 for竟然有那么多種用法!
for竟然有那么多種用法!
【說在前面的話】
通過本系列前面兩篇文章的學習,我們掌握了宏的基本語法和使用規則,諷刺的是這些所謂的“基本語法和規則”卻恰恰是正規C語言教育中所缺失的。本文的內容將建立在前面構筑的基礎之上,以for功能的挖掘和封裝為契機,手把手的教會你如何正確使用宏來簡化日常開發,增強C語言的可讀性、降低應用開發的難度、同時還盡可能避免宏對日常代碼調試帶來的負面影響。
【被低估的價值】
想必大家對C語言中的 for 循環結構并不陌生。根據C/C++語法網站cppreference.com 的介紹,for 的語法結構如下:
for ( init_clause ; cond_expression ; iteration_expression ) loop_statement
這里,我并不想假設大家對 for 結構一無所知,并介紹一堆教科書上已有的內容。然而,在 for 的語法結構中有幾個大家容易忽視的地方,而它們恰恰是本文后續各種“展開”的基礎:
for 循環中的 cond_expression 和 interation_expression 都必須是表達式,而不能是直接的語句。
for 循環中第一個部分 init_clause 一開始是用來放置給變量賦值的表達式;但從ANSI-C99開始,init_clause 可以被用來建立局部變量;而局部變量的生命周期覆蓋且僅覆蓋整個for循環——這一點非常有利用價值,也是大家容易忽略的地方。
為了說明這一點,我們不妨舉幾個例子。首先在C99標準之前,如果你要在 for 循環中使用一個循環變量,你只能在進入 for 之前將其定義好:
int i = 0;。..for (i = 0; i 《 100; i++) { 。..}
如你所見,雖然我們可以在 init_clause 的位置對變量賦值,但它并不是必須的——多少一點雞肋是不是?也許更雞肋的是,你可以在 init_clause 這里完成更多的賦值操作,比如:
int i = 0, j,k;。..for (i = 0, j = 100, k = 1; i 《 100; i++) { 。..}
實際上,明眼人都可以看出,init_clause 中所作的事情完全可以放置到 for 循環之前去完成,還可以避免“使用逗號進行分隔” 這樣讓人不那么習慣的使用方式。也許是意識到這一點,C99允許在 init_clause 里定義局部變量,而正是這一點,完全改變了 for 的命運(關于這一點,我們將在隨后的內容中詳細介紹)。現在,上述代碼可以等效的改寫為:
for (int i = 0, j = 100, k = 1; i 《 100; i++) { 。..}
需要強調的是,這里仍然有一個小小的限制,即:init_clause 里雖然可以定義局部變量,但這些變量只能是同一類型的,或者是指向這一類型的指針。因此下面的寫法是非法的:
for (int i = 0, short j = 100; i 《 100; i++) { 。..}
而這樣的寫法是合法的:
for (int i = 0, *p = NULL; i 《 100; i++) { 。..}
請大家務必留意這里的語法細節,我們將在后面的封裝中大規模使用。
另外一個值得注意的是 for 的執行順序,它可以用下面的流程圖來表示:
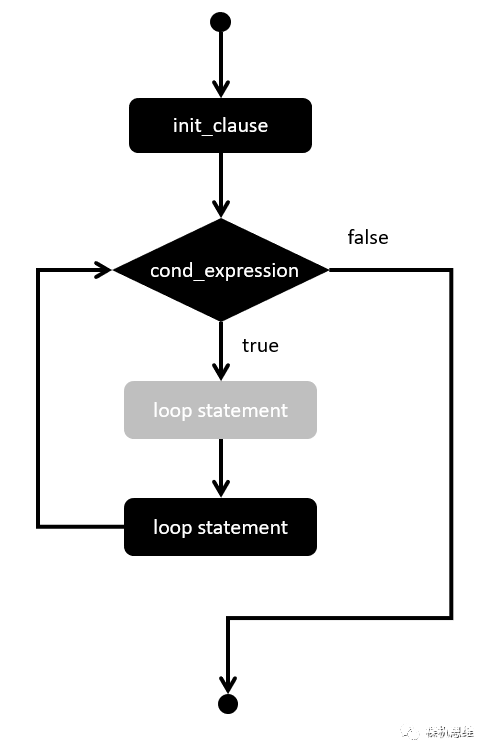
容易發現,經過必要的“構造”,我們可以恰好實現一個如同 do { } while(0) 一樣的效果:
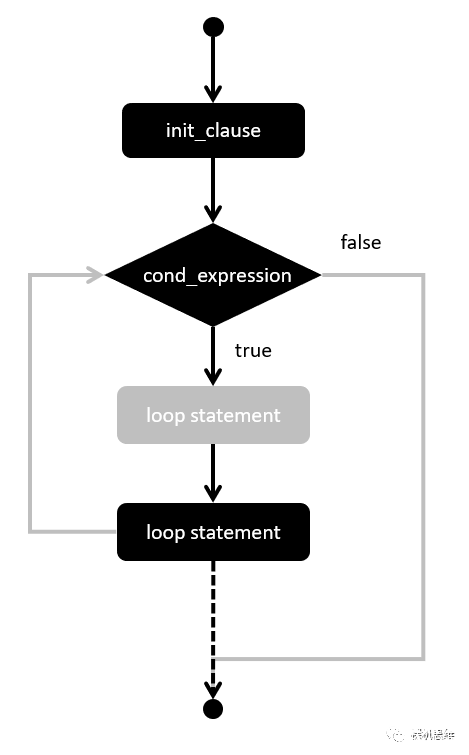
圖中灰色的部分為原本實際的執行流程,而純黑色的線條以及最下方的虛線箭頭則為等效的運行流程。與do {} while(0) 相比,在我們眼中 for 循環的幾個關鍵部分就有了新的意義:
在執行用戶代碼之前(灰色部分),有能力進行一定的“準備工作”(Before部分);
在執行用戶代碼之后,有能力執行一定的“收尾工作”(After部分)
在init_clause階段有能力定義一個“僅僅只覆蓋” for 循環的,并且只對 User Code可見的局部變量——換句話說,這些局部變量是不會污染 for 循環以外的地方的。
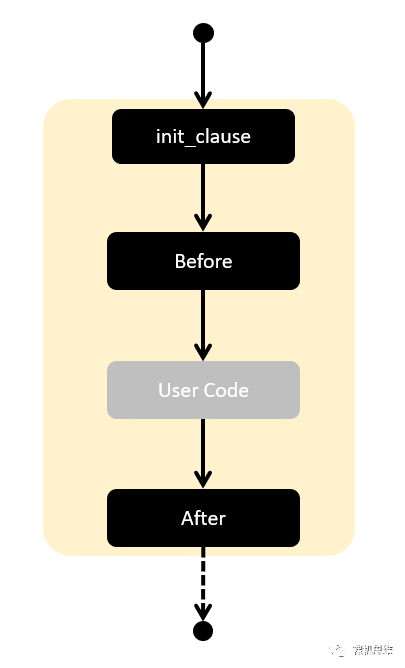
【構造using結構】
上面所提到的結構,在C#中有一個類似的語法,叫做 using(),其典型的用法如下:
using (StreamReader tReader = File.OpenText(m_InputTextFilePath)){ while (!tReader.EndOfStream) { 。.. }}
以上述代碼為例進行講解:
在 using 圓括號內定義的變量,其生命周期僅覆蓋 using 緊隨其后的花括號內部;
當用于代碼離開 using 結構的時候,using 會自動執行一個“掃尾工作”,而這個掃尾工作是對應的類事先定義好的。在上述例子中,所謂的掃尾工作就是關閉 與 類StreamReader的實例tReader 所關聯的文件——簡單說就是using會自動把文件關閉,而不必用戶親自動手。
是不是聞到了熟悉的味道?不要搞錯因果關系——我們正是對C#中的using結構“甚是眼饞”才決定自己動手,用 for 來創造一個——現有C#的using結構才有我們后面的嘗試。下圖是using所等校流程圖,可以看到他比我們此前的結構還少了一個“Before”部分:

要實現類似using的結構,首先要考慮如何構造一個“至執行一次”的for循環結構。要做到這一點,毫無難度:
for (int i = 1; i 》 0; i++) { 。..}
以此為起點,對比我們的“藍圖”,發現至少有以下幾個問題:
如何實現 before和after的部分?
現在用的變量 i 固定是 int 類型的,如何允許用戶在 init_clause 定義自己的局部變量,并允許使用自己的類型?
問題一:如何實現 before 和 after 部分
對比前面的圖例,我們知道 before 和 after 的部分實際上分別對應 for 循環的 cond_expression 和 iteration_expression;同時,這兩個部分都必須是表達式——由于表達式的限制,能插入在 before 和 after 部分的內容實際上就只能是“普通表達式”或者是“函數”。
由于我們還必須至少借助 cond_expression 來實現 “只運行一次” 的功能,如何見縫插針的實現 before 的功能呢?不繞彎子,看代碼:
//! 假設用戶要插入的內容我們都放在叫做 before 和after的函數里extern void before(void);extern void after(void);for (int i = 1; //!《 init_clause i--?(before(),1):0; //!《 cond_expression after()) //!《 iteration_expression{ 。..}
我們知道,cond_expression 只在乎用戶表達式的返回值是0還是非0,因此,這里其實真正起作用的本體是 “i--”——第一次判斷的時候返回值是1,由于自減操作,第二次判斷的時候就是0了——這就完成了讓 for 運行且只運行一次的功能。
接下來,我們借助一個問好表達式,嘗試給 i-- 的結果做一個等效“解釋”,即:
(i--) ? 1 : 0
用人話說就是,如果 (i--)值是非0的,我們就返回1,反之返回0。這么做的意義是為了進一步通過逗號表達式對 “1” 所在的部分進行擴展:
(i--) ? (before(), 1) //!《 使用逗哈表達式進行擴展: 0
由于逗號表達式只管 最右邊的結果,忽略所有左邊的返回值,因此,哪怕before()函數沒有實際返回值對C編譯器來說都是無所謂的。同理,由于我們在cond_expression部分已經完成了所有功能,因此 iteration_expression 就任由我們宰割了——編譯器原本就對此處表達式所產生的數值并不感興——我們直接放下 after() 函數即可。
至此,插入 before() 和 after() 的問題圓滿解決。
問題二:如何允許用戶定義自己的局部變量,并且擁有自己的類型
要解決這個問題,首先必須打破定勢思維,即:for循環只能用整型變量。實際并非如此,對for來說真正起作用的只有 cond_expression 的返回值,而它只關心用戶的表達式返回的 布爾量 是什么——換句話說,有無數種方法來產生 cond_expression,而使用普通的整形計數器,并對其進行判斷只是眾多方法中的一種。
打破了這一定勢思維后,我們就從問題本身出發考慮:允許用戶用自己的類型定義自己的變量——雖然看似我們并不能知道用戶會用什么類型來定義變量,因而就無法寫出通用的 cond_expression 來實現“讓for執行且執行一次”的功能,然而,你們也許忘記了 init_clause 的一個特點:它還可以定義指針——換句話說,無論用戶定義了什么類型,我們都可以在最后定義一個指向該類型的指針:
#define using(__declare, __on_enter_expr, __on_leave_expr) \ for (__declare, *_ptr = NULL; \ _ptr++ == NULL ? \ ((__on_enter_expr),1) : 0; \ __on_leave_expr \ )
為了驗證我們的結果,不妨寫一個簡單的代碼:
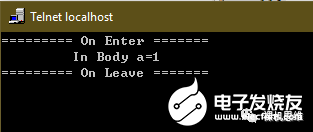
using(int a = 0,printf(“========= On Enter =======\r\n”), printf(“========= On Leave =======\r\n”)) { printf(“\t In Body a=%d \r\n”, ++a);}
這是對應的執行效果:
我們不妨將上述的宏進行展開,一個可能的結果是:
for (int a = 0, *_ptr = NULL; _ptr++ == NULL ? ((printf(“========= On Enter =======\r\n”)),1) : 0; printf(“========= On Leave =======\r\n”) ) { printf(“\t In Body a=%d \r\n”, ++a);}
從 init_clause 的展開結果來看,完全符合要求:
int a = 0, *_ptr = NULL;
接下來,為了提高宏的魯棒性,我們可以繼續做一些改良,比如給指針一個唯一的名字:
#define using(__declare, __on_enter_expr, __on_leave_expr) \ for (__declare, *CONNECT3(__using_, __LINE__,_ptr) = NULL; \ CONNECT3(__using_, __LINE__,_ptr)++ == NULL ? \ ((__on_enter_expr),1) : 0; \ __on_leave_expr \ )
這里,實際上是使用了前面文章中介紹的宏 CONNECT3() 將 “__using_”,__LINE__所表示的當前行號,以及 “_ptr” 粘連在一起,形成一個唯一的局部變量名:
CONNECT3(__using_, __LINE__,_ptr)
如果你對 CONNECT() 宏的來龍去脈感興趣,可以單擊這里。
更進一步,如果用戶有不同的需求:比如想定義兩個以上的局部變量,或是想省確 __on_enter_expr 或者是 __on_leave_expr ——我們完全可以定義多個不同版本的 using:
#define __using1(__declare) \ for (__declare, *CONNECT3(__using_, __LINE__,_ptr) = NULL; \ CONNECT3(__using_, __LINE__,_ptr)++ == NULL; \ )#define __using2(__declare, __on_leave_expr) \ for (__declare, *CONNECT3(__using_, __LINE__,_ptr) = NULL; \ CONNECT3(__using_, __LINE__,_ptr)++ == NULL; \ __on_leave_expr \ )#define __using3(__declare, __on_enter_expr, __on_leave_expr) \ for (__declare, *CONNECT3(__using_, __LINE__,_ptr) = NULL; \ CONNECT3(__using_, __LINE__,_ptr)++ == NULL ? \ ((__on_enter_expr),1) : 0; \ __on_leave_expr \ )#define __using4(__dcl1, __dcl2, __on_enter_expr, __on_leave_expr) \ for (__dcl1, __dcl2, *CONNECT3(__using_, __LINE__,_ptr) = NULL; \ CONNECT3(__using_, __LINE__,_ptr)++ == NULL ? \ ((__on_enter_expr),1) : 0; \ __on_leave_expr \ )
借助宏的重載技術,我們可以根據用戶輸入的參數數量自動選擇正確的版本:
#define using(。..) \ CONNECT2(__using, VA_NUM_ARGS(__VA_ARGS__))(__VA_ARGS__)
至此,我們完成了對 for 的改造,并提出了__using1, __using2, __using3 和 __using4 四個版本變體。那么問題來了,他們分別有什么用處呢?
【提供不阻礙調試的代碼封裝】
前面的文章中,我們曾有意無意的提供過一個實現原子操作的封裝:即在代碼的開始階段關閉全局中斷并記錄此前的中斷狀態;執行用戶代碼后,恢復關閉中斷前的狀態。其代碼如下:
#define SAFE_ATOM_CODE(。..) \{ \ uint32_t CONNECT2(temp, __LINE__) = __disable_irq(); \ __VA_ARGS__ \ __set_PRIMASK((CONNECT2(temp, __LINE__))); \}
因此可以很容易的通過如下的代碼來保護關鍵的寄存器操作:
/** \fn void wr_dat (uint16_t dat) \brief Write data to the LCD controller \param[in] dat Data to write*/static __inline void wr_dat (uint_fast16_t dat) { SAFE_ATOM_CODE ( LCD_CS(0); GLCD_PORT-》DAT = (dat 》》 8); /* Write D8..D15 */ GLCD_PORT-》DAT = (dat & 0xFF); /* Write D0..D7 */ LCD_CS(1); )}
唯一的問題是,這樣的寫法,在調試時完全沒法在用戶代碼處添加斷點(編譯器會認為宏內所有的內容都寫在了同一行),這是大多數人不喜歡使用宏來封裝代碼結構的最大原因。借助 __using2,我們可以輕松的解決這個問題:
#define SAFE_ATOM_CODE() \ __using2( uint32_t CONNECT2(temp,__LINE__) = __disable_irq(), \ __set_PRIMASK(CONNECT2(temp,__LINE__)))
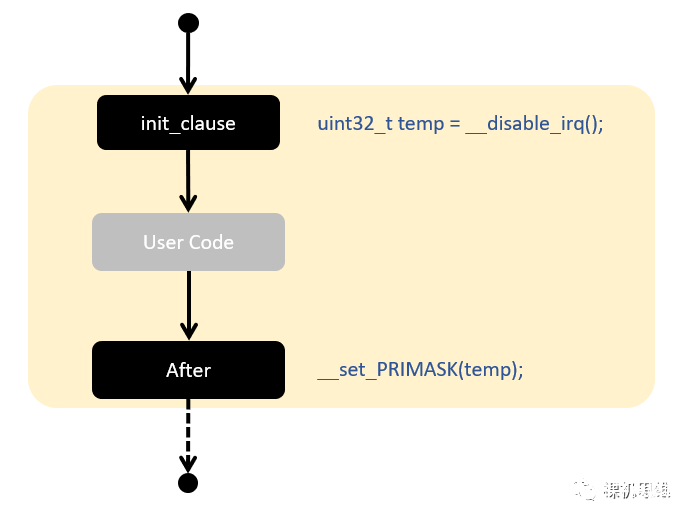
修改上述的代碼為:
static __inline void wr_dat (uint_fast16_t dat) { SAFE_ATOM_CODE() { LCD_CS(0); GLCD_PORT-》DAT = (dat 》》 8); /* Write D8..D15 */ GLCD_PORT-》DAT = (dat & 0xFF); /* Write D0..D7 */ LCD_CS(1); }}
由于using的本質是 for 循環,因為我們可以通過花括號的形式來包裹用戶代碼,因此,可以很方便的在用戶代碼中添加斷點,單步執行。至于原子保護的功能,我們不妨將上述代碼進行宏展開:
static __inline void wr_dat (uint_fast16_t dat){ for (uint32_t temp154 = __disable_irq(), *__using_154_ptr = NULL; __using_154_ptr++ == NULL ? ((temp154 = temp154),1) : 0; __set_PRIMASK(temp154) ) { LCD_CS(0); GLCD_PORT-》DAT = (dat 》》 8); GLCD_PORT-》DAT = (dat & 0xFF); LCD_CS(1); }}
通過觀察,容易發現,這里巧妙使用 init_clause 給 temp154 變量進行賦值——在關閉中斷的同時保存了此前的狀態;并在原本 after 的位置放置了 恢復中斷的語句 __set_PRIMASK(temp154)。
舉一反三,此類方法除了用來開關中斷以外,還可以用在以下的場合:
在OOPC中自動創建類,并使用 before 部分來執行構造函數;在 after 部分完成 類的析構。
在外設操作中,在 init_clause 部分定義指向外設的指針;在 before部分 Enable或者Open外設;在after部分Disable或者Close外設。
在RTOS中,在 before 部分嘗試進入臨界區;在 after 部分釋放臨界區
在文件操作中,在 init_clause 部分嘗試打開文件,并獲得句柄;在 after 部分自動 close 文件句柄。
在有MPU進行內存保護的場合,在 before 部分,重新配置MPU獲取目標地址的訪問權限;在 after部分再次配置MPU,關閉對目標地址范圍的訪問權限。
……
【構造with塊】
不知道你們在實際應用中有沒有遇到一連串指針訪問的情形——說起來就好比是:
你鄰居的-》朋友的-》親戚家的-》一個狗的-》保姆的-》手機
如果我們要操作這里的“手機”,實在是不想每次都寫這么一長串“惡心”的東西,為了應對這一問題,Visual Basic(其實最早是Quick Basic)引入了一個叫做 WITH 塊的概念,它的用法如下:
WITH 你鄰居的-》朋友的-》親戚家的-》一個狗的-》保姆的-》手機 # 這里可以直接訪問手機的各項屬性,用 “。” 開頭就行 。 手機殼顏色 = xxxxx 。 貼膜 = 玻璃膜END WITH
不光是Visual Basic,我們使用C語言進行大規模的應用開發時,或多或少也會遇到同樣的情況,比如,配置 STM32 外設時,填寫外設配置結構體的時候,每一行都要重新寫一遍結構體變量的名字,也是在是很繁瑣:
static UART_HandleTypeDef s_UARTHandle = UART_HandleTypeDef(); s_UARTHandle.Instance = USART2; s_UARTHandle.Init.BaudRate = 115200; s_UARTHandle.Init.WordLength = UART_WORDLENGTH_8B; s_UARTHandle.Init.StopBits = UART_STOPBITS_1; s_UARTHandle.Init.Parity = UART_PARITY_NONE; s_UARTHandle.Init.HwFlowCtl = UART_HWCONTROL_NONE; s_UARTHandle.Init.Mode = UART_MODE_TX_RX;
入股有了with塊的幫助,上述代碼可能就會變得更加清爽,比如:
static UART_HandleTypeDef s_UARTHandle = UART_HandleTypeDef();with(s_UARTHandle) { .Instance = USART2; .Init.BaudRate = 115200; .Init.WordLength = UART_WORDLENGTH_8B; .Init.StopBits = UART_STOPBITS_1; .Init.Parity = UART_PARITY_NONE; .Init.HwFlowCtl = UART_HWCONTROL_NONE; .Init.Mode = UART_MODE_TX_RX;}
遺憾的是,如果要完全實現上述的結構,在C語言中是不可能的,但借助我們的 using() 結構,我們可以做到一定程度的模擬:
#define with(__type, __addr) using(__type *_p=(__addr))#define _ (*_p)
在這里,我們要至少提供目標對象的類型,以及目標對象的地址:
static UART_HandleTypeDef s_UARTHandle = UART_HandleTypeDef();with(UART_HandleTypeDef &s_UARTHandle) { _.Instance = USART2; _.Init.BaudRate = 115200; _.Init.WordLength = UART_WORDLENGTH_8B; _.Init.StopBits = UART_STOPBITS_1; _.Init.Parity = UART_PARITY_NONE; _.Init.HwFlowCtl = UART_HWCONTROL_NONE; _.Init.Mode = UART_MODE_TX_RX;}
注意到,這里“_”實際上被用來替代 s_UARTHandle——雖然感覺有點不夠完美,但考慮到腳本語言 perl 有長期使用 “_” 表示本地對象的傳統,這樣一看,似乎“_” 就是一個對 “perl” 的完美致敬了。
【回歸本職 foreach】
很多高級語言都有專門的 foreach 語句,用來實現對數組(或是鏈表)中的元素進行逐一訪問。原生態C語言并沒有這種奢侈,即便如此,Linux也定義了一個“野生”的 foreach 來實現類似的功能。為了演示如何使用 using 結構來構造 foreach,我們不妨來看一個例子:
typedef struct example_lv0_t { uint32_t wA; uint16_t hwB; uint8_t chC; uint8_t chID;} example_lv0_t;example_lv0_t s_tItem[8] = { {.chID = 0}, {.chID = 1}, {.chID = 2}, {.chID = 3}, {.chID = 4}, {.chID = 5}, {.chID = 6}, {.chID = 7},};
我們希望實現一個函數,能通過 foreach 自動的訪問數組 s_tItem 的所有成員,比如:
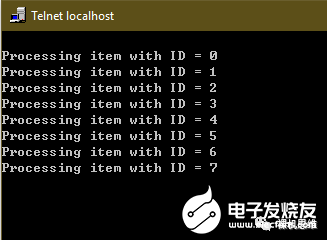
foreach(example_lv0_t, s_tItem) { printf(“Processing item with ID = %d\r\n”, _.chID);}
跟With塊一樣,這里我們仍然“致敬” perl——使用 “_” 表示當前循環下的元素。在這個例子中,為了使用 foreach,我們需要提供至少兩個信息:目標數組元素的類型(example_lv0_t)和目標數組(s_tItem)。
這里的難點在于,如何定義一個局部的指針,并且它的作用范圍僅僅只覆蓋 foreach 的循環體。此時,坐在角落里的 __with1() 按耐不住了,高高的舉起了雙手——是的,它僅有的功能就是允許用戶定義一個局部變量,并覆蓋由第三方所編寫的、由 {} 包裹的區域:
#define dimof(__array) (sizeof(__array)/sizeof(__array[0]))#define foreach(__type, __array) \ __using1(__type *_p = __array) \ for ( uint_fast32_t CONNECT2(count,__LINE__) = dimof(__array); \ CONNECT2(count,__LINE__) 》 0; \ _p++, CONNECT2(count,__LINE__)-- \ )
上述的宏并不復雜,大家完全可以自己看懂,唯一需要強調的是,using() 的本質是一個for,因此__using1() 下方的for 實際上是位于由 __using1() 所提供的循環體內的,也就是說,這里的局部變量_p其作用域也覆蓋 下面的for 循環,這就是為什么我們可以借助:
#define _ (*_p)
的巧妙代換,通過 “_” 來完成對指針“_p”的使用。為了方便大家理解,我們不妨將前面的例子代碼進行宏展開:
for (example_lv0_t *_p = s_tItem, *__using_177_ptr = NULL; __using_177_ptr++ == NULL ? ((_p = _p),1) : 0; ) for ( uint_fast32_t count177 = (sizeof(s_tItem)/sizeof(s_tItem[0])); count177 》 0; _p = _p+1, count177-- ) { printf(“Processing item with ID = %d\r\n”, (*_p).chID); }
其執行結果為:
foreach目前的用法看起來“歲月靜好”,似乎沒有什么問題,可惜的是,一旦進行實際的代碼編寫,我們會發現,假如我們要在 foreach 結構中再用一個foreach,或是在foreach中使用 with 塊,就會出現 “_” 被覆蓋的問題——也就是在里層的 foreach或是 with 無法通過 “_” 來訪問外層“_” 所代表的對象。為了應對這一問題,我們可以對 foreach 進行一個小小的改造——允許用戶再指定一個專門的局部變量,用于替代“_” 表示當前循環下的對象:
#define foreach2(__type, __array) \ using(__type *_p = __array) \ for ( uint_fast32_t CONNECT2(count,__LINE__) = dimof(__array); \ CONNECT2(count,__LINE__) 》 0; \ _p++, CONNECT2(count,__LINE__)-- \ )#define foreach3(__type, __array, __item) \ using(__type *_p = __array, *__item = _p, _p = _p, ) \ for ( uint_fast32_t CONNECT2(count,__LINE__) = dimof(__array); \ CONNECT2(count,__LINE__) 》 0; \ _p++, __item = _p, CONNECT2(count,__LINE__)-- \ )
這里的 foreach3 提供了3個參數,其中最后一個參數就是用來由用戶“額外”指定新的指針的;與之相對,老版本的foreach我們稱之為 foreach2,因為它只需要兩個參數,只能使用“_”作為對象的指代。進一步的,我們可以使用宏的重載來簡化用戶的使用:
#define foreach(。..) \ CONNECT2(foreach, VA_NUM_ARGS(__VA_ARGS__))(__VA_ARGS__)
經過這樣的改造,我們可以用下面的方法來為我們的循環指定一個叫做“ptItem”的指針:
foreach(example_lv0_t, s_tItem, ptItem) { printf(“Processing item with ID = %d\r\n”, ptItem-》chID);}
展開后的形式如下:
for (example_lv0_t *_p = s_tItem, ptItem = _p, *__using_177_ptr = NULL; __using_177_ptr++ == NULL ? ((_p = _p),1) : 0; ) for ( uint_fast32_t count177 = (sizeof(s_tItem)/sizeof(s_tItem[0])); count177 》 0; _p = _p+1, ptItem = _p, count177-- ) { printf(“Processing item with ID = %d\r\n”, ptItem-》chID); }
代碼已經做了適當的展開和縮進,這里就不作進一步的分析了。
【后記】
本文的目的,算是對【為宏正名】系列所介紹的知識進行一次示范——告訴大家如何正確的使用宏,配合已有的老的語法結構來“固化”一個新的模板,并以這個模板為起點,理解它的語法意義和用戶,簡化我們的日常開發。在這篇文章中,老的語法結構就是 for,它是由C語言原生支持的,借助宏,我們封裝了一個新的語法結構 using(), 借助它的4種不同形式、理解它們各自的特點,我們又分別封裝了非常實用的SAFE_ATOM_CODE(),With塊和foreach語法結構——他們的存在至少證明了以下幾點:
宏不是奇技淫巧
宏可以封裝出其它高級語言所提供的“基礎設施”
設計良好的宏可以提升代碼的可讀性,而不是破壞它
設計良好的宏并不會影響調試
宏可以用來固化某些模板,避免每次都重新編寫復雜的語法結構,在這里,using() 模板的出現,避免了我們每次都重復通過原始的 for 語句來構造所需的語法結構,極大的避免了重復勞動,以及由重復勞動所帶來的出錯風險
-
for
+關注
關注
0文章
44瀏覽量
15797 -
宏匯編器
+關注
關注
0文章
7瀏覽量
8981
發布評論請先 登錄
相關推薦
PCM1792ADBR輸出噪聲大的原因?怎么解決?
零歐姆電阻有哪些用法
為什么total noise在1K左右的位置INA118比INA333多出那么多倍不是更低的噪聲嗎?
設計的放大器在無電源供電下,輸入進電壓信號,竟然有輸出,為什么?
使用運放THS4631設計一款如附件所示的功率放大電路,上電后,運放芯片劇烈發燙怎么解決?
INA333輸入電壓范圍在0~48V時,輸出電壓VIN0和VIN2的電壓均為0,為什么?
INA301為什么在共模信號給到5V多一點點的時候,偏置電流會突然變大那么多?
FX3使用DMA模式的話,有什么方法可以讓我獲得串口接收到的數據?
HAL庫的串口收發函數,HAL的串口DMA方式下不能實現獨立的全雙工通信嗎?

電抗器竟然有那么多的種類和特性






 工商網監
工商網監
評論