 基于Linux內核源碼的RCU實現方案
基于Linux內核源碼的RCU實現方案
RCU(Read-Copy Update)是數據同步的一種方式,在當前的Linux內核中發揮著重要的作用。RCU主要針對的數據對象是鏈表,目的是提高遍歷讀取數據的效率,為了達到目的使用RCU機制讀取數據的時候不對鏈表進行耗時的加鎖操作。這樣在同一時間可以有多個線程同時讀取該鏈表,并且允許一個線程對鏈表進行修改(修改的時候,需要加鎖)。RCU適用于需要頻繁的讀取數據,而相應修改數據并不多的情景,例如在文件系統中,經常需要查找定位目錄,而對目錄的修改相對來說并不多,這就是RCU發揮作用的最佳場景。
Linux內核源碼當中,關于RCU的文檔比較齊全,你可以在 /Documentation/RCU/ 目錄下找到這些文件。Paul E. McKenney 是內核中RCU源碼的主要實現者,他也寫了很多RCU方面的文章。他把這些文章和一些關于RCU的論文的鏈接整理到了一起。http://www2.rdrop.com/users/paulmck/RCU/
在RCU的實現過程中,我們主要解決以下問題:
1,在讀取過程中,另外一個線程刪除了一個節點。刪除線程可以把這個節點從鏈表中移除,但它不能直接銷毀這個節點,必須等到所有的讀取線程讀取完成以后,才進行銷毀操作。RCU中把這個過程稱為寬限期(Grace period)。
2,在讀取過程中,另外一個線程插入了一個新節點,而讀線程讀到了這個節點,那么需要保證讀到的這個節點是完整的。這里涉及到了發布-訂閱機制(Publish-Subscribe Mechanism)。
3, 保證讀取鏈表的完整性。新增或者刪除一個節點,不至于導致遍歷一個鏈表從中間斷開。但是RCU并不保證一定能讀到新增的節點或者不讀到要被刪除的節點。
寬限期
通過例子,方便理解這個內容。以下例子修改于Paul的文章。
[cpp]view plaincopy
structfoo{
inta;
charb;
longc;
};
DEFINE_SPINLOCK(foo_mutex);
structfoo*gbl_foo;
voidfoo_read(void)
{
foo*fp=gbl_foo;
if(fp!=NULL)
dosomething(fp->a,fp->b,fp->c);
}
voidfoo_update(foo*new_fp)
{
spin_lock(&foo_mutex);
foo*old_fp=gbl_foo;
gbl_foo=new_fp;
spin_unlock(&foo_mutex);
kfee(old_fp);
}
如上的程序,是針對于全局變量gbl_foo的操作。假設以下場景。有兩個線程同時運行 foo_ read和foo_update的時候,當foo_ read執行完賦值操作后,線程發生切換;此時另一個線程開始執行foo_update并執行完成。當foo_ read運行的進程切換回來后,運行dosomething 的時候,fp已經被刪除,這將對系統造成危害。為了防止此類事件的發生,RCU里增加了一個新的概念叫寬限期(Grace period)。如下圖所示:
圖中每行代表一個線程,最下面的一行是刪除線程,當它執行完刪除操作后,線程進入了寬限期。寬限期的意義是,在一個刪除動作發生后,它必須等待所有在寬限期開始前已經開始的讀線程結束,才可以進行銷毀操作。這樣做的原因是這些線程有可能讀到了要刪除的元素。圖中的寬限期必須等待1和2結束;而讀線程5在寬限期開始前已經結束,不需要考慮;而3,4,6也不需要考慮,因為在寬限期結束后開始后的線程不可能讀到已刪除的元素。為此RCU機制提供了相應的API來實現這個功能。
[cpp]view plaincopy
voidfoo_read(void)
{
rcu_read_lock();
foo*fp=gbl_foo;
if(fp!=NULL)
dosomething(fp->a,fp->b,fp->c);
rcu_read_unlock();
}
voidfoo_update(foo*new_fp)
{
spin_lock(&foo_mutex);
foo*old_fp=gbl_foo;
gbl_foo=new_fp;
spin_unlock(&foo_mutex);
synchronize_rcu();
kfee(old_fp);
}
其中foo_read中增加了rcu_read_lock和rcu_read_unlock,這兩個函數用來標記一個RCU讀過程的開始和結束。其實作用就是幫助檢測寬限期是否結束。foo_update增加了一個函數synchronize_rcu(),調用該函數意味著一個寬限期的開始,而直到寬限期結束,該函數才會返回。我們再對比著圖看一看,線程1和2,在synchronize_rcu之前可能得到了舊的gbl_foo,也就是foo_update中的old_fp,如果不等它們運行結束,就調用kfee(old_fp),極有可能造成系統崩潰。而3,4,6在synchronize_rcu之后運行,此時它們已經不可能得到old_fp,此次的kfee將不對它們產生影響。
寬限期是RCU實現中最復雜的部分,原因是在提高讀數據性能的同時,刪除數據的性能也不能太差。
訂閱——發布機制
當前使用的編譯器大多會對代碼做一定程度的優化,CPU也會對執行指令做一些優化調整,目的是提高代碼的執行效率,但這樣的優化,有時候會帶來不期望的結果。如例:
[cpp]view plaincopy
voidfoo_update(foo*new_fp)
{
spin_lock(&foo_mutex);
foo*old_fp=gbl_foo;
new_fp->a=1;
new_fp->b=‘b’;
new_fp->c=100;
gbl_foo=new_fp;
spin_unlock(&foo_mutex);
synchronize_rcu();
kfee(old_fp);
}
這段代碼中,我們期望的是6,7,8行的代碼在第10行代碼之前執行。但優化后的代碼并不對執行順序做出保證。在這種情形下,一個讀線程很可能讀到 new_fp,但new_fp的成員賦值還沒執行完成。當讀線程執行dosomething(fp->a, fp->b , fp->c ) 的 時候,就有不確定的參數傳入到dosomething,極有可能造成不期望的結果,甚至程序崩潰。可以通過優化屏障來解決該問題,RCU機制對優化屏障做了包裝,提供了專用的API來解決該問題。這時候,第十行不再是直接的指針賦值,而應該改為 :
rcu_assign_pointer(gbl_foo,new_fp);
rcu_assign_pointer的實現比較簡單,如下:
[cpp]view plaincopy
#definercu_assign_pointer(p,v)
__rcu_assign_pointer((p),(v),__rcu)
#define__rcu_assign_pointer(p,v,space)
do{
smp_wmb();
(p)=(typeof(*v)__forcespace*)(v);
}while(0)
我們可以看到它的實現只是在賦值之前加了優化屏障 smp_wmb來確保代碼的執行順序。另外就是宏中用到的__rcu,只是作為編譯過程的檢測條件來使用的。
在DEC Alpha CPU機器上還有一種更強悍的優化,如下所示:
[cpp]view plaincopy
voidfoo_read(void)
{
rcu_read_lock();
foo*fp=gbl_foo;
if(fp!=NULL)
dosomething(fp->a,fp->b,fp->c);
rcu_read_unlock();
}
第六行的fp->a,fp->b,fp->c會在第3行還沒執行的時候就預先判斷運行,當他和foo_update同時運行的時候,可能導致傳入dosomething的一部分屬于舊的gbl_foo,而另外的屬于新的。這樣導致運行結果的錯誤。為了避免該類問題,RCU還是提供了宏來解決該問題:
[cpp]view plaincopy
#definercu_dereference(p)rcu_dereference_check(p,0)
#definercu_dereference_check(p,c)
__rcu_dereference_check((p),rcu_read_lock_held()||(c),__rcu)
#define__rcu_dereference_check(p,c,space)
({
typeof(*p)*_________p1=(typeof(*p)*__force)ACCESS_ONCE(p);
rcu_lockdep_assert(c,"suspiciousrcu_dereference_check()"
"usage");
rcu_dereference_sparse(p,space);
smp_read_barrier_depends();
((typeof(*p)__force__kernel*)(_________p1));
})
staticinlineintrcu_read_lock_held(void)
{
if(!debug_lockdep_rcu_enabled())
return1;
if(rcu_is_cpu_idle())
return0;
if(!rcu_lockdep_current_cpu_online())
return0;
returnlock_is_held(&rcu_lock_map);
}
這段代碼中加入了調試信息,去除調試信息,可以是以下的形式(其實這也是舊版本中的代碼):
[cpp]view plaincopy
#definercu_dereference(p)({
typeof(p)_________p1=p;
smp_read_barrier_depends();
(_________p1);
})
在賦值后加入優化屏障smp_read_barrier_depends()。
我們之前的第四行代碼改為foo *fp = rcu_dereference(gbl_foo);,就可以防止上述問題。
數據讀取的完整性
還是通過例子來說明這個問題:
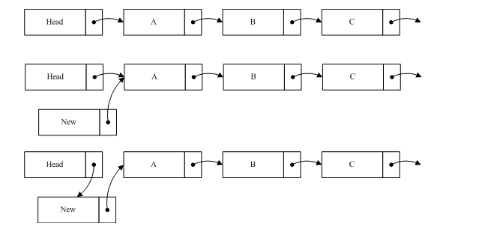
如圖我們在原list中加入一個節點new到A之前,所要做的第一步是將new的指針指向A節點,第二步才是將Head的指針指向new。這樣做的目的是當插入操作完成第一步的時候,對于鏈表的讀取并不產生影響,而執行完第二步的時候,讀線程如果讀到new節點,也可以繼續遍歷鏈表。如果把這個過程反過來,第一步head指向new,而這時一個線程讀到new,由于new的指針指向的是Null,這樣將導致讀線程無法讀取到A,B等后續節點。從以上過程中,可以看出RCU并不保證讀線程讀取到new節點。如果該節點對程序產生影響,那么就需要外部調用做相應的調整。如在文件系統中,通過RCU定位后,如果查找不到相應節點,就會進行其它形式的查找,相關內容等分析到文件系統的時候再進行敘述。
我們再看一下刪除一個節點的例子:
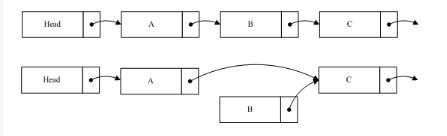
如圖我們希望刪除B,這時候要做的就是將A的指針指向C,保持B的指針,然后刪除程序將進入寬限期檢測。由于B的內容并沒有變更,讀到B的線程仍然可以繼續讀取B的后續節點。B不能立即銷毀,它必須等待寬限期結束后,才能進行相應銷毀操作。由于A的節點已經指向了C,當寬限期開始之后所有的后續讀操作通過A找到的是C,而B已經隱藏了,后續的讀線程都不會讀到它。這樣就確保寬限期過后,刪除B并不對系統造成影響。
小結
RCU的原理并不復雜,應用也很簡單。但代碼的實現確并不是那么容易,難點都集中在了寬限期的檢測上,后續分析源代碼的時候,我們可以看到一些極富技巧的實現方式。
-
Linux
+關注
關注
87文章
11232瀏覽量
208952 -
數據同步
+關注
關注
0文章
17瀏覽量
8153 -
rcu
+關注
關注
0文章
21瀏覽量
5440
發布評論請先 登錄
相關推薦
linux內核中通用HID觸摸驅動

linux驅動程序如何加載進內核
Linux內核測試技術
Linux內核中的頁面分配機制

歡創播報 華為宣布鴻蒙內核已超越Linux內核
AOSP源碼定制-內核驅動編寫
使用 PREEMPT_RT 在 Ubuntu 中構建實時 Linux 內核

Ubuntu 24.04 LTS選用Linux 6.8為默認內核
分級RCU的基礎知識
深入理解RCU:玩具式實現
嵌入式學習——ElfBoard ELF1板卡 獲取內核源碼的方法
I.MX6ULL-ElfBoard ELF1板卡 獲取內核源碼的方法。

Linux內核自解壓過程分析





 工商網監
工商網監
評論