 百度智能語音交互的產業化成果豐碩,推進語音技術應用落地
百度智能語音交互的產業化成果豐碩,推進語音技術應用落地
9月15日,AI領域的行業盛會“百度世界2020”大會于線上隆重召開,一大波硬核技術襲來:百度創始人、董事長兼CEO李彥宏與總臺央視主持人康輝“虛擬人”亮相、顛覆搜索形態的“度曉曉”、沒有駕駛員的“全自動駕駛”、各行各業賦能案例……既有硬核技術,又有“接地氣”的落地應用。
在當天的百度大腦分論壇上,百度語音首席架構師賈磊重點講解了百度端到端語音交互技術。他表示,百度語音交互技術持續迭代升級,已發展成為基于深度學習技術的端到端的語音識別和語音合成技術。在語音識別層面,百度推出端到端信號聲學一體化建模的技術,語音合成方面,最新的Meitron和單人千面合成個性化技術亮相。同時交出了百度語音技術最新成績單:日均調用量超過155億次,廣泛應用在移動端、智能家居、和語音IoT等場景,智能語音產業化成果豐碩。
會上,賈磊分別從語音識別和語音合成兩個技術維度詳解了百度語音技術的發展迭代和最新成果。在語音識別方面,百度語音識別技術持續創新,從2012年首推深度學習技術,到2019年在業內首先把注意力模型應用于在線語音識別,推出流式多級的截斷注意力模型 SMLTA;再到如今全面進化為端到端的信號聲學一體化建模技術,在助力百度自身業務發展的同時,更好地賦能多場景、多產業應用。
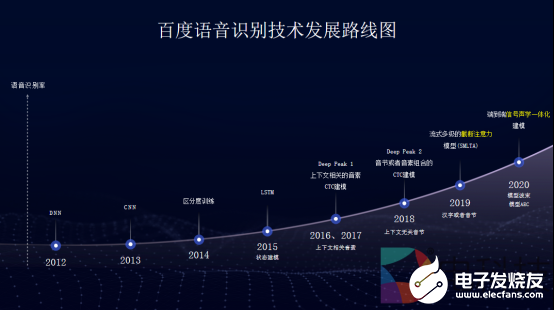
作為百度語音識別技術的最新成果,端到端的信號聲學一體化建模技術很好地解決了傳統數字信號處理和語音識別級聯系統的各種問題,拋棄了各自學科的學科假設,通過端到端的建模,大幅提升了遠場語音識別率。

據賈磊介紹,端到端的信號聲學一體化建模技術由模型波束技術和模型AEC技術組成。前者進化為多分區融合的模型波束建模技術,在國際上由百度首次提出,較單分區技術進一步提升識別性能15%以上;后者是升級為基于雙LOSS實值掩蔽的模型AEC技術,可以解決設備有非線性情況下的回波消除問題,使得設備即使在播放音樂的時候,也能夠進行成功的打斷和高精準的語音識別。

此外,賈磊還在會上介紹了百度今年推出的端側全雙工語音交互技術。據他介紹,百度端側全雙工語音交互技術將復雜的建模過程轉化為3個端到端的深度學習過程,即信號聲學一體化建模、聲學語言一體化建模以及語義置信一體化建模。通過端到端的建模,該技術能夠將整個復雜的端側交互轉變成若干個深度學習計算,使得依靠一顆AI芯片就能完成端側的全雙工語音交互,從而大幅度提升車載手機等語音交互性能,顯著改善用戶體驗。

而在語音合成方面,百度自2013年啟動語音合成研發,歷經參數合成、拼接合成、深度學習語音合成和端到端的語音合成,到如今全新升級為包含個性化、多風格多角色、單人千面的語音合成系統,百度語音合成技術始終處于升級迭代中。
會上,賈磊依次介紹了百度語音合成技術的最新成果——個性化TTS,多風格、多角色,單人千面。個性化TTS是個性化定制的Meitron語音合成系統的最新演進,是基于子帶分解和GAN_loss的端側神經網絡聲碼器,也是業內首個在手機端多人通用的端側的基于神經計算的聲碼器。個性化TTS相較于傳統的基于信號處理和參數的聲碼器,ABX提升可以達到65:35,其已應用于地圖導航,目前每日的導航播報超過1億次。
多風格、多角色的語音合成,則是針對娛樂內容產業(例如小說)中存在的多個角色交替、多種情感需求并存的播報需求而研發的新技術。此前,用單一音色播報缺乏表現力,播報語音和文字本身的角色情感不一致,用戶長時間聽感到單調疲倦。百度通過深度學習技術對小說文本進行分析,判斷出角色、身份、情感,再借助多風格、多角色語音合成技術去合成小說中的聲音,從而實現聲音自然流暢、情感表現力豐富、用戶體驗優美的效果。

針對一個發音人需要用不同風格播報文本的應用場景,百度推出單人千面語音合成技術。該技術能夠把說話人的語音、文本、風格、內容、音色都進行分離,在進行語音合成的時候自由組合,從而能夠讓一個發音人同時去播報新聞、小說、脫口秀、讀書、詩歌等不同風格。
“百度智能語音交互的產業化成果豐碩,目前百度智能語音的日均調用量超過155億次,廣泛應用于移動端、智能家居、智能車載、智能服務以及語音IoT,極大地提高了中國社會的智能化程度。”賈磊表示。語音技術作為百度大腦的重要AI能力之一,不但應用于百度搜索、百度輸入法、百度地圖、小度音箱等百度系列產品,更通過百度大腦AI開放平臺廣泛賦能眾多行業和場景的合作伙伴。未來,百度還將持續創新升級語音交互技術,推進語音技術應用落地,助力更多產業智能化轉型升級。
責任編輯:gt
-
百度
+關注
關注
9文章
2257瀏覽量
90258 -
智能家居
+關注
關注
1926文章
9516瀏覽量
184321 -
IOT
+關注
關注
186文章
4178瀏覽量
196238
發布評論請先 登錄
相關推薦
百度世界2024公開課完美結束
百度小度將發布AI智能眼鏡

百度智能云攜手烏鎮共建AI數據產業基地
東莞與百度簽署戰略合作協議,推動人工智能的全場景應用落地
東莞市與百度合作推動人工智能的全場景應用落地

首屆百度智能云全球生態大會,4月9日成都見!
【有獎】 百度智能云度目推出首款多模態 AI 模組,應用場景有獎征集!
華為智能座艙與百度地圖簽署生態合作協議 共創導航出行新體驗
離線語音識別技術:掌控未來的語音交互






 工商網監
工商網監
評論