 TensorFlow 2:專為性能和易用性而設計
TensorFlow 2:專為性能和易用性而設計
衡量機器學習性能的業界標準 MLPerf(https://mlperf.org) 發布了 MLPerf Training v0.7 輪的最新基準測試結果。我們開心地與大家分享,Google 的提交結果展現出一流的性能(達到目標質量用時最短),能夠擴展至 4,000 多個加速器,并且在 Google Cloud 上為 TensorFlow 2 開發者提供了靈活的開發體驗。
在本文中,我們將探討 TensorFlow 2 MLPerf 提交結果,以及這些結果展示了企業如何在 Google Cloud 中尖端的 ML 加速器上運行 MLPerf 所代表的有價值的工作任務,如廣泛部署的幾代 GPU 和 Cloud TPU(
TensorFlow 2:專為性能和易用性而設計
在今年早些時候舉行的 TensorFlow 開發者峰會上,我們著重介紹了 TensorFlow 2 將注重易用性和實際性能。為爭取贏得基準測試,工程師們往往依賴于低階 API 調用和硬件專用的代碼,而這些在日常企業環境中可能很少見或不實用。借助 TensorFlow 2,我們的目標是通過更直接的代碼提供開箱即用的高性能,避免低級優化在代碼重用性、代碼運行狀況和工程效率方面帶來的重大問題。
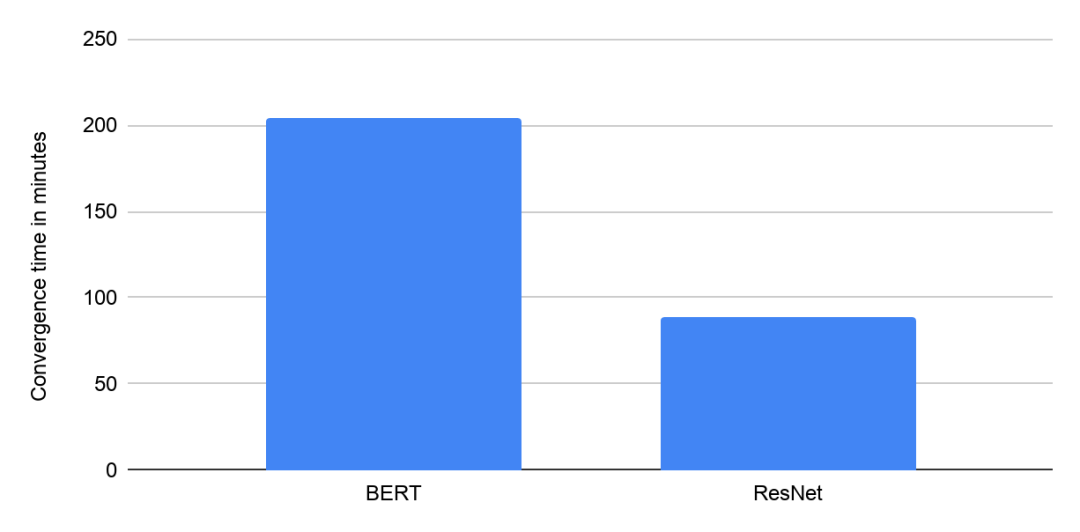
MLPerf Training v0.7 中 Google 使用帶 8 個 NVIDIA V100 GPU 的 Google Cloud VM 的收斂時間(分鐘)。提交結果在“可用”類別中
TensorFlow 的 Keras API(請參閱相關的一系列指南)支持多種硬件架構,提供了易用性和可移植性。例如,模型開發者可以使用 Keras 混合精度 API 和 Distribution Strategy API 來使同一代碼庫盡可能在多個硬件平臺上流暢運行。Google 的“云端可用”類別中的 MLPerf 提交結果是由這些 API 實現的。這些提交結果證明了使用高階 Keras API 編寫的幾乎相同的 TensorFlow 代碼可以在業界兩個領先的廣泛可用的 ML 加速器平臺上提供高性能使用體驗:NVIDIA 的 V100 GPU 和 Google 的 Cloud TPU v3 Pod。
指南
https://tensorflow.google.cn/guide/keras/sequential_model
Keras混合精度 API
https://tensorflow.google.cn/guide/keras/mixed_precision
Distribution Strategy API
https://tensorflow.google.cn/guide/distributed_training
注:圖表中顯示的所有結果均于 2020 年 7 月 29 日從 www.mlperf.org 中獲取。MLPerf 名稱和徽標為商標。有關詳細信息,請訪問 www.mlperf.org。顯示的結果:0.7-1 和 0.7-2。
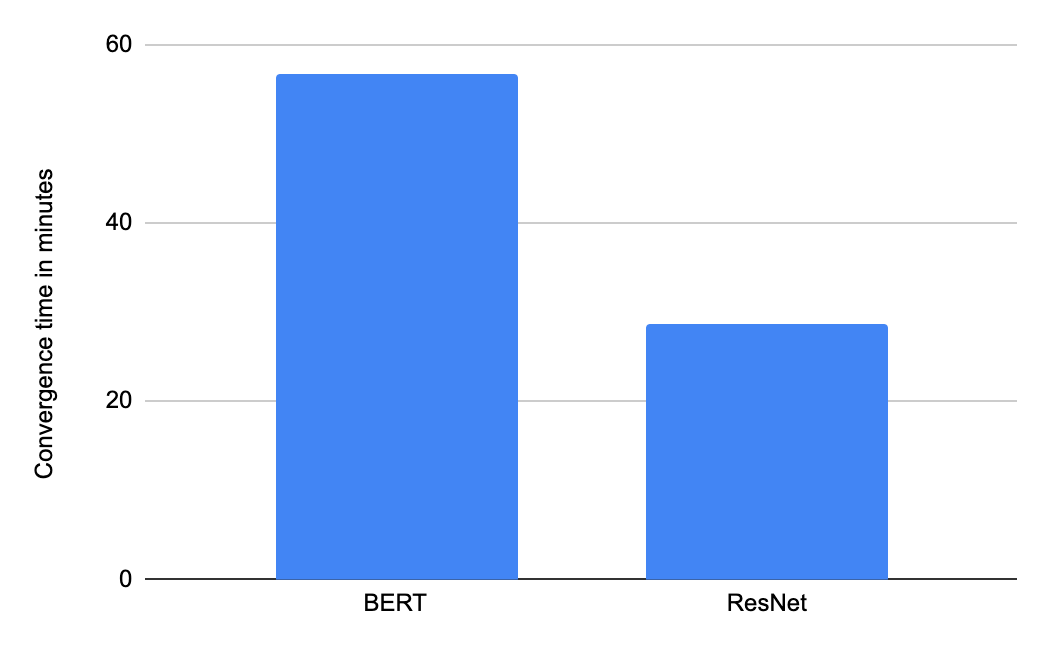
MLPerf Training v0.7 中使用含 16 個 TPU 芯片的 Google Cloud TPU v3 Pod 切片的收斂時間(分鐘)。提交結果在“可用”類別中
深入了解:借助 XLA 提升性能
Google 提交的在 GPU 和 Cloud TPU Pod 上的測試結果使用了 XLA 編譯器來優化 TensorFlow 性能。XLA 是 TPU 編譯器技術棧的核心部分,可以選擇性地為 GPU 啟用。XLA 是一個基于圖模型的即時編譯器,用于執行各種不同類型的全程序優化,包括 ML 運算的廣泛 融合 。
XLA 編譯器
https://tensorflow.google.cn/xla
算子融合降低了 ML 模型對存儲容量和帶寬的要求。此外,融合減少了運算的啟動開銷,尤其是在 GPU 上。總體而言,XLA 優化具有通用性和可移植性,與 cuDNN 和 cuBLAS 庫的互操作性十分出色,并且通常可以作為手動編寫低級內核的有力替代方案。
Google 的“云端可用”類別中的 TensorFlow 2 提交結果使用了 TensorFlow 2.0 中引入的 @tf.function API。@tf.function API 提供了一種簡單的方法來有選擇地啟用 XLA,從而可以精確控制將要編譯的函數。
啟用 XLA
https://www.tensorflow.org/xla/tutorials/compile
XLA 帶來的性能提升令人贊嘆:在連接 8 個 Volta V100 GPU(每個具有 16 GB GPU 內存)的 Google Cloud VM 上,XLA 將 BERT訓練吞吐量從每秒 23.1 個序列提高到每秒 168 個序列,提升了約 7 倍。XLA 還使每個 GPU 的可運行批次大小增加了 5 倍。XLA 減少了內存使用量,因此使得高級訓練技術(如梯度積累)的使用成為可能。
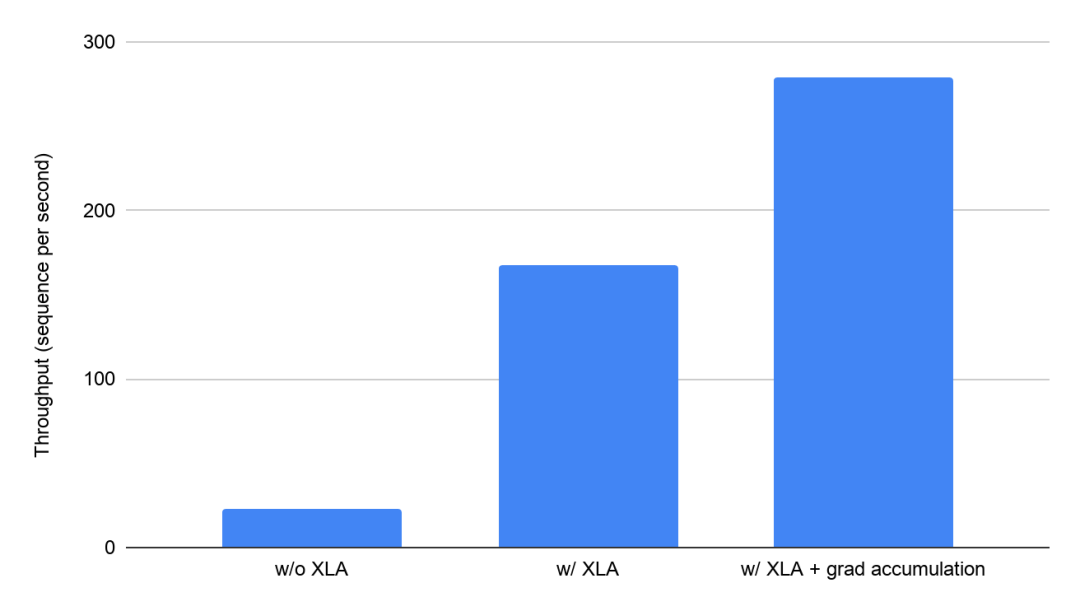
在 Google Cloud 上使用 8 個 V100 GPU 的 BERT 模型中啟用 XLA 的影響(分鐘)(Google 在 MLPerf Training 0.7 中提交的測試結果)與停用優化條件下同一系統中未經驗證的 MLPerf 結果
Google Cloud 上最先進的加速器
Google Cloud 是唯一支持訪問最新 GPU 和 Cloud TPU 的公共云平臺,使 AI 研究人員和數據科學家可以自由地為每個任務選擇合適的硬件。
GPU
https://cloud.google.com/blog/products/compute/announcing-google-cloud-a2-vm-family-based-on-nvidia-a100-gpu
Cloud TPU
https://cloud.google.com/tpu/
BERT 等前沿模型已在 Google 內廣泛使用,并在整個行業范圍內用于各種自然語言處理任務,現在可以使用訓練 Google 內部工作任務所用的基礎架構在 Google Cloud 上進行訓練。借助 Google Cloud,您可以在一個小時內在具有 16 個 TPU 芯片的 Cloud TPU v3 Pod 切片上將 BERT 訓練 300 萬個序列,總成本不到 32 美元。
BERT
https://github.com/tensorflow/models/blob/master/official/benchmark/bert_benchmark.py
結論
Google 的 MLPerf 0.7 訓練提交結果展示了 TensorFlow 2 在最新的 ML 加速器硬件上的性能、易用性和可移植性。立即開始,體驗 TensorFlow 2 在 Google Cloud GPU、Google Cloud TPU 和具有 Google Cloud Deep Learning VM 的 TensorFlow Enterprise 上的易用性和功能。
致謝
GPU 的 MLPerf 提交結果離不開與 NVIDIA 的密切協作。NVIDIA 的所有工程師都為提交測試結果提供了幫助,在此一并表示感謝。
-
機器學習
+關注
關注
66文章
8379瀏覽量
132425 -
tensorflow
+關注
關注
13文章
329瀏覽量
60499
原文標題:TensorFlow 2 MLPerf 提交結果在 Google Cloud 上展現出同類最佳性能
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
11-06-CBM94AD67【中文排版】-202402221530
專為運行而設計:使用bq2018電源管理器IC的通用電池監控器

Bourns 推出符合 AEC-Q200 標準高壓氣體放電管 (GDT) 專為滿足嚴苛的可靠性、耐用性和法規標準而設計

中科創達旗下創通聯達Qualcomm RB3 Gen 2 Lite開發套件上市銷售
TensorFlow是什么?TensorFlow怎么用?
tensorflow和pytorch哪個更簡單?
tensorflow和pytorch哪個好
SOLIDWORKS教育版本的易用性
新品 | Prime Block 50mm——專為實現最高性能而設計

論RISC-V的MCU中UART接口的重要性
基于 GaN 的 MOSFET 如何實現高性能電機逆變器

溫度測試儀的穩定性和易用性





 工商網監
工商網監
評論