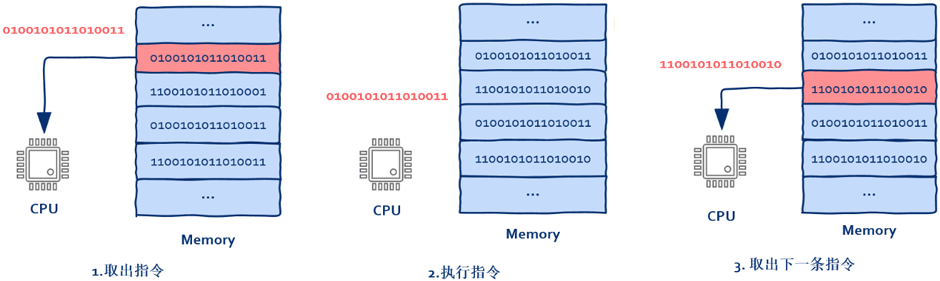
") 如何理解服務(wù)器的高性能
如何理解服務(wù)器的高性能
對(duì)于大部分應(yīng)用來(lái)說,想要高性能,主要是要做到盡可能的減少網(wǎng)絡(luò)請(qǐng)求(含DB、Redis、MongoDB、MQ)等。幾乎所有的應(yīng)用,性能瓶頸永遠(yuǎn)是在帶寬那里;關(guān)于各個(gè)組件到CPU的時(shí)間周期,文字描述如下:L1>L2>memory>disk>internet。
大家都知道IP是逐跳協(xié)議,也就是說我只能從一個(gè)路由器,到下一個(gè)路由器,再到下一個(gè)路由器,如果你的電腦到服務(wù)器,中途要經(jīng)過很多個(gè)路由器,那時(shí)間周期就會(huì)長(zhǎng)很多很多很多。為什么要做CDN、P2P等也是這個(gè)考慮,縮短網(wǎng)絡(luò)的路徑(降低帶寬承載也是一方面)。
就像是我有一個(gè)游戲服務(wù)器,在線人數(shù)約4000,里面是一個(gè)狀態(tài)機(jī)在跑,需要不斷的去檢測(cè)各種狀態(tài)、經(jīng)驗(yàn)、星座、任務(wù)開放、技能開放等。一個(gè)玩家大約10個(gè)狀態(tài)的判定,4000個(gè)玩家必須在200ms之內(nèi)檢測(cè)完畢,不然延遲會(huì)很嚴(yán)重,那1s就是大約執(zhí)行5次,如果每一次數(shù)據(jù)都去Redis去取,大約是5*10*4000 = 200k次,別說Redis,再牛的服務(wù)器都頂不住!
遇到這種情況,建議把數(shù)據(jù)放在內(nèi)存里面,直接從內(nèi)存取,然后foreach。大部分的應(yīng)用優(yōu)化到這里,基本上應(yīng)付所謂的日pv百萬(wàn),就不是什么問題了。
到了這一步,那么問題來(lái)了,對(duì)于內(nèi)部應(yīng)用,比如分布式文件存儲(chǔ)、數(shù)據(jù)分析、任務(wù)調(diào)度,咋整?
對(duì)于大數(shù)據(jù),其實(shí)一直是一個(gè)偽命題,數(shù)據(jù)量太大屬于硬傷。所有的做大數(shù)據(jù)處理的,都是把數(shù)據(jù)分成小數(shù)據(jù),然后分塊來(lái)處理,最后再合并。其實(shí)從MySQL、Oracle、msSQL等一系列人RMDB的分區(qū),分庫(kù)上的處理就可以看出來(lái)。想要提高性能,必須要做到,每個(gè)模塊處理的數(shù)據(jù)量,都是細(xì)分到了一定粒度的。這個(gè)時(shí)候index、group、hash等的重要性,在這里就體現(xiàn)出來(lái)了。
若我有一個(gè)業(yè)務(wù)系統(tǒng),每天的日志大約是10個(gè)G,一個(gè)月就大約是300G,一季度大約1T,我需要看每小時(shí)/每天/每周/每月/每季度的各種報(bào)表,每次都去數(shù)T里面去找,肯定是不可能的。
一般按業(yè)務(wù)分析每分鐘的數(shù)據(jù),10G/24/60大約7M,然后生成一個(gè)分析后的結(jié)果文件,大約幾K,1小時(shí)就是60個(gè)文件,需要查看每小時(shí)的數(shù)據(jù),則將60個(gè)文件的結(jié)果合并。
那我需要查看某一個(gè)用戶,最近10天來(lái)的所有操作/訂單,那原分組方式,已經(jīng)無(wú)法滿足,這個(gè)時(shí)候怎么辦呢?
在插入用戶數(shù)據(jù)的時(shí)候,可以按照一定規(guī)則,比如用戶編號(hào)的后兩位取摸,去存儲(chǔ)在某一個(gè)文件里面,10G的數(shù)據(jù),則可以相對(duì)平均的分配到100個(gè)文件里面去,需要查看某用戶時(shí),則可以針對(duì)用戶編號(hào)取摸,直接定位到那個(gè)文件,然后再去里面查詢數(shù)據(jù)。這個(gè)是比較簡(jiǎn)單的gourp+index。這一塊想明白以后,你就可以在這個(gè)基礎(chǔ)上面,寫個(gè)定制化的簡(jiǎn)單的fs了
經(jīng)常聽到有人說,多線程的程序還不如單線程的程序性能高。那如何編寫一個(gè)能合理利用CPU資源的多線程程序?
大家都知道,線程切換是需要額外的開銷,所以在編寫多線程程序的時(shí)候,就需要盡可能的避免共享式資源,這樣就可以在保證數(shù)據(jù)一致性的同時(shí),而又避開線程等待的時(shí)間。
舉個(gè)簡(jiǎn)單的例子:
我有個(gè)大的字典(Dictionary/Map)存放用戶的會(huì)話數(shù)據(jù),每個(gè)線程,去這個(gè)字典里面去讀/寫數(shù)據(jù)的時(shí)候,都需要去上鎖,才能保證數(shù)據(jù)的一致性,如果兩個(gè)(更多)線程同時(shí)去讀/寫數(shù)據(jù),其他的線程就需要去等待當(dāng)前線程釋放資源,線程越多,則等待的幾率越大,性能則越差,多線程處理變成了單線程處理,且等待完了以后,能否再切換回來(lái)這個(gè)線程繼續(xù)執(zhí)行,又是另外一個(gè)開銷,這一部分屬于系統(tǒng)拖托管,屬于不可控的。
那么問題來(lái)了:怎么解決呢?
根據(jù)硬件和實(shí)際測(cè)試數(shù)據(jù),合理分配線程資源,比如,我初始化了8個(gè)線程,每個(gè)用戶的請(qǐng)求,對(duì)于線程總數(shù)取模,保證每個(gè)用戶的請(qǐng)求,同一個(gè)線程處理,則可以在每個(gè)線程內(nèi)部,存放這些用戶數(shù)據(jù),每個(gè)線程在自己內(nèi)部進(jìn)行存取,避開了lock,也避開了線程等待/切換帶來(lái)的資源開銷。不取模,隨機(jī)分配線程,然后用一個(gè)hash表來(lái)存放,也可。讓每個(gè)線程,專注于做自己的事情,任務(wù)調(diào)度作業(yè),也是基于這個(gè)處理。把線程處理機(jī)制,放大到虛擬機(jī)/物理機(jī)之間的消息分發(fā),也是如此。
總體來(lái)說,避開網(wǎng)絡(luò)開銷,避開海量數(shù)據(jù),避開資源爭(zhēng)奪 是所有高性能的幾個(gè)基本要素。
-
cpu
+關(guān)注
關(guān)注
68文章
10824瀏覽量
211138 -
服務(wù)器
+關(guān)注
關(guān)注
12文章
9017瀏覽量
85182 -
路由器
+關(guān)注
關(guān)注
22文章
3706瀏覽量
113536 -
數(shù)據(jù)分析
+關(guān)注
關(guān)注
2文章
1427瀏覽量
34012
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦

服務(wù)器技術(shù)基礎(chǔ)
華為服務(wù)器為什么可以保持高性能和高可靠性
什么是服務(wù)器
高性能高并發(fā)服務(wù)器架構(gòu)分享
詳解Nginx高性能的HTTP和反向代理服務(wù)器
如何監(jiān)控服務(wù)器性能?
如何理解高性能服務(wù)器的高性能、高并發(fā)?
高性能整流器顯著提高服務(wù)器供電效率

gpu服務(wù)器是干什么的 gpu服務(wù)器與cpu服務(wù)器的區(qū)別
人工智能服務(wù)器高性能計(jì)算需求
國(guó)產(chǎn)高性能溫補(bǔ)晶振用于服務(wù)器光模塊,替換SiTime





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論