") 基于VxWorks操作系統(tǒng)實(shí)現(xiàn)多CPU并行計(jì)算機(jī)系統(tǒng)的軟硬件設(shè)計(jì)
基于VxWorks操作系統(tǒng)實(shí)現(xiàn)多CPU并行計(jì)算機(jī)系統(tǒng)的軟硬件設(shè)計(jì)
1 引言
在信息技術(shù)高速發(fā)展的今天,對于計(jì)算機(jī)的使用可以說無處不在。特別是在軍工領(lǐng)域,計(jì)算機(jī)充當(dāng)了軍事控制和數(shù)據(jù)處理的核心,人們對計(jì)算機(jī)的性能要求也越來越高。一些特殊領(lǐng)域,如雷達(dá)、導(dǎo)航等對計(jì)算機(jī)的處理速度、實(shí)時(shí)性的要求不斷提高。人們采用了多種方法來解決這些不斷增長的技術(shù)指標(biāo)要求,本文介紹的多處理器并行計(jì)算機(jī)的軟硬件設(shè)計(jì),是采用多個CPU 進(jìn)行并行數(shù)據(jù)處理的方法來提高單板的運(yùn)算性能。
2 多處理器并行計(jì)算機(jī)系統(tǒng)的硬件設(shè)計(jì)
多處理器并行計(jì)算機(jī)系統(tǒng)是屬于并行結(jié)構(gòu)的系統(tǒng)模型,每一個處理器都需要具有自己局部存儲器,以存儲自己的應(yīng)用程序并能夠獨(dú)立高速并行計(jì)算;同時(shí),該系統(tǒng)需要具有高速通信的互連網(wǎng)絡(luò),可以把并行數(shù)據(jù)塊高速分布在各個處理器的局部存儲器中,以提高并行系統(tǒng)的效率。該計(jì)算機(jī)結(jié)構(gòu)設(shè)計(jì)可以采用共享存儲器(雙端口RAM)互連的松耦合不對稱處理器配置。系統(tǒng)結(jié)構(gòu)如圖1所示,圖中的各個處理器都具有自己的高速局部存儲器,可高速獨(dú)立的并行進(jìn)行計(jì)算,各個處理器之間由雙端口存儲器互連組成高速星型通信網(wǎng)絡(luò),由于雙端口存儲器具有很高的通信速率,靈活的通信協(xié)議建立方式,因此雙端口存儲器互連的松耦合多CPU 并行計(jì)算機(jī)具有如下優(yōu)點(diǎn):
⑴ 通信帶寬寬。CPU 訪問雙端口存儲器可以采用字節(jié)/字/雙字長度進(jìn)行,數(shù)據(jù)讀/寫速度高。
⑵ 結(jié)構(gòu)簡單。處理器和雙端口存儲器直接相連,不需要其它接口電路,可實(shí)現(xiàn)可靠的雙向信息傳送。
⑶ 具有可剪裁性。根據(jù)需要可增加或減少處理器數(shù)量。
⑷ 擴(kuò)展性強(qiáng)。該系統(tǒng)結(jié)構(gòu)可適合各種處理器。
圖1所示的多個處理器的計(jì)算機(jī)模型中,CPU可以采用Intel x86 系列、PowerPC 系列、ARM系列等處理器。Boot Processor(即主處理器)負(fù)責(zé)對系統(tǒng)管理,通過它可以協(xié)調(diào)各個Application Processor(即從處理器)的工作,同時(shí)Boot Processor 也對共享存儲器進(jìn)行初始化。為了提高系統(tǒng)的上電效率,每個處理器都需要帶有自己的fash 電子盤來存儲程序,每個處理器都可以外掛設(shè)備(比如網(wǎng)絡(luò)、鍵盤等)。
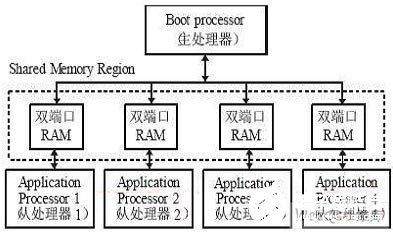
圖1 共享存儲器互連的并行計(jì)算機(jī)
3 多處理器并行計(jì)算機(jī)的軟件設(shè)計(jì)
為提高處理器的執(zhí)行效率,一般計(jì)算機(jī)系統(tǒng)都采用實(shí)時(shí)多任務(wù)操作系統(tǒng),本文以嵌入式VxWorks操作系統(tǒng)為基礎(chǔ)論述多CPU 并行計(jì)算機(jī)的軟件設(shè)計(jì)方法。
3.1 共享存儲器網(wǎng)絡(luò)
在VxWorks操作系統(tǒng)中,多CPU 之間的通信使用共享存儲器網(wǎng)絡(luò)技術(shù)(Shared-Memory BackplaneNetwork)。該技術(shù)采用虛擬網(wǎng)絡(luò)來管理共享存儲設(shè)備。共享存儲器網(wǎng)絡(luò)驅(qū)動允許多個處理器之間的通信采用網(wǎng)絡(luò)形式,使用規(guī)范符合BSD4.4 兼容模式。共享存儲器可以駐留在CPU 主板上也可以駐留在單獨(dú)的存儲器板上。
BP 代表Boot Processor(主處理器),AP 代表Application Processor(從處理器)。主處理器設(shè)置有主機(jī)路由200.200.200.0,從處理器可以通過主處理器與外網(wǎng)通信。主處理器必須有兩個網(wǎng)絡(luò)接口,一個用于和外網(wǎng)通信(如和VxWorks 開發(fā)主機(jī)Vx-Host 通信),IP 地址設(shè)置為如圖2 中的90.0.0.10;另外一個是虛擬的共享存儲器網(wǎng)絡(luò),用于和從處理器通信。從處理器配置的網(wǎng)絡(luò)IP 地址分別是200.200.200.1、200.200.200.2 和200.200.200.3。當(dāng)調(diào)試程序時(shí),首先由主處理器初始化共享內(nèi)存網(wǎng)絡(luò)(包括設(shè)置存儲器地址),從開發(fā)主機(jī)上下載自己的VxWorks image;然后,調(diào)度從處理器(AP)通過IP 地址90.0.0.10 從開發(fā)主機(jī)VxHost上下載從處理器所需要的VxWorks image,并且運(yùn)行該操作系統(tǒng),從機(jī)的一切調(diào)試均通過主處理器進(jìn)行。
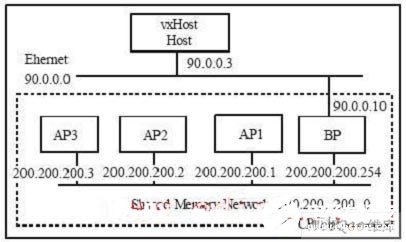
圖2 是多CPU 并行計(jì)算機(jī)網(wǎng)絡(luò)配置
共享存儲器網(wǎng)絡(luò)是VxWorks 的一個模塊,使用時(shí)必須在tornado的有關(guān)選項(xiàng)中選擇。對于每一個處理器都有一個自己的boorom 或VxWoks image,分別獨(dú)自運(yùn)行自己的操作系統(tǒng),彼此之間需要通信時(shí)通過共享存儲器進(jìn)行。
3.2 共享存儲器網(wǎng)絡(luò)主設(shè)備
多處理器系統(tǒng)中有一個處理器充當(dāng)主設(shè)備的角色。共享存儲器網(wǎng)絡(luò)主設(shè)備(Shared-MemoryNetwork Master)在系統(tǒng)中所起到的功能解釋如下:
⑴ 初始化共享存儲器區(qū)域和共享內(nèi)存鉤子(anchor);
⑵ 維護(hù)共享存儲器網(wǎng)絡(luò)心跳;
⑶ 作為其它處理器和外網(wǎng)通信的網(wǎng)關(guān);
⑷ 分配共享存儲區(qū)域。
在VxWorks 操作系統(tǒng)中要求共享存儲區(qū)域是一塊連續(xù)的存儲地址空間,默認(rèn)為16MB,在網(wǎng)絡(luò)驅(qū)動中所定義。主設(shè)備負(fù)責(zé)為其它處理器分配共享存儲區(qū)域,并且進(jìn)行內(nèi)存映射。共享存儲區(qū)的定位依靠系統(tǒng)配置。所有的處理器利用鉤子功能都必須能夠訪問該區(qū)域。共享存儲鉤子是所有處理器的通信參考點(diǎn)。鉤子結(jié)構(gòu)和共享內(nèi)存區(qū)域可以被放置在雙端口RAM中。鉤子包含真正存儲區(qū)域的物理地址偏移量,這在主設(shè)備在初始化過程中所設(shè)置,鉤子和存儲區(qū)域必須在相同的地址空間,地址必須是線性和有效的。
當(dāng)共享存儲器網(wǎng)絡(luò)主設(shè)備初始化后,所有的處理器才可以使用共享存儲器網(wǎng)絡(luò)。但是,主處理器并不能真正干涉其它處理器之間通過網(wǎng)絡(luò)進(jìn)行數(shù)據(jù)包的交互,各個處理器之間通信是通過本地的中斷或查詢方式進(jìn)行的。當(dāng)共享存儲器被初始化后,所有的處理器,包括主處理器,都同等的使用網(wǎng)絡(luò)。在Tornado2.0 環(huán)境下,主處理器號規(guī)定為0,系統(tǒng)通過處理號來識別主處理器和從處理器。典型的情況下,主處理器有兩個Internet 地址,分別用于外網(wǎng)通信和內(nèi)部網(wǎng)關(guān)。
3.3 共享存儲區(qū)的網(wǎng)絡(luò)心跳
在多CPU 系統(tǒng)中,所有的處理器只有當(dāng)共享存儲區(qū)域初始化后才可以通過網(wǎng)絡(luò)進(jìn)行通信,所以各個處理器需要知道共享網(wǎng)絡(luò)是否處于激活狀態(tài)或是就緒狀態(tài)。在這里采用心跳檢測的方法使各個處理器得知網(wǎng)絡(luò)的狀態(tài)。
心跳(heartbeat)是一個計(jì)數(shù)器,它被主處理器每1 秒進(jìn)行計(jì)數(shù),其他處理器靠監(jiān)視心跳值來確認(rèn)共享網(wǎng)絡(luò)是否處于正常。其他處理器監(jiān)視心跳一般是每隔幾秒進(jìn)行一次(根據(jù)具體情況而定)。共享存儲器心跳偏移地址被放置在共享存儲器包頭的第5個4 個節(jié)的字中。如圖3 所示。
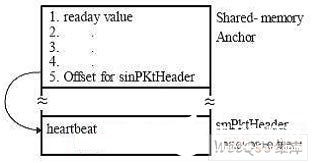
圖3 心跳數(shù)據(jù)包
3.4 處理器之間的通信
處理器之間通信可以采用中斷方式也可以采用查詢方式。每一個處理器都有一個輸入隊(duì)列用來接收其它處理器發(fā)送來得的數(shù)據(jù)包,當(dāng)采用查詢方式時(shí),處理器以固定時(shí)間間隔查詢隊(duì)列是否接收到數(shù)據(jù)。當(dāng)使用中斷方式時(shí),發(fā)送處理器通知接收處理器輸入隊(duì)列中有數(shù)據(jù)。中斷方式可以采用總線中斷或是郵箱中斷,它比查詢方式更有效。
多CPU 的并行系統(tǒng)類似于一個嵌入式分布式系統(tǒng),它們之間的通信可采用分布式消息隊(duì)列、分式數(shù)據(jù)庫技術(shù)。分布式消息隊(duì)列和分布式數(shù)據(jù)庫技術(shù)相結(jié)合,給系統(tǒng)中的所有處理器提供了一個透明化的通信平臺。處理器訪問分布式消息隊(duì)列,就好象是訪問自己的資源一樣。分布式消息隊(duì)列技術(shù)可以簡化應(yīng)用程序的設(shè)計(jì),加快系統(tǒng)開發(fā)。
3.5 多處理器之間的資源分配
在具有多處理器的單板計(jì)算機(jī)系統(tǒng)中,最重要的一點(diǎn)是要考慮任務(wù)的并行執(zhí)行效率,多個處理器均需要訪問外圍設(shè)備和進(jìn)行數(shù)據(jù)通信,這樣就存在外部設(shè)備的分配問題。
對設(shè)備資源的分配,有兩種:一是定制(即靜態(tài)分配),即單板計(jì)算機(jī)在設(shè)計(jì)時(shí)就將資源分配好,缺點(diǎn)是適應(yīng)性不強(qiáng),資源不能根據(jù)用戶的需求而改動;二是動態(tài)分配,在板上加載FPGA 邏輯,預(yù)留軟件接口,用戶可根據(jù)任務(wù)的要求動態(tài)指定。整個資源控制是透明的,不需要知道是哪個CPU控制。在硬件設(shè)計(jì)時(shí),要考慮對CPU及外部設(shè)備訪問的仲裁、優(yōu)先級設(shè)置等,防止由于訪問臨界資源而造成的沖突。軟件則應(yīng)該指定是那一個CPU使用特定設(shè)備,其余CPU 訪問時(shí)要互斥進(jìn)行。
4 多處理器并行計(jì)算機(jī)的性能
在該系統(tǒng)中采用CPU 類型為Intel Pentium3處理器,主頻是700MHz。測試方法,用相同功能的數(shù)據(jù)處理算法,將之分解為模塊,分別運(yùn)行在系統(tǒng)的各個處理器中。測試結(jié)果分析,和單CPU相比,采用兩塊CPU處理,運(yùn)算性能可提高60%“70%;采用三塊CPU,運(yùn)算性能至少達(dá)到2倍。我們知道,影響這個測試結(jié)果的最大因素是測試方法,將相同功能的算法分解到多個處理器,分解的方法直接決定綜合處理效率。但可以肯定,多個處理器并行處理設(shè)計(jì),可大大提高系統(tǒng)的運(yùn)算效率。
5 結(jié)束語
多CPU 的并行計(jì)算機(jī)技術(shù),在很大程度上提高了系統(tǒng)計(jì)算速度,突破了單CPU 處理速度的極限。同時(shí)采用多個CPU 的單板計(jì)算機(jī)設(shè)計(jì),可以減少計(jì)算機(jī)系統(tǒng)的體積、降低開發(fā)成本、減少系統(tǒng)的開發(fā)周期。本文中介紹的技術(shù),在我所設(shè)計(jì)的計(jì)算機(jī)系統(tǒng)中已經(jīng)實(shí)現(xiàn)并且得到軟硬驗(yàn)證,所采用的CPU 類型包括DSP、pentium3 等系列。
責(zé)任編輯:gt
-
處理器
+關(guān)注
關(guān)注
68文章
19165瀏覽量
229141 -
cpu
+關(guān)注
關(guān)注
68文章
10826瀏覽量
211158 -
操作系統(tǒng)
+關(guān)注
關(guān)注
37文章
6738瀏覽量
123190
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論