一一對標之后輸入到評估算法和評估體系,最后得到分數。
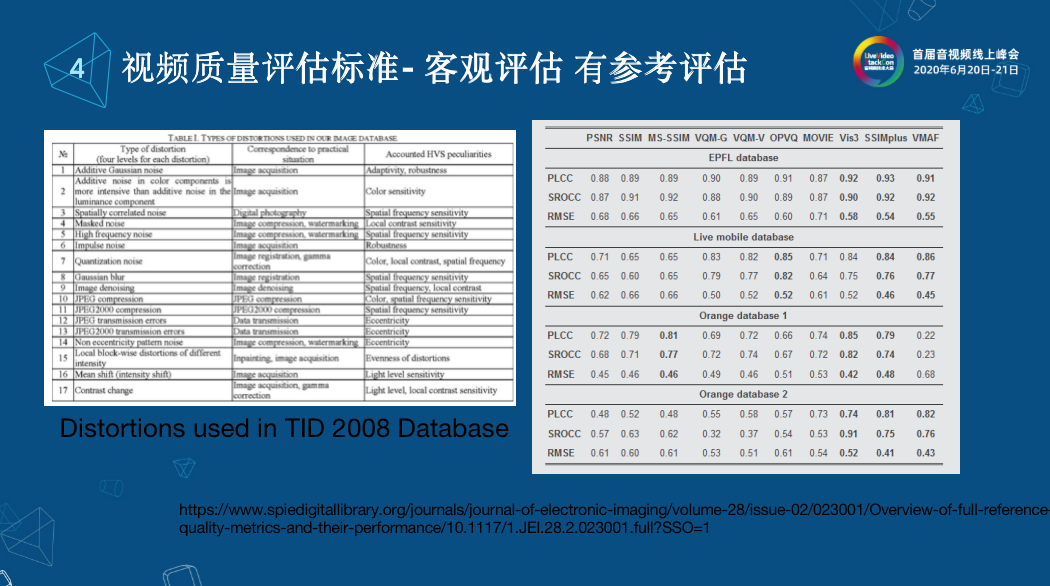
面對五花八門的各種算法,什么叫做好的算法呢?在業界上有很多開源的數據庫。各種學者和研究人員將他們的算法進行研究。上圖左邊TID 2008是大家都知道的圖像的數據庫,其實更新的是TID 2013。根據TID 2008的文檔描述,它是由一些正常的圖片和一些扭曲之后的圖片組成的。比如說正常圖像占一部分,接下來會增加一些高斯噪聲的圖片,或者是一些有選編碼之后的圖片,這些都有詳細的描述。 右圖是我們從公開的算法數據庫中獲取的,判斷算法的好壞通常是選幾個database,在database上進行評測,評測算法和數據庫中評估出來的評分,數據庫除了之前所說的圖像,還有一些扭曲視頻,另外一個很重要的因素是它會對提供的每張圖片做一個主觀打分的數值。算法和這個數值的相關性可以從PLCC、SROCC計算。相關關系函數的結果表示的是算法和真實的MSE值的偏差。通常絕對值越高,表示算法的性能越好。在拿到一些精簡的算法后會在各個數據庫中進行對比,比如PSNR、SSIM、VMAF等等。在每一個database里,這些相關關系函數得出的結果都比已有的算法好,那么就是一個很好的新算法。

那么在我們的體系中,我選了三個比較經典的算法PSNR、SSIM、VMAF作為有參考的評測標準。我們有了這些有參考的評算標準是否就足夠了呢?我們怎么將這些評估算法加入現有的體系中呢?

首先我們要解決的最核心的問題是測試結果和流程的可重復性,這是客觀評估和主觀評估非常大的差別。因為有了重復,所以可以重復地看問題出在哪兒,重現問題所在點。通常的做法是將隨機視頻輸入流,轉成固定視頻輸入流。光是轉成固定輸入流還不夠,將隨機視頻輸入流轉成固定視頻輸入流是恒定長度幀數的視頻流,比如說一千幀這樣一個視頻,那么我們在播放的時候就是一千幀重復播放,接收到的也是一千幀循環播放的視頻,我們需要知道我們接收到的視頻是對應的發生到的哪一幀,就要幀與幀之間對標之后才能算出有參考的算法,因為那些算法都是幀與幀之間對比出來的。 我們做了視頻幀的定位,在發送的時候就在視頻幀的左上角進行一個視頻幀的標記,標記的是發送了多少幀,第幾幀。那么在接收的時候,這個幀就會原生地傳輸過來,然后我們在后臺進行左上角幀字符的重識別。識別之后我們就知道是第幾幀,他在發送的時候我們進行一個循環標記符,通過循環標記符和左上角視頻幀的定位到第幾輪的第幾幀;通過接收到的視頻幀序列,我們就可以反過來將發送的視頻序列進行挑選。需要進行挑選的原因是在接收到的視頻里面,通過網絡之后會有一些幀的流失,比如發送的是100幀收到的只有50幀,那么根據接收到的50幀我們就找到發送對應的50幀進行一一對標的發送序列。發送序列和接收序列之間進行對比,輸入到有參考的算法,最后就可以得到相應的評估算法的結果。
客觀評估-無參考評估
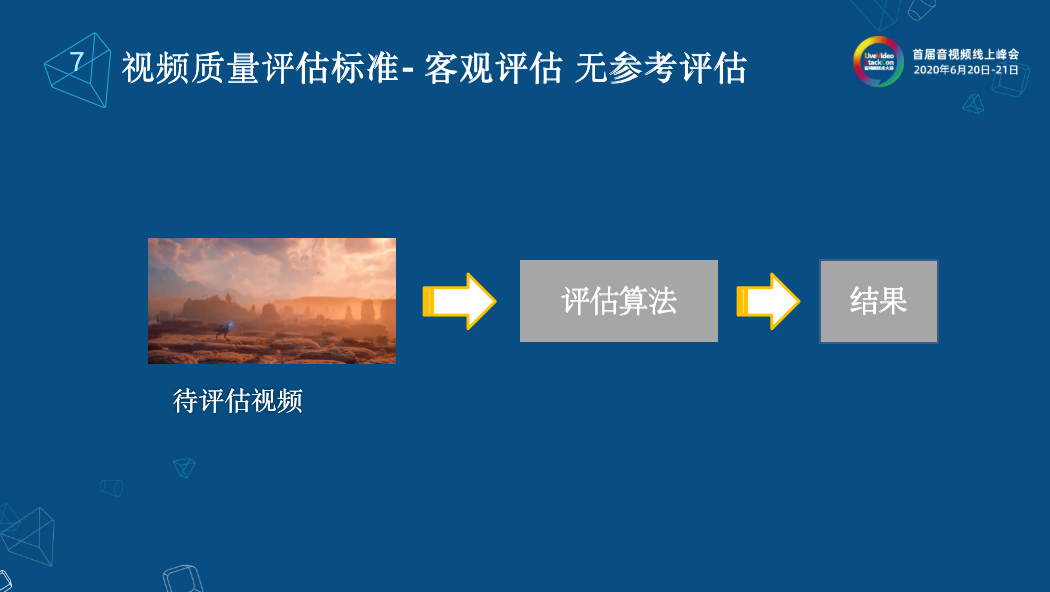
在現實生活中,我們看到了有參考的評估,在評估一個編碼的算法時用得很多。但真實在直播環境下,有參考是非常難做的,因為他需要擺脫干擾。那么這就涉及到了另一種客觀評估方法無參考評估,無參考評估也很好理解,我只有待測視頻,直接將待測視頻輸入到評估算法模型中,我就可以得到這樣的一個結果。
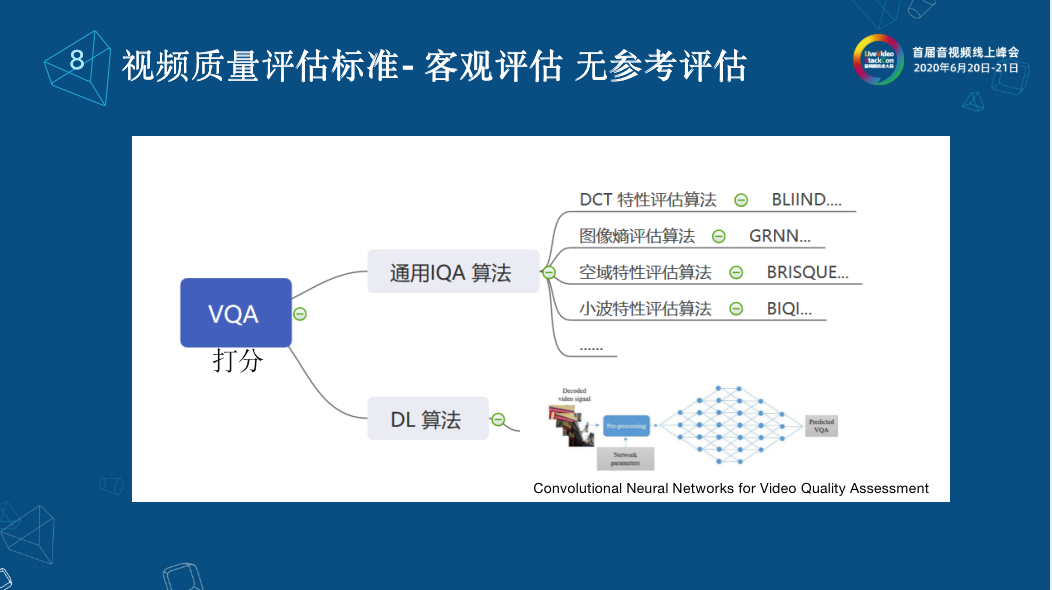
無參考評估分為兩大類:打分類和全幀掃描。 打分類就是和有參考一樣,將待測視頻輸入到無參考的算法中就可以的得到一個分數。 打分類通常有兩類。第一種是通過將VQA轉成IQA的無參考算法,這些算法都比較成熟了,我們可以看到有一些圖像熵評估算法(GRNN),空域特性評估算法(BRISQUE),除此之外很多學者都在研究DL算法,大家知道之前LiveVideoStackCon上有演講就是基于Camera的視頻的DL評估算法。整體來說,無參考的打分目前來看它的準確度與數據庫中MSE的偏差還是比較大的,它是沒有辦法和有參考評估并列的,準確度還是比較低的。
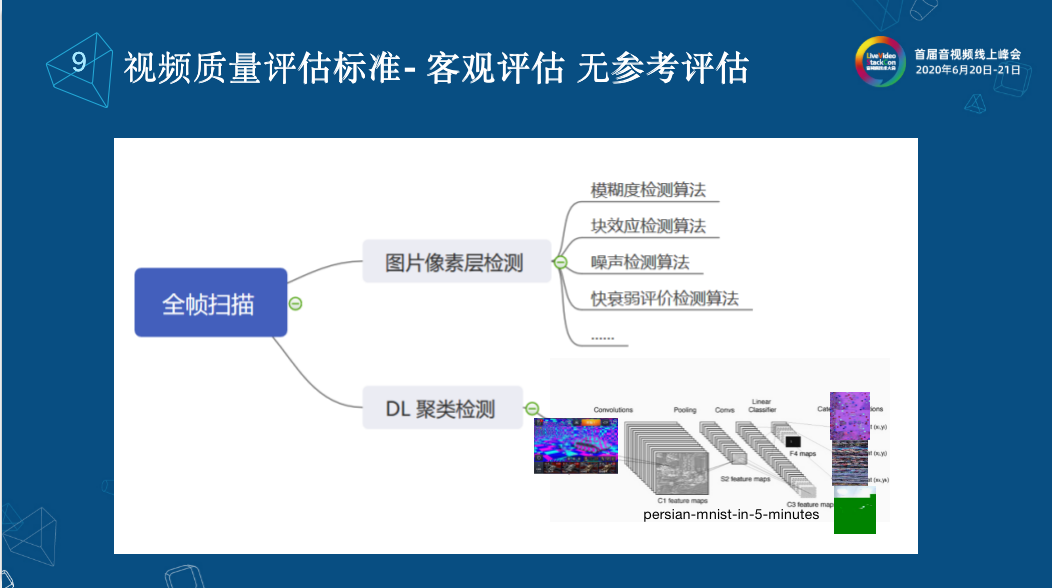
全幀掃描的意思是對收到的每一幀的數據都進行掃描和判斷。 全幀掃描又可以分為兩大類。第一個是圖片像素檢測,把視頻幀作為一張圖片,通過圖片的像素層進行模糊度檢測,來判斷這個視頻是不是帶有模糊,通過像素塊內和像素塊外的相關項來檢測是否有馬賽克的塊效應,同時也可以檢測是否有噪聲,快衰弱的評判算法,這些技術都已經比較成熟了。可我們后來又發現我們雖然有很多算法,但是我們不能覆蓋現實中的馬賽克。以現實中的馬賽克檢測來說,很多馬賽克并沒有被檢測出來,它可能和我們期望的像素成塊的有差距,說明它的算法不夠通用。目前很多公司包括我們自己也還在研究DL這一塊,我們可以根據不同產品來定制,比如說我們就想檢測出來,正常視頻幀有多少,我的異常視頻幀有多少,可以做分類的算法,如果有足夠多的視頻,可以進行標注正常和非正常。還可以通過的DL聚類檢測,大部分時候,我們的標注圖像信息不夠,我們可以通過一些聚類的檢測,做一些無參考的聚類、全幀掃描,所以可以根據自己的產品做一些相關的定制。

除了上文我們一直在講的視頻幀質量,實際上大部分產品,比如說在打游戲時候,你的視頻畫面是清晰的,但視頻過于卡頓就會十分影響用戶體驗。那么在有的情況下,比如說在開會的時候,并不要求視頻幀的質量很清晰,可能更加關注流暢度;看電影的時候,每個人的感官是不一樣的,我可能會希望視頻更清晰,流暢度稍微差一點也沒有關系。那我們有沒有這樣一些相關的指標可以體現出用戶的QoE體驗呢?
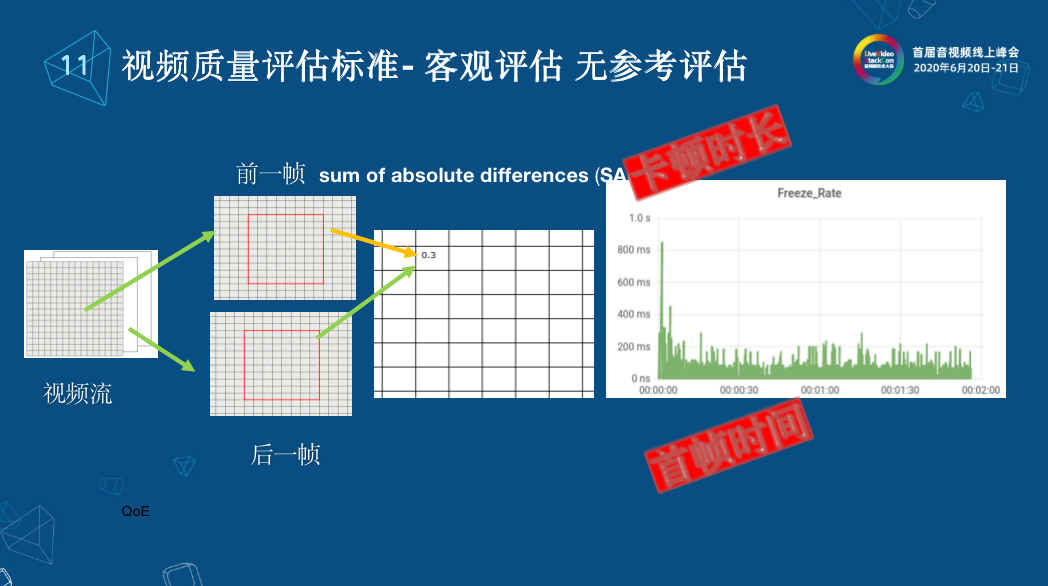
首先介紹一下我們的卡頓時長算法,將視頻按70000 fp值錄下來,每一幀通過濾波器,將每一幀分為8*8的像素塊,并為每一個像素塊的上一幀和下一幀計算絕對差值之和(SAD),我們就可以定義一個準則,設一個閾值,最高和最低差值,如果兩個視頻幀之間有足夠多的8*8之間的SAD大小都低于最低值,或者說我沒有一塊SAD大于最大值,在這種情況下就認為這兩張圖片是一樣的,以此認為它出現了卡頓,卡頓了多久就是卡頓的時長,卡頓了多少次就是卡頓的頻率,通常來說一秒左右的卡頓是人的肉眼可以感知的。但是我們又發現,如果卡頓頻率過快也會覺得畫面很卡。除了卡頓時長和卡頓頻率之外,還可以計算首幀時間,首幀時間就是當畫面在特定的情況下首幀出現的時候,畫面從不變到畫面突變的情況,這種情況下我們可以按照上面的算法算出首幀出現的時間。 3.2 音頻質量評估
客觀評估-有參考評估

從客觀評估來講,它的方法主要分兩種,有參考評估和無參考評估。有參考評估就是參考視頻和待測音頻,將兩個音頻進行對標,傳輸到評估算法模型里,得到相應的分數。打分的結果也和視頻一樣,上圖的分數是舉出例子可以看出哪些是滿意的哪些是不滿意的。

在這主要介紹客觀評估的算法PESQ,這是大家經常通用的算法。我們來看一下這套算法的主要流程。第一步是信號處理,我們將發送的音頻和待測的音頻進行信號處理,將兩個音頻進行一一對標,將時間對齊等等。第二步是建模,第一個模型是感知模型,這步中還包括頻率的映射以及帶寬信號的過密;第二個模型是認知建模,包括一些叫聲相關的信息組合進來,最后將它組合到MSE計算值的統計中,計算參考信號和失幀待評估信號之間的差,正值代表有噪聲,負值代表無噪聲或有較小的噪聲。這個模型的優點是它允許發現發送信號和接收信號有延時導致的偏差,它會將這些延時干擾去除,真正的評價參考信號和失幀待評估信號之間的偏差。但也有專家認為這樣是不合理的,因為中間有延時也會影響音頻感官的結果。

上圖是從polqa網頁上獲取的幾大有參考音頻評估算法的對比,圖下有網頁地址,它認為寬帶的算法可以作為PESQA后一代的音頻算法,目前更為大眾所用,但是這個算法需要購買LICENSE,所以大家用PESQ也是可以的。
客觀評估 無參考評估
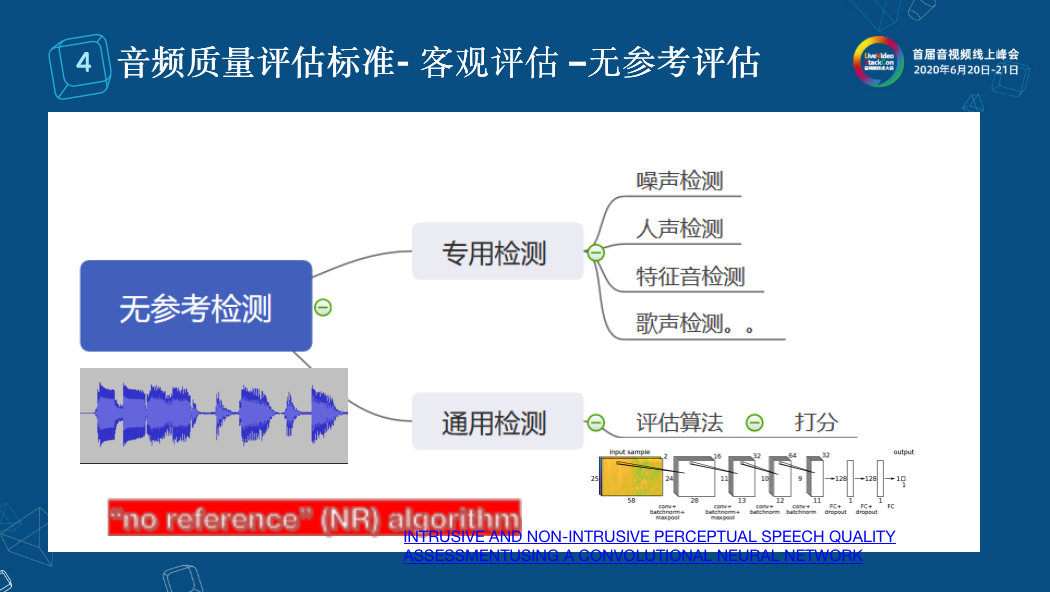
無參考評估分為兩大類:專項檢測和通用檢測。有些時候我們想進行特征音的查找,比如說人聲、噪音、歌聲的檢測。我們通過聲音指紋,相關度來進行特征音的檢測。除了這些專項檢測之外,也有些通用的檢測。我們可以將音頻型號輸入到DL序列號的模型進行打分評估,去年LiveVideoStackCon上也有介紹這樣的通用檢測方法,目前來說這種無參考檢測,它的準確度與有參考檢測的準確度對比還是相差很多。 3.3 音畫同步

單獨講音畫同步的原因是音畫同步是視頻和音頻評估的另外一部分。是不是音頻和視頻發送和接收做到分秒不差才能叫做音畫同步呢?那么多差才叫差也是有一定標準的。上圖所列的幾個組織,比如說國際電信聯盟、美國數字電視國家標準ATSC、歐洲廣播聯盟標準EBU等等都有相應標準。目前還是以ITU的標準作為主導方向。
主觀評估

上圖是ITU標準的定義。這是一個場景定義,現在是棒球的直播現場,棒球運動員正在打球,下面有一個實時的播音員,通過兩個采集設備進行采集之后,經過中間中轉,包括信息塔的傳輸或網絡的傳輸等等(它定義的比較早,所以是電視信號),最后終端用戶接收。 那音畫之間的差別多少是差呢?多少差別是可以接受的程度呢?最后他們總結了一個標準,負表示畫前音后,正表示音前畫后。他們認為畫前音后100ms到音前畫后25ms是無法感知的,所以認為這個時候視頻是音畫同步的。畫前音后125ms到音前畫后45ms是可以感知的,<-185ms到>90ms是不可以接受的。這是他們定義出來的標準。對于這個標準,我們有什么辦法對他做自動化的評估呢?
客觀評估
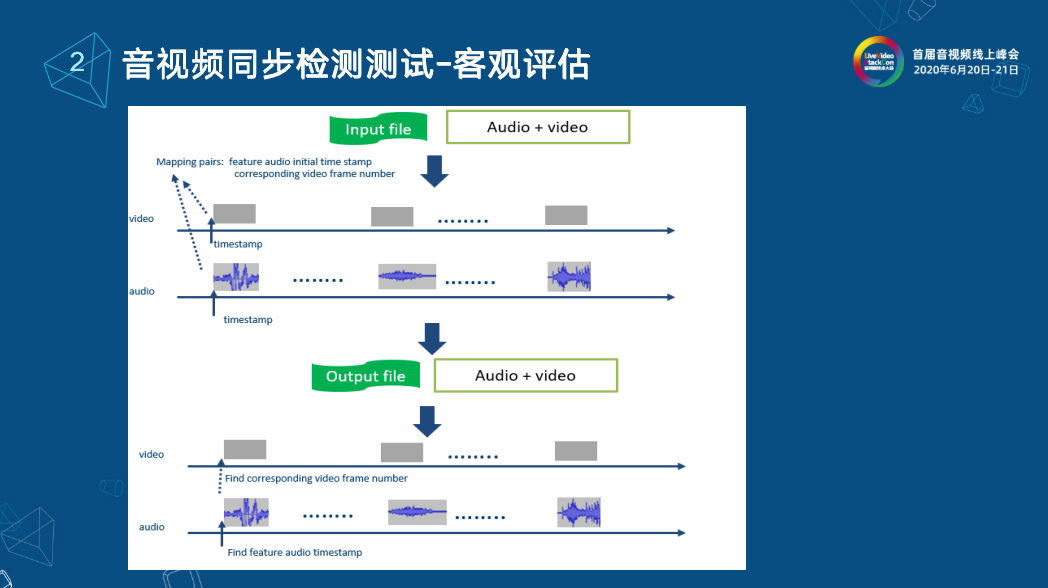
上圖就是我們經常做的工作。大概說一下整個流程供大家參考。我們在音頻和視頻中分別插入一系列的特征音和特征視頻幀,在插入的同時,我們在發送時對每個特征音和特征視頻幀記了時間錯信息,比如它標記成第一個特征視頻幀和第一個特征音頻幀的時間偏差,把它記錄下來。那么在接收方這邊,我們同樣的將音頻和視頻每一個都做后處理,先錄制存儲下來,然后在視頻中查找第一個特征視頻幀,計算它的時間偏差,同時查找第一個它對應的特征音頻幀,記錄它的時間信息,兩個相減,接收到的偏差和發送的偏差進行對標就可以算出音畫同步的偏差數值。 3.4 音視頻延遲
音視頻延時測試

在前文也有介紹過怎么處理音視頻的延時,在做白盒干擾的時候,我們在每一個視頻幀的左上角進行視頻幀的標注信息,可以知道這是第幾幀,在發送的同時會記一個時間戳給這一幀,接收到這樣的視頻序列之后,我們對接收到的每一個視頻幀標記時間信息,通過視頻幀的數據可以反推這是第幾幀。如果找到對標的兩個幀的時間信息,直接相減就可以得到端對端的延時,這里我還加一個bias是因為我們發送和接收要做到時間同步,發送和接收時間是兩臺不同的機器,有時間的偏差,只有考慮到這一點才能算出真正的端對端的延時。 音頻延時我們借助于音畫同步的偏差來計算,在接收到的序列中,通過特征音的查找找到對應視頻的時間戳,他們的偏差就是音畫同步的偏差,音畫同步的偏差結合視頻的偏差就能算出音頻的偏差。
鼠標點擊延時測試
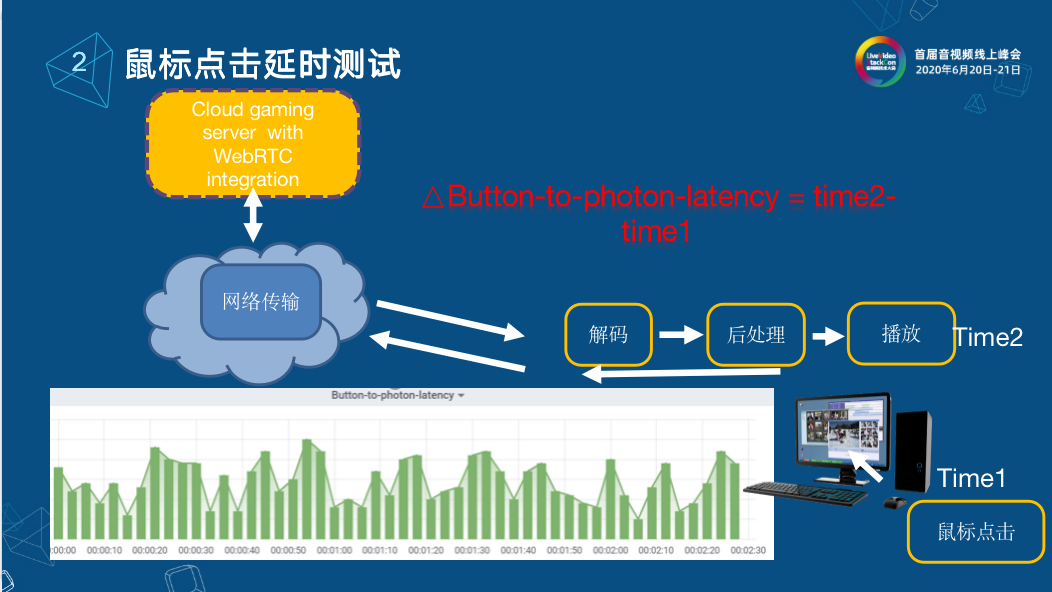
除了端對端的延時,在游戲中就是鼠標響應的時長。特別是在云游戲中,在客戶端開一槍,這一槍傳到服務器端最終相應到客戶端的時間長度就是鼠標的相應時長。通常我們會在點擊鼠標時刻記一個時間,然后將事件網絡傳輸到服務端,服務端在進行回傳的時候,真正相應到客戶端中計算記錄時間(time2),time2減去之前鼠標點擊的時間(time1)就是鼠標來回的時間。在后續,要根據不同的終端來做不同的處理,比如說瀏覽器可以借助Video Tag的event來做,其他終端可能要借助于視頻幀的檢測。
4. 系統性能評估輔助方法

在音視頻評估體系中,考慮到音視頻的質量、音視頻的延時、音畫同步參數之外,我們還會對系統的性能進行評估。我們整個通用中用了WebRTC,WebRTC stats其實提供了很多indicator,比如說fps、Bandwidth、幀率、幀大小、Nack cout、PacketLost等等因素。它其實也可以反饋給用戶系統的實時性能評估,我們為了修整這些信號利用OpenCensus,它提供了不管是服務端C++還是用客戶端js來做,用Node js的后端,最后將所有的數據不管是WebRTC stats的或是音畫同步的信息還是音視頻質量的時間信息統一傳輸到后端,通過Prometheus終端顯示,這樣很多數據就可以做實時監測的終端顯示,優點就是不管你在哪里,通過一臺瀏覽器就可以監控到目前的狀態。
-
音視頻
+關注
關注
4文章
465瀏覽量
29854 -
音視頻測試
+關注
關注
0文章
2瀏覽量
5444
原文標題:OWT(Open WebRTC Toolkit)云游戲自動音視頻測試探索
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
算力攻堅,誰是音視頻AIGC時代背后的「硬」核玩家?

盤點那些常見音視頻接口
常見音視頻接口的靜電浪涌防護和濾波方案

高清HDMI轉USB 3.0音視頻多功能音采集卡-測評
【RTC程序設計:實時音視頻權威指南】音視頻的編解碼壓縮技術
音視頻SoC與AI技術融合,帶來更智能的音視頻處理解決方案
【RTC程序設計:實時音視頻權威指南】音頻采集與預處理
【RTC程序設計:實時音視頻權威指南】新書一瞥
【RTC程序設計:實時音視頻權威指南】本書概覽
感知音頻質量分析POLQA測試方案





 工商網監
工商網監
評論