 深度學習將對音頻處理產生深遠影響 亞馬遜團隊深度噪聲抑制挑戰賽中獲勝
深度學習將對音頻處理產生深遠影響 亞馬遜團隊深度噪聲抑制挑戰賽中獲勝
該團隊的非實時系統是性能最好的,而它的實時系統在整個系統中排名第三,在實時系統中排名第二,盡管只使用了4%的CPU核心。
文 / Arvindh Krishnaswamy 原文鏈接: https://www.amazon.science/blog/amazon-team-takes-first-place-in-interspeech-2020-deep-noise-suppression-challenge
在電子語音通信中,噪音和混響不僅會損害語音清晰度,而且會導致聽者在長時間努力理解低質量語音時感到疲勞。在COVID-19大流行期間,我們花在遠程會議上的時間越來越多,這一問題比以往任何時候都更加重要。 在今年的Interspeech會議上的深度噪聲抑制挑戰便是為了幫助解決這個問題的一個嘗試,分別在實時語音增強和非實時語音增強上進行比賽。在19個團隊中,Amazon取得了最好的結果,在非實時賽道上獲得了第一名(階段1 |階段2-final),在實時賽道上獲得了第二名。
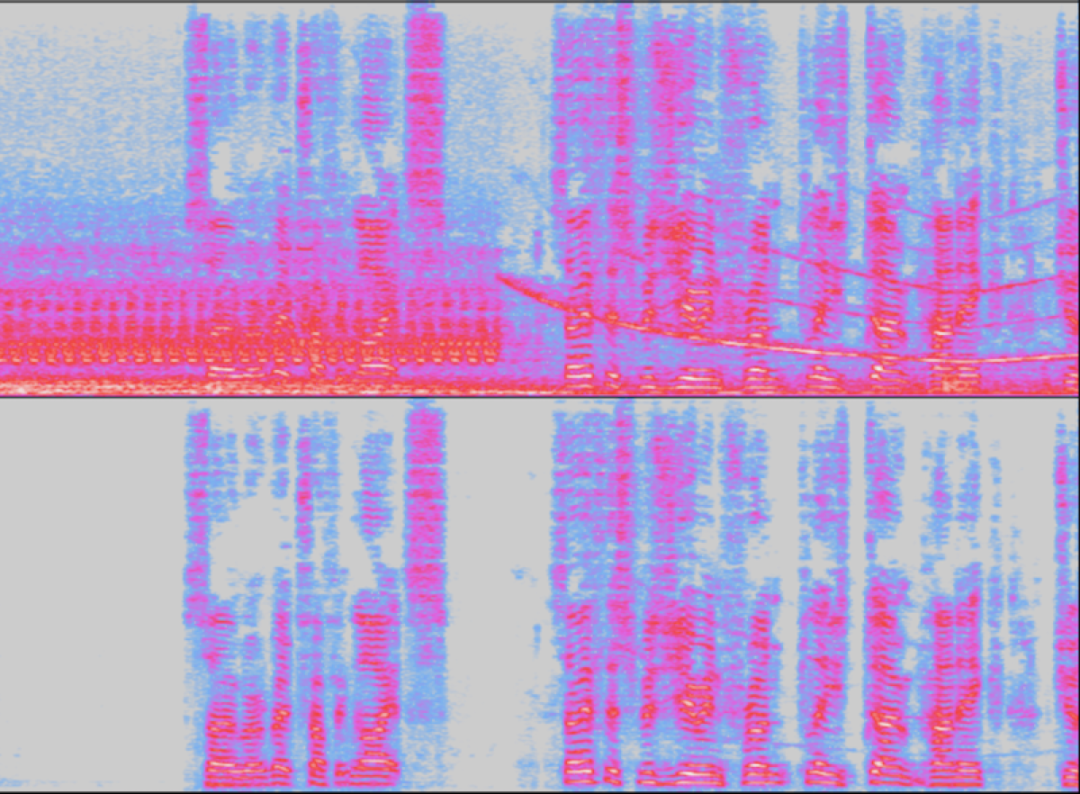
上面是一個有噪聲的語音樣本(上圖) 下面是被研究者的系統抑制了噪聲的同一個樣本(下圖) 為了滿足真實世界的需求,我們將實時輸入限制在CPU使用量的4%(在i7-8565U內核上測量),這遠遠低于競賽所允許的最大限度。 然而,我們的實時輸入非常接近(0.03平均意見分數)的第一名,并且擊敗了其他非實時的輸入。 Amazon團隊實時和非實時噪聲抑制結果的音頻示例可以在這里找到。 我們還發表了兩篇論文(paper1-offline | paper2-real)來更詳細地描述我們的技術方法。 在Interspeech中獲勝的技術已經在Alexa通信公告和Drop in Everywhere功能中發布,并且從今天開始,我們的客戶也可以通過使用Amazon Chime蘋果macOS和微軟Windows客戶端來進行視頻會議和在線會議。
優化的感知 傳統的語音增強算法使用人工調整的語音和噪聲模型,通常假設噪聲是恒定的。 對于某些類型的噪音(例如汽車噪音),在噪音不太大或低混響的環境下,這種方法工作得相當好。不幸的是,它們經常在非平穩噪音上失敗,比如鍵盤噪音和雜音。因此,研究人員轉向了深度學習方法。
語音增強不僅需要從噪音和混響中提取原始語音,而且需要以一種人類耳朵感覺自然和愉快的方式進行。這使得自動回歸測試變得困難,并使深度學習語音增強系統的設計復雜化。 我們的實時系統實際上通過直接優化了語音的感知特征(spectral envelope and voicing),利用了人類的感知因素同時忽略了與感知無關的方面。由此產生的算法產生了最先進的語音質量,同時保持非常高的計算效率。 對于非實時系統,我們采取了一種不妥協的方法,使用改進的U-Net深度卷積網絡從增強的語音壓縮每一點可能的質量,從而贏得了輸入挑戰。
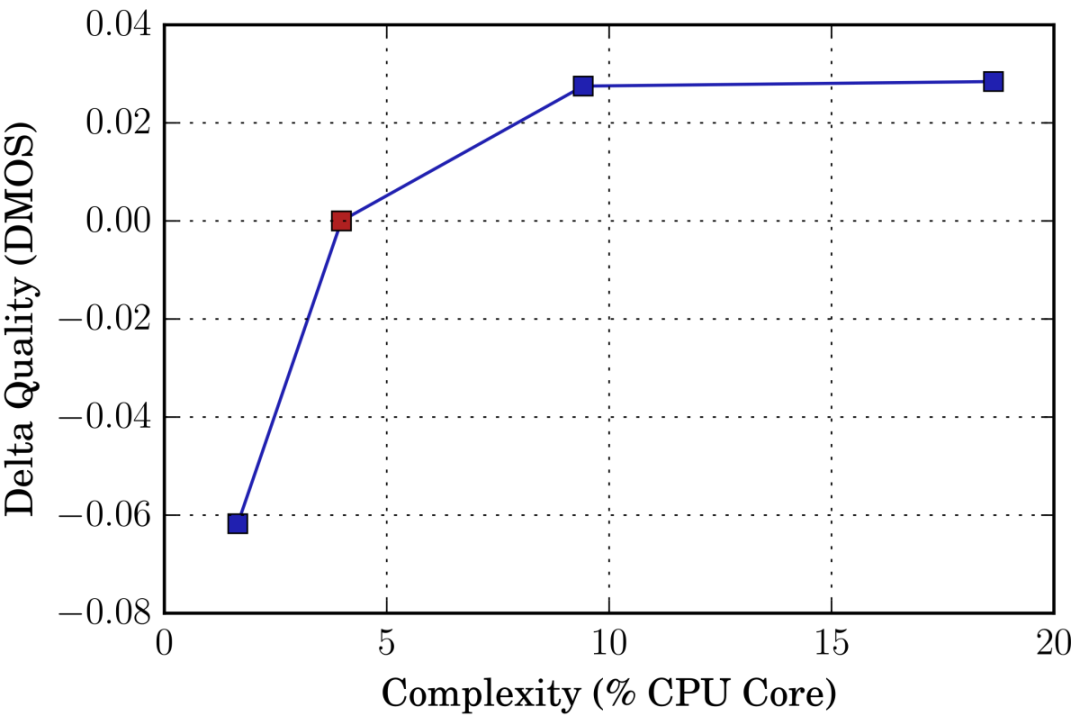
一描繪經被允許使用的研究人員的實時系統的百分比中央處理器核心降噪后的一語音樣本的平均意見分數(MOS)的變化的圖像 在深度噪聲抑制的挑戰中,經過處理的音頻示例被盲發送給人類聽眾,由他們對其進行評分,產生平均意見分數(MOS)。 在實時應用程序中,復雜性和質量之間總是需要權衡的。 右邊的圖顯示了我們如何通過增加CPU需求來進一步提高實時提交的質量,或者通過犧牲一些質量來進一步節省CPU的使用。 紅點表示提交挑戰的實時系統,圖像顯示了MOS分數相對于不同CPU負載的變化。
人們普遍認為,深度學習最終將對音頻處理產生深遠影響。 雖然仍有很多挑戰,比如數據增強,感知相關的損失函數或者處理看不見的情況,但未來依然非常令人興奮。
原文標題:亞馬遜團隊在Interspeech 2020深度噪聲抑制挑戰賽中獲得第一名
文章出處:【微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
-
cpu
+關注
關注
68文章
10825瀏覽量
211150 -
MOS
+關注
關注
32文章
1247瀏覽量
93477 -
噪音
+關注
關注
1文章
169瀏覽量
23879 -
亞馬遜
+關注
關注
8文章
2625瀏覽量
83192 -
深度學習
+關注
關注
73文章
5492瀏覽量
120977
原文標題:亞馬遜團隊在Interspeech 2020深度噪聲抑制挑戰賽中獲得第一名
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦







 工商網監
工商網監
評論