 匿名和去識別化在數據隱私保護方面的重要性
匿名和去識別化在數據隱私保護方面的重要性
匿名化是為了確保數據的隱私性,公司用它來保護敏感數據。這類數據包括:
私人數據
業務信息,如財務信息或商業秘密
機密信息,如軍事機密或政府信息
匿名化為遵循個人數據相關隱私條例提供了范例,個人數據和業務數據的重合之處就是客戶信息所在。但并非所有的業務數據都受監管,本文將重點討論個人數據的保護。
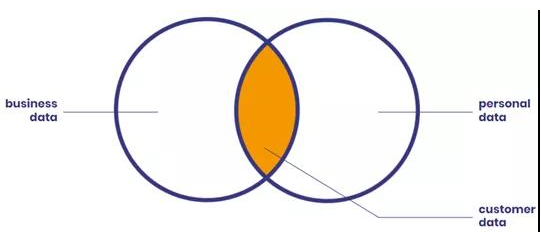
敏感數據類型示例
在歐洲,監管機構將任何與某人(如你的名字)有關的信息定義為“個人數據”。不論形式,任何關聯到此人的信息都符合上述定義。從上世紀起,個人數據收集逐漸民主化,數據匿名化問題開始出現。隨著隱私條例在世界各地開始生效,這件事尤顯重要。
什么是數據匿名化,為何要關注它?
我們從經典定義開始。歐盟的《通用數據保護條例》(GDPR)是這樣定義對匿名信息的:“與識別或可識別自然人無關的信息,或以數據主體不能或不再可識別的方式匿名提供的個人信息。”
其中,“可識別”和“不再”至關重要。這不僅意味著你的名字不應再出現在數據中,也意味著不能從剩余數據中發現你是誰,這與再認同(有時也叫去匿名化)過程有關。
同樣,GDPR(契約中)陳述了一個重要事實:“……因此,數據保護不應適用于匿名信息”。所以,若你設法匿名數據,就不再受GDPR數據保護法的約束。
你可以執行任何處理操作,如分析或數據貨幣化。這帶來了大量機會:
出售數據顯然是首選用途。在世界各地,隱私保護法正在限制個人數據交易,而匿名數據為公司提供了另一種選擇。
它帶來了合作機會。許多公司為了創新或研究而共享數據,匿名數據有助于降低風險。
它還為數據分析和機器學習創造了機會。在保持兼容性的同時運行敏感數據的操作正變得越來越復雜,匿名數據為統計分析和模型訓練提供了安全的原材料,前景一片光明。但實際上真正的匿名數據往往并不如愿。
數據隱私保護機制的范圍
數據的隱私保護有一個范圍。多年來,專家們研發了一系列集方法、機制和工具為一體的技術。這些技術生成了具有不同的匿名級別和不同再識別風險等級的數據。可以說,其范圍涵蓋了個人可識別數據乃至真正的匿名數據。
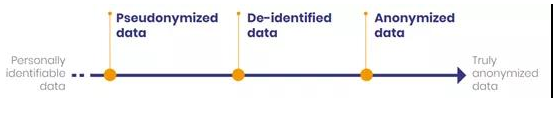
數據隱私的范圍
左端,有包含直接個人識別碼的數據。通過這些元素,可以識別你的姓名、地址或電話號碼。另一端,則是GDPR引用的匿名數據。
如你所見,這些數據有一個中間范疇。它處于可識別數據和匿名數據之間,即假名數據和去識別數據。請注意,其界定仍有爭議。有些報告認為假名化是去識別化的一部分, 而另一些報告則將其排除在外。
生成這種“中間數據”的技術本身并無問題。它們能有效地將數據最小化。根據用例需求,它們將彼此關聯,發揮用處。但切記,它們無法生成真正的匿名數據,它們的機制無法保證阻止再識別,所以將其生成的數據稱為“匿名數據”是一種誤導。
匿名和“匿名”
假名化和去識別化確實能在某些方面保護數據隱私。但根據GDPR的定義,它們無法生成匿名數據。
假名化技術從數據中刪除或替換直接個人標識碼,例如,從數據集中刪除所有名稱和電子郵件,你無法直接從假名數據中識別某人,不過可以間接識別。實際上,剩余數據通常會保留間接識別碼,組合這些信息后,就能創建直接識別碼,如出生日期,郵編,性別等。
就此而言,假名化在GDPR框架中有一個單獨定義:“……以以下方式處理個人數據,即在不使用附加信息的情況下,數據不再可以歸因于特定數據主體”。與匿名數據相反,假名數據符合GDPR的要求。
去識別化技術從數據中去除直接和間接的個人身份識別碼。理論上,去識別化數據和匿名化數據之間的界限很簡單。最新消息表明:有技術可保障永遠無法再識別數據。這是一種“疑罪從無”的情況,去識別化數據在未識別之前是匿名的。每當專家設法重新識別那些最初未識別出的數據時,他們都進一步推動了發展。
數據重新識別不斷重新定義匿名
上述機制類型對隱私保護沒有同等效力,因此如何處理這些數據很重要。公司定期發布或出售他們聲稱“匿名”的數據,但當他們使用的方法不能保證“匿名”時,就會帶來隱患。
眾多事件表明,假名化數據這種隱私保護機制仍有缺陷。數據中的間接識別碼會帶來巨大的再識別風險。隨著可用數據量的增長,相互參照數據集的機會也在增加:
1990年,麻省理工學院的研究生從去識別化醫療數據中重新確認了馬薩諸塞州州長的身份,她將這些信息與公用人口普查數據相互參照來確定患者身份。
2006年,作為研究計劃的一部分,美國在線公司(AOL)共享了去識別化搜索數據,研究人員能夠將搜索查詢與背后的個人聯系起來。
2009年,作為比賽的一部分,網飛(Netflix)發布了一個匿名電影評級數據集,德克薩斯州的研究人員成功重新識別了用戶。
同是2009年,研究人員僅利用公開信息就能預測出一個人的社會保險號。
最近研究表明,去識別化數據實際上可以被重新識別。比利時新魯汶大學和倫敦帝國理工學院的研究人員發現:“使用15個人口統計屬性,在任何數據集中,99.98%的美國人都能被正確地重新識別。”
另一項針對匿名手機數據的研究表明:“四個時空點就足以唯一識別95%的個體用戶”。
技術日益進步,更多的數據正在被創建,研究人員正在努力劃定去識別化數據和匿名數據之間的界限。2017年,研究人員發表論文稱:“網絡瀏覽歷史只能通過公開數據鏈接到社交媒體上的個人資料。”
另一個令人擔憂的問題是個人資料的泄露,越來越多的個人信息遭到泄露。ForgeRock消費者身份泄露報告預測,2020年的信息泄露數量將超過去年,僅美國,2020年第一季度就有超過16億的客戶記錄被泄露。
分開處理的數據集無法重新識別,但與泄露數據結合起來,它會造成更大的威脅。哈佛大學的學生能夠利用泄露的數據重新識別去識別化數據。
總之,那些我們所認為的“匿名數據”往往并不是真正的匿名數據。并非所有的數據凈化方法都會生成真正的匿名數據。事事都各有優點,但沒有一種能提供與匿名同等級別的隱私。隨著數據量的不斷增長,創建真正的匿名數據也越來越難,公司發布潛在可重新識別的個人數據的風險也在增加。
責編AJX
-
數據
+關注
關注
8文章
6898瀏覽量
88833 -
匿名
+關注
關注
0文章
6瀏覽量
6775 -
隱私保護
+關注
關注
0文章
297瀏覽量
16435
發布評論請先 登錄
相關推薦
康謀分享 | 數據隱私和匿名化:PIPL與GDPR下,如何確保數據合規?(二)

數據分析在數字化中的作用
變電所繼電保護的作用與重要性
康謀分享 | 數據隱私和匿名化:PIPL與GDPR下,如何確保數據合規?(一)

動態代理IP的匿名性和透明度,為主要考慮關鍵!

工業智能網關在數據上云方面的作用、優勢以及實施策略
工業物聯網網關在數據融合與邊緣智能方面的作用
平衡創新與倫理:AI時代的隱私保護和算法公平
論RISC-V的MCU中UART接口的重要性
PLC網關的重要性

一眼看懂鴻蒙OS 應用隱私保護






 工商網監
工商網監
評論