") NLP 2019 Highlights 給NLP從業(yè)者的一個參考
NLP 2019 Highlights 給NLP從業(yè)者的一個參考
自然語言處理專家elvis在medium博客上發(fā)表了關(guān)于NLP在2019年的亮點總結(jié)。對于自然語言處理(NLP)領(lǐng)域而言,2019年是令人印象深刻的一年。在這篇博客文章中,我想重點介紹一些我在2019年遇到的與機器學(xué)習和NLP相關(guān)的最重要的故事。我將主要關(guān)注NLP,但我還將重點介紹一些與AI相關(guān)的有趣故事。標題沒有特別的順序。故事可能包括論文,工程工作,年度報告,教育資源的發(fā)布等。
論文刊物
ML / NLP創(chuàng)造力與社會
ML / NLP工具和數(shù)據(jù)集
文章和博客文章
人工智能倫理
ML / NLP教育
Google AI引入了ALBERT,它是BERT 的精簡版本,用于自監(jiān)督學(xué)習上下文語言表示。主要改進是減少冗余并更有效地分配模型的容量。該方法提高了12個NLP任務(wù)的最新性能。
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut:ALBERT: ALiteBERTforSelf-supervised LearningofLanguageRepresentations.ICLR 2020.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL-HLT (1) 2019: 4171-4186
arxiv.org/abs/1810.0480

機器在比賽中的表現(xiàn)(類似sat的閱讀理解)。隨機猜測的基線得分為25.0。最高分是95.0分。
今年早些時候,NVIDIA的研究人員發(fā)表了一篇頗受歡迎的論文(Coined StyleGAN)(arxiv.org/pdf/1812.0494),提出了一種從樣式轉(zhuǎn)換中采用的GAN替代生成器架構(gòu)。這是一項后續(xù)工作(arxiv.org/pdf/1912.0495),著重于改進,例如重新設(shè)計生成器歸一化過程。
Tero Karras, Samuli Laine, Timo Aila:A Style-Based Generator Architecture for Generative Adversarial Networks. CVPR 2019: 4401-4410
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila:Analyzing and Improving the Image Quality of StyleGAN. CoRR abs/1912.04958 (2019)
上排顯示目標圖像,下排顯示合成圖像
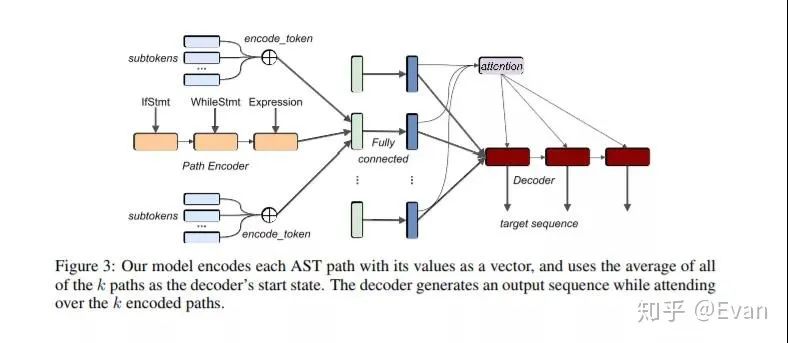
我今年最喜歡的論文之一是code2seq(code2seq.org/),它是一種從結(jié)構(gòu)化代碼表示中生成自然語言序列的方法。這樣的研究可以讓位于諸如自動代碼摘要和文檔之類的應(yīng)用程序。
Uri Alon, Shaked Brody, Omer Levy, Eran Yahav:code2seq: Generating Sequences from Structured Representations of Code. ICLR (Poster) 2019
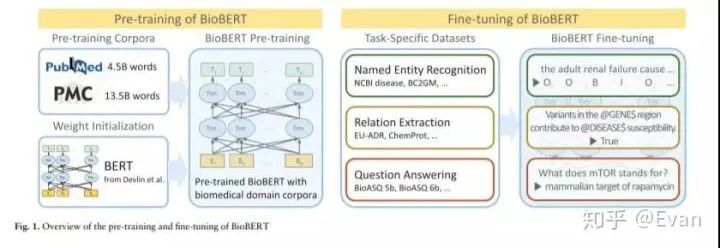
有沒有想過是否有可能為生物醫(yī)學(xué)文本挖掘訓(xùn)練生物醫(yī)學(xué)語言模型?答案是BioBERT(arxiv.org/abs/1901.0874),這是一種從生物醫(yī)學(xué)文獻中提取重要信息的情境化方法。
Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, Jaewoo Kang:BioBERT: a pre-trained biomedical language representation model for biomedical text mining. CoRR abs/1901.08746 (2019)
BERT發(fā)布后,F(xiàn)acebook研究人員發(fā)布了RoBERTa,該版本引入了新的優(yōu)化方法來改進BERT,并在各種NLP基準上產(chǎn)生了最新的結(jié)果。(ai.facebook.com/blog/-t)
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov:RoBERTa: A Robustly Optimized BERT Pretraining Approach. CoRR abs/1907.11692 (2019)
來自Facebook AI的研究人員最近還發(fā)布了一種基于全注意力關(guān)注層的方法,用于提高Transformer語言模型的效率。從這個研究小組更多的工作包括方法來教如何使用自然語言規(guī)劃的AI系統(tǒng)。
Sainbayar Sukhbaatar, Edouard Grave, Piotr Bojanowski, Armand Joulin:Adaptive Attention Span in Transformers. ACL (1) 2019: 331-335

可解釋性仍然是機器學(xué)習和NLP中的重要主題。集大成者!可解釋人工智能(XAI)研究最新進展萬字綜述論文: 概念體系機遇和挑戰(zhàn)—構(gòu)建負責任的人工智能
Alejandro Barredo Arrieta, Natalia Díaz Rodríguez, Javier Del Ser, Adrien Bennetot, Siham Tabik, Alberto Barbado, Salvador García, Sergio Gil-Lopez, Daniel Molina, Richard Benjamins, Raja Chatila, Francisco Herrera:Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI.CoRR abs/1910.10045 (2019)
Sebastian Ruder發(fā)表了有關(guān)自然語言處理的神經(jīng)遷移學(xué)習的論文
(ruder.io/thesis/)。
Ruder2019Neural,Neural Transfer Learning for Natural Language Processing, Ruder, Sebastian,2019,National University of Ireland, Galway
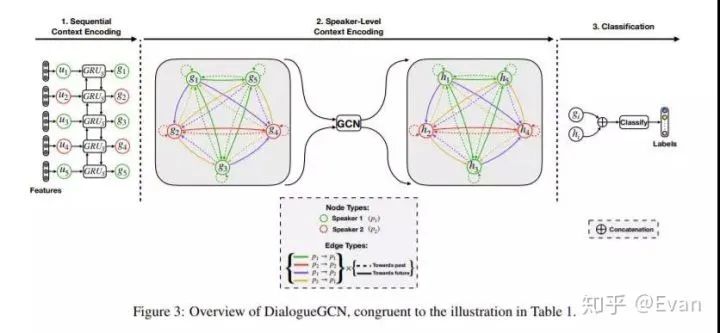
一些研究人員開發(fā)了一種在對話中進行情感識別的方法(arxiv.org/abs/1910.0498),可以為情感對話的產(chǎn)生鋪平道路。另一個相關(guān)的工作涉及一種稱為DialogueGCN(aclweb.org/anthology/D1)的GNN方法,以檢測對話中的情緒。該研究論文還提供了代碼實現(xiàn)。
Devamanyu Hazarika, Soujanya Poria, Roger Zimmermann, Rada Mihalcea:Emotion Recognition in Conversations with Transfer Learning from Generative Conversation Modeling.CoRR abs/1910.04980 (2019)
Deepanway Ghosal, Navonil Majumder, Soujanya Poria, Niyati Chhaya, Alexander F. Gelbukh:DialogueGCN: A Graph Convolutional Neural Network for Emotion Recognition in Conversation. EMNLP/IJCNLP (1) 2019: 154-164
Google AI Quantum團隊在《自然》雜志上發(fā)表了一篇論文(nature.com/articles/s41),他們聲稱自己開發(fā)了一種量子計算機,其速度比世界上最大的超級計算機還要快。在此處詳細了解他們的實驗。
Arute, F., Arya, K., Babbush, R. et al.Quantum supremacy using a programmable superconducting processor.Nature 574, 505–510 (2019) doi:10.1038/s41586-019-1666-5
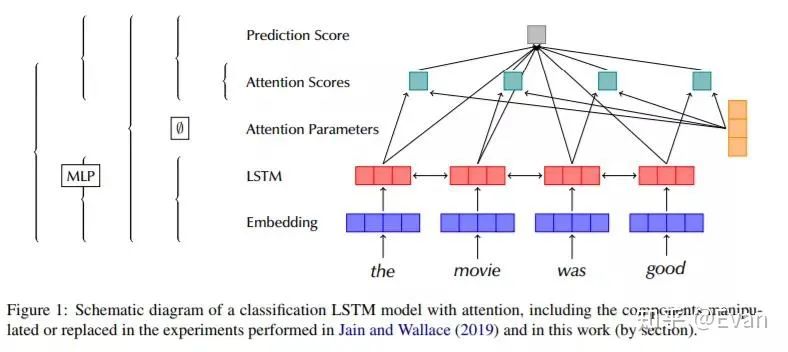
如前所述,神經(jīng)網(wǎng)絡(luò)體系結(jié)構(gòu)需要大量改進的領(lǐng)域之一是可解釋性。本論文(arxiv.org/abs/1908.0462)探討了在語言模型的上下文explainability一個可靠的方法關(guān)注的局限性。
Sarah Wiegreffe, Yuval Pinter:Attention is not not Explanation. EMNLP/IJCNLP (1) 2019: 11-20
神經(jīng)邏輯機器是一種神經(jīng)符號網(wǎng)絡(luò)體系結(jié)構(gòu)(arxiv.org/abs/1904.1169),能夠很好地在歸納學(xué)習和邏輯推理方面做得很好。該模型在諸如排序數(shù)組和查找最短路徑之類的任務(wù)上表現(xiàn)出色。
Honghua Dong, Jiayuan Mao, Tian Lin, Chong Wang, Lihong Li, Denny Zhou:Neural Logic Machines. ICLR (Poster) 2019

神經(jīng)邏輯機器架構(gòu)
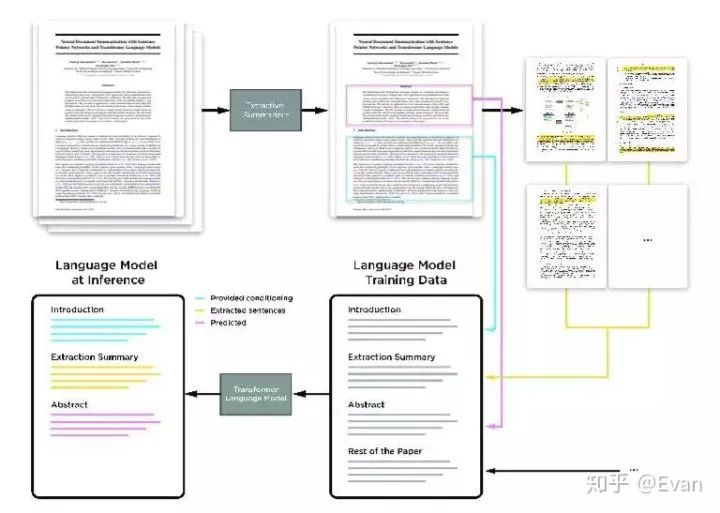
這是一篇將Transformer語言模型應(yīng)用于提取和抽象神經(jīng)類文檔摘要的論文(arxiv.org/abs/1909.0318)。
Sandeep Subramanian, Raymond Li, Jonathan Pilault, Christopher J. Pal:OnExtractiveandAbstractiveNeuralDocumentSummarizationwithTransformerLanguageModels.CoRRabs/1909.03186 (2019)
研究人員開發(fā)了一種方法,側(cè)重于使用比較來建立和訓(xùn)練ML模型。這種技術(shù)不需要大量的特征標簽對,而是將圖像與以前看到的圖像進行比較,以確定圖像是否屬于某個特定的標簽。
blog.ml.cmu.edu/2019/03
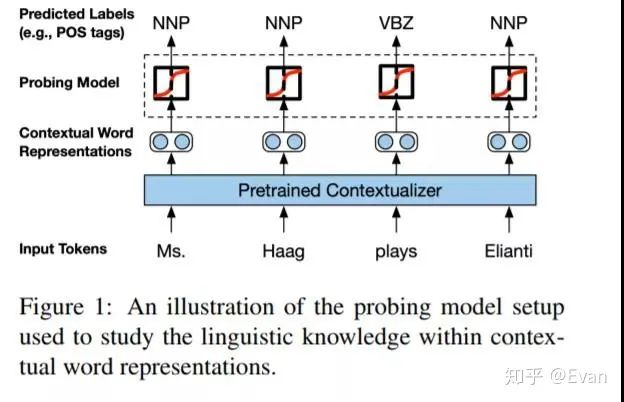
Nelson Liu等人發(fā)表了一篇論文,討論了預(yù)先訓(xùn)練的語境設(shè)定者(如BERT和ELMo)獲取的語言知識的類型。
arxiv.org/abs/1903.0885
Nelson F. Liu, Matt Gardner, Yonatan Belinkov, Matthew E. Peters, Noah A. Smith:Linguistic Knowledge and Transferability of Contextual Representations. NAACL-HLT (1) 2019: 1073-1094
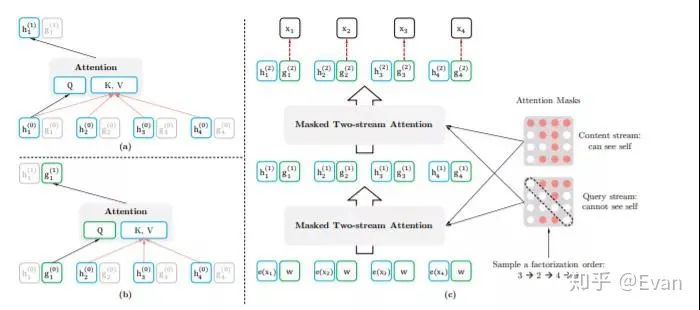
XLNet是NLP的一種前訓(xùn)練方法,它在20個任務(wù)上都比BERT有改進。我寫了一個總結(jié),這偉大的工作在這里。
arxiv.org/abs/1906.0823
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime G. Carbonell, Ruslan Salakhutdinov, Quoc V. Le:XLNet: Generalized Autoregressive Pretraining for Language Understanding. CoRR abs/1906.08237 (2019)
這項來自DeepMind的工作報告了一項廣泛的實證調(diào)查的結(jié)果,該調(diào)查旨在評估應(yīng)用于各種任務(wù)的語言理解模型。這種廣泛的分析對于更好地理解語言模型所捕獲的內(nèi)容以提高它們的效率是很重要的。
arxiv.org/abs/1901.1137
Dani Yogatama, Cyprien de Masson d'Autume, Jerome Connor, Tomás Kocisky, Mike Chrzanowski, Lingpeng Kong, Angeliki Lazaridou, Wang Ling, Lei Yu, Chris Dyer, Phil Blunsom:Learning and Evaluating General Linguistic Intelligence. CoRR abs/1901.11373 (2019)
VisualBERT是一個簡單而健壯的框架,用于建模視覺和語言任務(wù),包括VQA和Flickr30K等。這種方法利用了一組Transformer層,并結(jié)合了self-attention來對齊文本中的元素和圖像中的區(qū)域。
arxiv.org/abs/1908.0355
Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang:VisualBERT: A Simple and Performant Baseline for Vision and Language. CoRR abs/1908.03557 (2019)
這項工作提供了一個詳細的分析比較NLP轉(zhuǎn)移學(xué)習方法和指導(dǎo)NLP的從業(yè)者。
arxiv.org/abs/1903.0598
Matthew E. Peters, Sebastian Ruder, Noah A. Smith:To Tune or Not to Tune? Adapting Pretrained Representations to Diverse Tasks.RepL4NLP@ACL 2019: 7-14
Alex Wang和Kyunghyun提出了BERT的實現(xiàn),能夠產(chǎn)生高質(zhì)量、流暢的表示。
arxiv.org/abs/1902.0409
Facebook的研究人員發(fā)表了XLM的代碼(PyTorch實現(xiàn)),這是一個跨語言模型的預(yù)培訓(xùn)模型。
github.com/facebookrese
本文全面分析了強化學(xué)習算法在神經(jīng)機器翻譯中的應(yīng)用。
cl.uni-heidelberg.de/st
這篇發(fā)表在JAIR上的調(diào)查論文對跨語言單詞嵌入模型的培訓(xùn)、評估和使用進行了全面的概述。
jair.org/index.php/jair
Gradient發(fā)表了一篇優(yōu)秀的文章,詳細闡述了強化學(xué)習目前的局限性,并提供了一條潛在的分級強化學(xué)習的前進道路。一些人發(fā)布了一套優(yōu)秀的教程來開始強化學(xué)習。
thegradient.pub/the-pro
這篇簡要介紹了上下文詞表示。
arxiv.org/abs/1902.0600
責任編輯:xj
原文標題:【前沿】28篇標志性論文見證「自然語言處理NLP」2019->2020年度亮點進展
文章出處:【微信公眾號:深度學(xué)習自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
自然語言處理
+關(guān)注
關(guān)注
1文章
614瀏覽量
13513 -
nlp
+關(guān)注
關(guān)注
1文章
487瀏覽量
22015
原文標題:【前沿】28篇標志性論文見證「自然語言處理NLP」2019->2020年度亮點進展
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
大數(shù)據(jù)從業(yè)者必知必會的Hive SQL調(diào)優(yōu)技巧
nlp邏輯層次模型的特點
nlp神經(jīng)語言和NLP自然語言的區(qū)別和聯(lián)系
nlp自然語言處理基本概念及關(guān)鍵技術(shù)
nlp自然語言處理框架有哪些
nlp自然語言處理的主要任務(wù)及技術(shù)方法
nlp自然語言處理模型怎么做
nlp自然語言處理模型有哪些
nlp自然語言處理的應(yīng)用有哪些
深度學(xué)習與nlp的區(qū)別在哪
NLP技術(shù)在機器人中的應(yīng)用
NLP技術(shù)在人工智能領(lǐng)域的重要性
NLP模型中RNN與CNN的選擇
什么是自然語言處理 (NLP)
NLP領(lǐng)域的語言偏置問題分析






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論