") 基于FPGA技術(shù)實(shí)現(xiàn)FFShark方案
基于FPGA技術(shù)實(shí)現(xiàn)FFShark方案
三端口可編程NIC設(shè)備,以其與生俱來(lái)的結(jié)構(gòu)優(yōu)勢(shì)在各種場(chǎng)景下都可以大顯身手,尤其是在網(wǎng)絡(luò)測(cè)量和網(wǎng)絡(luò)監(jiān)控領(lǐng)域。在FCCM2020會(huì)議上,一篇100G開源的類似于本公眾號(hào)之前介紹的1G“網(wǎng)絡(luò)監(jiān)兵”的研究文章(實(shí)驗(yàn)室自研產(chǎn)品介紹:一種多功能的三端口T型轉(zhuǎn)發(fā)器):FFShark: A 100G FPGA Implementation of BPF Filtering for Wireshark,介紹了100G速率下Wireshark的快速FPGA實(shí)現(xiàn)FFShark。這種設(shè)備對(duì)于網(wǎng)絡(luò)測(cè)量、網(wǎng)絡(luò)管理等很多具體的應(yīng)用具有非常重要的意義,但文中對(duì)添加上NIC設(shè)備之后對(duì)整個(gè)網(wǎng)絡(luò)造成影響的討論稍顯粗糙。我們結(jié)合最近的一些熱點(diǎn)話題可以分析一下。
最近幾天,老美又加大了對(duì)華為的約束,幾乎將華為逼上絕路。老美之所以費(fèi)盡心機(jī)的制裁華為,最重要的原因就是以5G為代表的網(wǎng)絡(luò)戰(zhàn)略地位的搶奪。網(wǎng)絡(luò),已不僅僅是數(shù)據(jù)通道,而是能夠傳輸互聯(lián)網(wǎng)時(shí)代生命之水的渠道。對(duì)數(shù)據(jù)而言,網(wǎng)絡(luò)就是上帝。誰(shuí)主宰了網(wǎng)絡(luò),誰(shuí)就能夠掌控未來(lái)!而華為現(xiàn)在就是能夠修這條新水渠的中國(guó)企業(yè),而以前的舊水渠是美國(guó)人修的,并且讓特朗普惱火的是,華為修這條新的水渠比他們修的快,還修的好。
網(wǎng)絡(luò)的重要,體現(xiàn)在當(dāng)代生活中的方方面面。比如筆者所在實(shí)驗(yàn)室做的適用于封閉空間的時(shí)間觸發(fā)以太網(wǎng)TTE網(wǎng)絡(luò)就是如此。誰(shuí)掌握了TTE網(wǎng)絡(luò)的規(guī)劃,誰(shuí)就掌管了話語(yǔ)權(quán)。網(wǎng)絡(luò)在傳遞數(shù)據(jù)信息之前,需要對(duì)整個(gè)網(wǎng)絡(luò)提前規(guī)劃,對(duì)整個(gè)網(wǎng)絡(luò)中的關(guān)鍵業(yè)務(wù)規(guī)劃調(diào)度表,另外還要求各個(gè)網(wǎng)絡(luò)節(jié)點(diǎn)之間能夠時(shí)間同步等等。網(wǎng)絡(luò)規(guī)劃者必須對(duì)整個(gè)系統(tǒng)里所有傳感器的每種業(yè)務(wù)都熟悉。所以,誰(shuí)規(guī)劃了整個(gè)網(wǎng)絡(luò),誰(shuí)就是總管,當(dāng)然就可以對(duì)所有網(wǎng)絡(luò)設(shè)備以及在網(wǎng)絡(luò)通道上的所有信息進(jìn)行“理所應(yīng)當(dāng)”的監(jiān)控。本文介紹的FFshark就可以做這件事情。
Mellanox Spectrum 4000以太網(wǎng)交換機(jī),每個(gè)端口支持400Gbps帶寬,交換容量高達(dá)25.4Tbps。首先數(shù)據(jù)緩沖架構(gòu)可以測(cè)量交換機(jī)的整體帶寬,進(jìn)而可以給每個(gè)端口分配一個(gè)均衡且可預(yù)測(cè)的帶寬:其次,無(wú)與倫比的虛擬化技術(shù),實(shí)現(xiàn)跨超大規(guī)模數(shù)據(jù)中心的VXLAN路由虛擬化;第三,你可以通過全新的WJH(What Just Happened)技術(shù)準(zhǔn)確掌握最新狀況。
可編程智能NIC,NVIDIA Mellanox Bluefield 2,世界上最先進(jìn)的可編程智能NIC,以最高200Gbps的線速度加速安全和數(shù)據(jù)包處理,網(wǎng)絡(luò)、存儲(chǔ)和安全協(xié)議棧現(xiàn)在被完全分離,運(yùn)行在這些可編程的智能NIC上,它將成為一個(gè)重要的基本數(shù)據(jù)處理單元。成為未來(lái)計(jì)算發(fā)展的三大支柱之一,CPU負(fù)責(zé)通用計(jì)算,GPU負(fù)責(zé)加速計(jì)算,DPU負(fù)責(zé)數(shù)據(jù)中心的數(shù)據(jù)傳輸和處理。
看完整個(gè)演講,筆者認(rèn)為,其實(shí),基于FPGA的NIC才是最重要的。因?yàn)椋还苁鞘裁碢U,都是先在FPGA上RUN起來(lái)之后再去ASIC化的。硬件加速的極限效果,或許是人類下一個(gè)PK的目標(biāo)。用硬件去實(shí)現(xiàn)軟件算法,幾塊FPGA板卡的運(yùn)算能力秒殺傳統(tǒng)的基于CPU軟件的超算或傳統(tǒng)數(shù)據(jù)中心已經(jīng)不再是夢(mèng)。
因此,掌握采用HDL語(yǔ)言來(lái)實(shí)現(xiàn)交換機(jī)和端節(jié)點(diǎn)可編程N(yùn)IC核心功能將成為未來(lái)決勝的最核心技術(shù)。而老黃手里的NIC設(shè)備,如果再增加上第三個(gè)端口,則立即可以實(shí)現(xiàn)本文所介紹的FFShark。下面我們就一起看一下FFShark這篇文章。
基于Wireshark的調(diào)試可以在普通桌面計(jì)算機(jī)上以1G的速度進(jìn)行,但只有功能強(qiáng)大的計(jì)算機(jī)才能跟上10G的速度,在100G時(shí),這種調(diào)試幾乎不可能在一臺(tái)計(jì)算機(jī)上進(jìn)行。
本文介紹了Wireshark的快速FPGA實(shí)現(xiàn)FFShark。其結(jié)果是一個(gè)緊湊的、相對(duì)便宜的直通設(shè)備,可以插入任何正在運(yùn)行的100G網(wǎng)絡(luò)中。數(shù)據(jù)包將在FFShark中傳輸,不會(huì)中斷,并且附加的延遲最小。開發(fā)人員可以隨時(shí)向FFShark設(shè)備發(fā)送標(biāo)準(zhǔn)的Wireshark過濾程序;滿足過濾條件的數(shù)據(jù)包將被復(fù)制并通過單獨(dú)的連接發(fā)送回開發(fā)人員的工作站。
我們展示了我們的開源直通設(shè)備比商用100G交換機(jī)具有更低的延遲,并且我們的設(shè)計(jì)已經(jīng)能夠處理400G的速度。
1. 引言
Wireshark[1]是一個(gè)軟件工具,允許網(wǎng)絡(luò)開發(fā)人員和管理員在不中斷通信的情況下檢查實(shí)時(shí)網(wǎng)絡(luò)數(shù)據(jù)包。此檢查要求捕獲指定的數(shù)據(jù)包子集,然后可以分析數(shù)據(jù)包的相關(guān)字段。這種能力對(duì)于網(wǎng)絡(luò)分析和調(diào)試是非常寶貴的。Wireshark的一個(gè)主要優(yōu)點(diǎn)是它使用了BSD包過濾器(BPF),大多數(shù)操作系統(tǒng)內(nèi)核都支持BPF。BPF技術(shù)減少了內(nèi)存復(fù)制,并帶來(lái)了顯著的性能改進(jìn)。
高性能處理器可以在10G時(shí)進(jìn)行數(shù)據(jù)包過濾。當(dāng)我們移動(dòng)到100G或更高級(jí)別時(shí),使用Wireshark就變得不可能了。例如,第9代Intel i99900KS處理器配備16個(gè)PCIe3.0[2]通道,每個(gè)通道的最大帶寬為8 Gbps[3]。假設(shè)沒有開銷,從NIC到CPU的100 Gbps通信需要16個(gè)可用PCIe通道中13個(gè)的帶寬。除此之外,如果時(shí)鐘速度為5ghz[2],CPU將必須通過PCIe接收數(shù)據(jù)包,根據(jù)用戶的規(guī)范對(duì)其進(jìn)行過濾,并且可能以每32位字1.6個(gè)或更少的時(shí)鐘周期復(fù)制數(shù)據(jù)包。即使CPU以其他方式被卸載并且從未遭受緩存未命中,仍然不可能以這些速度執(zhí)行必要的篩選。在非常樂觀的假設(shè)下,積極的多線程處理可能會(huì)使CPU上的100G過濾成為可能,但這是不切實(shí)際的,而且無(wú)法擴(kuò)展到更快的速度。

圖1 FFShark的體系結(jié)構(gòu) 圖4中詳細(xì)說(shuō)明了通過部分,圖5中詳細(xì)說(shuō)明了過濾部分
為了使用Wireshark超過10 Gbps的速度,我們建議使用FFShark。 FFShark是一種開源[4],低延遲直通設(shè)備,可以放置在網(wǎng)絡(luò)中的任意兩個(gè)點(diǎn)之間。它支持以PCAP過濾器語(yǔ)法1 [5]編寫的任意過濾器。在調(diào)試中,它可用于對(duì)100G流量進(jìn)行全網(wǎng)分析,例如監(jiān)視兩個(gè)交換機(jī)之間或數(shù)據(jù)中心與廣域網(wǎng)之間的所有流量。FFShark的額外延遲成本與交換機(jī)相當(dāng),從而可以進(jìn)行實(shí)時(shí)系統(tǒng)測(cè)試。
FFShark使用FPGA技術(shù)實(shí)現(xiàn),其中并行的過濾器陣列將監(jiān)聽數(shù)據(jù)包數(shù)據(jù)(圖1)。過濾器被實(shí)現(xiàn)為FPGA架構(gòu)內(nèi)的CPU,并本地模擬BSD數(shù)據(jù)包過濾器虛擬機(jī)[6]。附加電路將傳入的高速網(wǎng)絡(luò)線路分配到多個(gè)較低速度的流中,每個(gè)過濾CPU一個(gè)。FFShark目前可以在真實(shí)的100G網(wǎng)絡(luò)中執(zhí)行Wireshark過濾,但是我們將證明FFShark可以以高達(dá)400G的速度正確運(yùn)行(第IV-C節(jié)),并且一旦收發(fā)器可用就可以立即使用。
本文的其余部分安排如下:第二節(jié)提供了Wireshark和BSD包過濾方法的背景討論。第三節(jié)介紹了相關(guān)工作。第四節(jié)詳細(xì)介紹了FFShark的設(shè)計(jì),包括高速技術(shù)和濾波CPU的設(shè)計(jì)。第五節(jié)介紹了實(shí)施結(jié)果。最后,第六節(jié)討論了今后的工作,第七節(jié)對(duì)論文進(jìn)行了總結(jié)。
2. 背景
在典型的桌面計(jì)算機(jī)上,所有傳入的數(shù)據(jù)包都由操作系統(tǒng)內(nèi)核處理,并復(fù)制到正確用戶應(yīng)用程序的內(nèi)存中。對(duì)于實(shí)時(shí)網(wǎng)絡(luò)調(diào)試,用戶應(yīng)用程序(如Wireshark)請(qǐng)求將數(shù)據(jù)包也復(fù)制到自己的內(nèi)存中。本節(jié)說(shuō)明Wireshark用于有效復(fù)制感興趣數(shù)據(jù)包的方法;此方法依賴于BSD數(shù)據(jù)包過濾技術(shù),本節(jié)也將對(duì)此進(jìn)行說(shuō)明。
2.1 Wireshark體系結(jié)構(gòu)
Wireshark允許開發(fā)人員從操作系統(tǒng)請(qǐng)求數(shù)據(jù)包的副本。此外,開發(fā)人員可能不希望看到所有數(shù)據(jù)包,因此Wireshark還允許隱藏不需要的數(shù)據(jù)包。最簡(jiǎn)單的實(shí)現(xiàn)是將每個(gè)數(shù)據(jù)包復(fù)制到Wireshark的內(nèi)存中,Wireshark僅顯示感興趣的數(shù)據(jù)包。一個(gè)更有效的解決方案是首先避免復(fù)制不需要的數(shù)據(jù)包。

圖2 標(biāo)準(zhǔn)Wireshark操作
圖2說(shuō)明Wireshark如何在標(biāo)準(zhǔn)操作系統(tǒng)環(huán)境中操作。開發(fā)人員以PCAP語(yǔ)法[5]輸入過濾器規(guī)范。例如,表達(dá)式tcp src port 100僅選擇源自端口100的tcp包。Wireshark將此表達(dá)式編譯為BPF機(jī)器代碼(在下一小節(jié)中描述),并使用內(nèi)核系統(tǒng)調(diào)用安裝篩選器代碼。到達(dá)網(wǎng)卡的數(shù)據(jù)包由內(nèi)核數(shù)據(jù)包處理通過套接字定向到相關(guān)的用戶應(yīng)用程序。此外,所有數(shù)據(jù)包都被復(fù)制到BPF過濾器,與過濾器代碼描述的過濾器匹配的任何數(shù)據(jù)包都被復(fù)制到Wireshark的用戶內(nèi)存中。
2.2 BSD包過濾器(BPF)
BPF方法源自以下觀察結(jié)果:“盡早就地過濾數(shù)據(jù)包會(huì)得到回報(bào)” [6]。使用這種方法,用戶提交一個(gè)BPF程序,內(nèi)核將在每個(gè)傳入的數(shù)據(jù)包上執(zhí)行該程序。這些程序是由OS內(nèi)核中的仿真器執(zhí)行的一系列機(jī)器代碼指令。任何與Wireshark兼容的操作系統(tǒng)都有責(zé)任正確模擬BPF計(jì)算機(jī)。內(nèi)核只會(huì)根據(jù)BPF程序的返回值將數(shù)據(jù)包復(fù)制回用戶。
BPF機(jī)器的簡(jiǎn)要概述如下。有兩個(gè)32位寄存器:累加器(A)和輔助(X)。該處理器對(duì)整個(gè)數(shù)據(jù)包(包括標(biāo)頭)具有字節(jié)可尋址的只讀訪問權(quán)限,對(duì)小型暫存存儲(chǔ)器具有讀/寫訪問權(quán)限。一條指令由其類(表I),尋址模式,跳轉(zhuǎn)偏移和立即值定義。BPF指令布局如圖3所示。
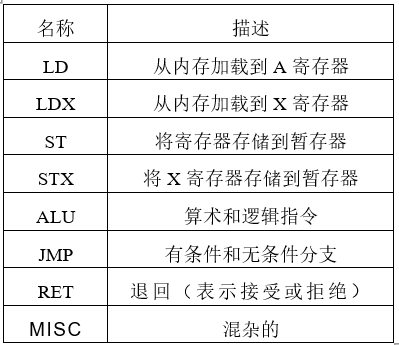
表1 BPF指令類

圖3 BPF指令布局。數(shù)字是位索引
3. 相關(guān)工作
Campbell和Lee[7]實(shí)現(xiàn)了一個(gè)僅使用普通硬件的100G入侵檢測(cè)系統(tǒng)(IDS)。使用100G路由器將數(shù)據(jù)包均勻地分發(fā)給多臺(tái)工作機(jī)[8]。為了進(jìn)一步減少單個(gè)機(jī)器上的負(fù)載,中央管理節(jié)點(diǎn)可以允許某些類型的流量在確定安全后繞過IDS。這個(gè)IDS的體系結(jié)構(gòu)需要一個(gè)100G負(fù)載均衡器和幾個(gè)高性能CPU機(jī)器的操作。這樣做的優(yōu)點(diǎn)是使用立即可用的零件,但不具有成本效益。
有許多商用100G網(wǎng)卡和交換機(jī)實(shí)現(xiàn)了對(duì)硬件包過濾的支持,每個(gè)網(wǎng)卡和交換機(jī)都提供自己的專有API。nBPF[9][10]可以將簡(jiǎn)單的PCAP表達(dá)式轉(zhuǎn)換為這些特定于供應(yīng)商的格式,但根據(jù)特定NIC支持的操作,只能翻譯有限的表達(dá)式子集。在nBPF利用商用100G硬件的過濾能力的地方,F(xiàn)FShark本機(jī)實(shí)現(xiàn)完整的BPF標(biāo)準(zhǔn),作為一個(gè)單獨(dú)的設(shè)備,可以插入到任何位置的網(wǎng)絡(luò)中。這滿足了我們保持與Wireshark完全兼容的目標(biāo)。
另一種類型的100G數(shù)據(jù)包過濾涉及根據(jù)高層過濾器描述自動(dòng)生成FPGA設(shè)計(jì)。這種方法利用了FPGA的高性能和可重新配置性,但是旨在滿足希望使用簡(jiǎn)單數(shù)據(jù)包過濾規(guī)范的系統(tǒng)管理員的需求。Xilinx netCope [11]根據(jù)P4過濾器規(guī)范[12]生成VHDL。此外,更高級(jí)的綜合技術(shù)可以使開發(fā)人員編寫自己的數(shù)據(jù)包過濾算法并在FPGA上實(shí)現(xiàn)。這些方法幾乎沒有支持交互地更改過濾器規(guī)格的方法。FFshark是符合標(biāo)準(zhǔn)BPF接口的FPGA覆蓋層,在更改過濾器時(shí)不需要生成新的FPGA配置。
FMAD Engineering提供了一種持續(xù)的100G數(shù)據(jù)包捕獲解決方案[13]。該產(chǎn)品是具有兩個(gè)QSFP28輸入端口和十個(gè)SSD的陣列的機(jī)架式盒子。設(shè)備接受BPF過濾器并保存接受的數(shù)據(jù)包以供以后查看。FMAD是一種商業(yè)產(chǎn)品,支持與FFShark相同的過濾功能,并且可以以高達(dá)100G的速度運(yùn)行。但是,F(xiàn)FShark是開源的,可供社區(qū)自定義和用于實(shí)驗(yàn)。FFShark還顯示可在400G網(wǎng)絡(luò)中使用。
Bittware生產(chǎn)具有包過濾功能的封閉源10/25/40/100G包代理設(shè)備[14]。這是具有四個(gè)QSFP28端口的PCIe擴(kuò)展卡。對(duì)于過濾,它支持10G速度和過濾器參數(shù)的運(yùn)行時(shí)配置,這些參數(shù)可以從PCAP過濾器表達(dá)式合成。通過更改FPGA映像,可以將解決方案升級(jí)為支持100G過濾,而無(wú)需其他硬件。該Bittware產(chǎn)品的說(shuō)明說(shuō),它支持“一組行業(yè)標(biāo)準(zhǔn)的PCAP ASCII表達(dá)式”,這意味著它不具備BPF引擎的全部靈活性,例如FFShark。同樣,就像剛剛描述的FMAD產(chǎn)品一樣,Bittware產(chǎn)品是一種商業(yè)產(chǎn)品,而FFShark則具有開源和為400G速度做好準(zhǔn)備的優(yōu)勢(shì)。
4. 設(shè)計(jì)
圖1顯示了FFShark的概述。該設(shè)計(jì)包括一個(gè)直通扇區(qū)(圖4)和一個(gè)過濾扇區(qū)(圖5)。使用Xilinx Zynq Ultrascale + XCZU19EG-FFVC1760-2I(MPSoC)來(lái)實(shí)現(xiàn)FPGA和ARM組件[15]。篩選扇區(qū)本身分為三個(gè)子組件:斬波器,多個(gè)BPF核心和轉(zhuǎn)發(fā)器。斬波器將高速輸入數(shù)據(jù)分為幾個(gè)以較低速度運(yùn)行的隊(duì)列。每個(gè)隊(duì)列都饋入一個(gè)BPF Core,后者執(zhí)行一個(gè)BPF過濾程序。最后,如果數(shù)據(jù)包被接受,則轉(zhuǎn)發(fā)器將其發(fā)送出過濾器。這些子組件中的每一個(gè)都在下面的單獨(dú)小節(jié)中詳細(xì)介紹。
4.1 直通扇區(qū)

圖4 直通扇區(qū)的設(shè)計(jì)
直通扇區(qū)如圖4所示。Ultrascale+器件中經(jīng)過100G加固的CMAC提供了稱為L(zhǎng)BUS的本地總線接口。由于所有其他Xilinx內(nèi)核都使用AXI,因此LBUS到AXIS轉(zhuǎn)換器電路[16]將PHY層的原始信號(hào)轉(zhuǎn)換為標(biāo)準(zhǔn)AXI流消息,反之亦然。AXI Streaming通道連接在一起,允許所有消息直接轉(zhuǎn)發(fā)到相對(duì)的端口。

圖5 過濾部分的設(shè)計(jì)
兩個(gè)QSFP28收發(fā)器的時(shí)鐘速度約為323 MHz,但由兩個(gè)獨(dú)立的時(shí)鐘驅(qū)動(dòng)。因此,需要其他邏輯將消息從一個(gè)時(shí)鐘域轉(zhuǎn)換到另一個(gè)時(shí)鐘域。盡管使用的時(shí)鐘略有不同,但兩個(gè)收發(fā)器的額定工作頻率均為100G,并且在業(yè)務(wù)突發(fā)之間存在間隙的情況下,可以維持此數(shù)據(jù)速率。添加了FIFO緩沖以允許這些隨機(jī)的短期突發(fā)。
直通流量通過AXI流通道發(fā)送。構(gòu)成此通道的連線也直接送入斬波器,從而使其能夠觀察到任何通過的通訊。
4.2 斬波器
過濾扇區(qū)旨在允許用戶指定任何過濾器(即BPF程序)。由于指令的數(shù)量(因此,程序運(yùn)行時(shí)間的長(zhǎng)度)事先未知,因此我們?cè)试S用戶在多個(gè)并行BPF內(nèi)核之間分配任務(wù),如圖5所示。為此,我們實(shí)現(xiàn)了一個(gè)帶有一個(gè)Chopper的Chopper。每個(gè)數(shù)據(jù)包過濾器一個(gè)輸出隊(duì)列。這也使我們能夠以較低的頻率為BPF CPU提供時(shí)鐘,從而大大減輕了復(fù)雜結(jié)構(gòu)的FPGA編譯負(fù)擔(dān)[17]。
這種架構(gòu)為我們提供了向上擴(kuò)展的巨大余地。BPF內(nèi)核具有最大可操作比特率;即使如此,當(dāng)?shù)?00G速度時(shí),斬波器也可以很容易地重新配置,以將輸入比特率分配到大量的較慢輸出隊(duì)列中。
斬波器在HLS中實(shí)現(xiàn)如下。單個(gè)AXI流輸入接收數(shù)據(jù)包。該輸入的時(shí)鐘頻率最高可達(dá)475 MHz,并且對(duì)輸入通道的數(shù)據(jù)寬度沒有限制。一個(gè)仲裁器,基于檢測(cè)到前向擁塞和緩沖區(qū)使用情況的探測(cè)器,并根據(jù)其最近的歷史上發(fā)送的前幾個(gè)數(shù)據(jù)包的位置,為每個(gè)數(shù)據(jù)包選擇一個(gè)輸出流,使每條輸出線的平均比特率保持在指定的量以下。決策邏輯與交叉開關(guān)分開,讓斬波器有一個(gè)較小的關(guān)鍵路徑。輸出決策基于四個(gè)周期的信息。但是,由于我們有足夠的輸出緩沖來(lái)容納至少一個(gè)數(shù)據(jù)包加四個(gè)濾波器,因此不會(huì)影響可靠性。數(shù)據(jù)包被認(rèn)為是不可分割的;來(lái)自輸入流的整個(gè)數(shù)據(jù)包被發(fā)送到相同的輸出流,其中數(shù)據(jù)被緩存在FIFO存儲(chǔ)器中。第二條電路從該FIFO存儲(chǔ)器中讀取數(shù)據(jù),并將其作為具有適當(dāng)時(shí)鐘速度和通道寬度的AXI流信號(hào)輸出,以支持BPF Core的最大比特率。
斬波器的仲裁部分將每條輸出線上的平均比特率設(shè)置為50 Gbps。但是,數(shù)據(jù)包的不可分割性要求斬波器使用165 Gbps的間歇性突發(fā)(在322MHz時(shí)為512位寬的信號(hào))來(lái)完成此任務(wù)。出于這個(gè)原因,數(shù)據(jù)需要進(jìn)行緩沖,因?yàn)锽PF內(nèi)核無(wú)法支持超過51.2Gbps的突發(fā)。為防止該FIFO緩沖區(qū)溢出,將容量設(shè)置為足夠大以緩沖兩個(gè)最大數(shù)據(jù)包(3kB或18kB,啟用巨型數(shù)據(jù)包)。即使尚未完全讀取數(shù)據(jù)包,緩沖區(qū)也可以接受整個(gè)新數(shù)據(jù)包。使用大小范圍從64B到9kB的隨機(jī)分組進(jìn)行的測(cè)試表明,當(dāng)平均輸入比特率保持在100 Gbps時(shí),不會(huì)丟失任何分組。
仲裁器能夠不考慮網(wǎng)絡(luò)流量的組成(即,大小分組的分布)而工作。然而,并行方法可能會(huì)導(dǎo)致數(shù)據(jù)包被記錄得不整齊。為了解決這個(gè)問題,每個(gè)傳入的包都會(huì)記錄一個(gè)時(shí)間戳(基于全局FPGA時(shí)鐘計(jì)數(shù)器),并將其添加到報(bào)頭。目前,軟件可以執(zhí)行包的重新排序任務(wù),但是,在硬件中進(jìn)行包的重新排序更為可取。一種選擇是完全刪除時(shí)間戳,而改為修改斬波器和轉(zhuǎn)發(fā)器,使數(shù)據(jù)包從不出差錯(cuò);這將具有最低的額外FPGA資源成本,并且只會(huì)遭受最大吞吐量的小損失。或者,一個(gè)通用的重排序緩沖器將以顯著增加片上存儲(chǔ)器成本為代價(jià)來(lái)保持最大吞吐量。這些進(jìn)展留作今后的工作。
4.3 時(shí)鐘
直通扇區(qū)在每個(gè)方向上使用一個(gè)時(shí)鐘為322 MHz的512位AXI流通道。每個(gè)通道支持的最大比特率為164 Gbps(322 MHz時(shí)為512b)。斬波器以全速監(jiān)聽此通道,并輸出幾個(gè)流,這些流以100 MHz的時(shí)鐘速度運(yùn)行,總線寬度為512位,比特率為51.2 Gbps,這是BPF內(nèi)核可接受的速度。每個(gè)BPF內(nèi)核都能夠以51.2 Gbps的相同速率輸出接受的數(shù)據(jù)包。
目前,我們沒有可用的400G硬件。但是,我們使用內(nèi)部生成的隨機(jī)數(shù)據(jù)包信號(hào)進(jìn)行了400G Chopper測(cè)試,該數(shù)據(jù)包的大小在40至9000字節(jié)之間,時(shí)鐘頻率為450MHz。總線寬度為1024位寬,最大位速率為460.8G。即使在這種比特率下,斬波器也能夠?qū)⑤斎胝_地分為51.2 Gbps的九個(gè)輸出信號(hào)(100 MHz的512位總線),而不會(huì)丟包。
4.4 BPF核心
當(dāng)前,Wireshark依靠OS內(nèi)核從網(wǎng)絡(luò)硬件接收數(shù)據(jù)包,并基于任意BPF程序執(zhí)行過濾。如第一節(jié)所述,即使功能強(qiáng)大的CPU機(jī)器也無(wú)法在100G時(shí)執(zhí)行這些任務(wù)之一。FFShark將過濾操作從OS內(nèi)核轉(zhuǎn)移到100G網(wǎng)絡(luò)中嵌入的直通設(shè)備,并使用稱為BPF內(nèi)核的并行處理器陣列執(zhí)行過濾(圖5)。

圖6 BPF核心
每個(gè)BPF內(nèi)核都配備了自己的指令存儲(chǔ)器和數(shù)據(jù)包存儲(chǔ)器,如圖6所示。來(lái)自斬波器的每個(gè)數(shù)據(jù)包都被復(fù)制到BPF內(nèi)核的數(shù)據(jù)包存儲(chǔ)器中。每個(gè)內(nèi)核的指令存儲(chǔ)器可以在運(yùn)行時(shí)通過外部配置總線加載BPF程序,該BPF程序?qū)⑨槍?duì)接收到的每個(gè)數(shù)據(jù)包執(zhí)行一次。程序使用RET指令使BPF內(nèi)核發(fā)出接受或拒絕信號(hào)。接受后,轉(zhuǎn)發(fā)器(第IV-G節(jié))會(huì)將數(shù)據(jù)包發(fā)送到外部存儲(chǔ)。
BPF CPU由一個(gè)數(shù)據(jù)路徑和一個(gè)控制器組成。圖7中詳細(xì)顯示了數(shù)據(jù)路徑。控制器通過三個(gè)階段進(jìn)行流水線處理:獲取,執(zhí)行和寫回。最后兩個(gè)階段通過控制信號(hào)線控制數(shù)據(jù)路徑,并支持除MUL,DIV和MOD(實(shí)際過濾應(yīng)用中很少使用)之外的所有BPF操作。有四個(gè)未連接到數(shù)據(jù)路徑的控制信號(hào):inst_rd_en和pack_rd_en信號(hào)直接連接到它們各自的存儲(chǔ)器,并且cpu_acc和cpu_rej用于向Ping-Pang-Pong互連發(fā)送信號(hào),如第IV-F節(jié)所述。數(shù)據(jù)路徑通過其inst_rd_data線連接到指令存儲(chǔ)器,并通過其pack_rd_addr和pack_rd_data線連接到分組存儲(chǔ)器。圖7中的所有其他連線都是內(nèi)部的,請(qǐng)勿離開模塊。
4.5 并行BPF核數(shù)的選擇
斬波器必須在具有最大可操作比特率的多個(gè)并行BPF內(nèi)核之間分配輸入流。但是,如果BPF程序很長(zhǎng)和/或BPF內(nèi)核被過多的小數(shù)據(jù)包淹沒,則每個(gè)內(nèi)核的有效比特率會(huì)降低,并且需要更多的比特率來(lái)支持100G帶寬。
本小節(jié)將提供一種用于估算所需并行核數(shù)的通用技術(shù),以及一個(gè)正在運(yùn)行的示例,如清單1所示。此清單顯示了tcp src端口100 PCAP過濾器表達(dá)式產(chǎn)生的BPF指令。對(duì)于我們正在運(yùn)行的示例,我們假設(shè)20%的輸入數(shù)據(jù)包既不使用IPv4也不使用IPv6,30%的數(shù)據(jù)包使用IPV4和UDP,25%的數(shù)據(jù)包使用IPv4和TCP,但不是來(lái)自源端口100,而25%的數(shù)據(jù)包 使用IPv4和TCP,并且來(lái)自源端口100。對(duì)于我們的示例,平均數(shù)據(jù)包長(zhǎng)度將為680B。
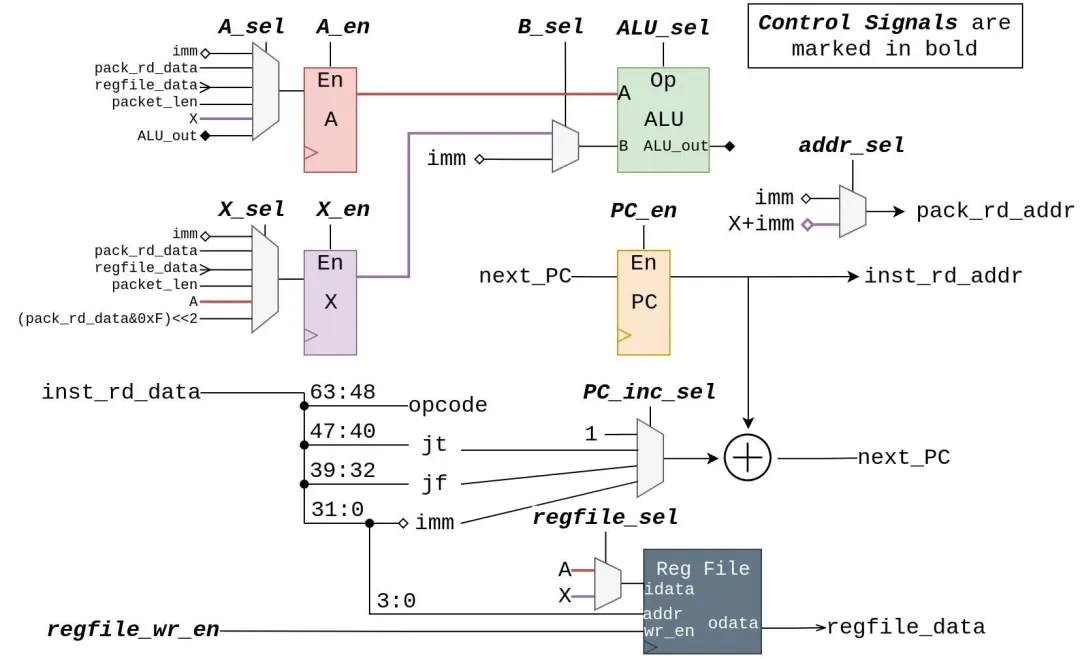
圖7 BPF CPU數(shù)據(jù)路徑

清單1 為PCAP篩選器tcp src端口100編譯的BPF機(jī)器代碼
通常,包的輸入流可以分為k個(gè)不同的類,其中每個(gè)類在過濾器代碼中觸發(fā)相同的執(zhí)行路徑。在我們的運(yùn)行示例中,k =4。類i中的每個(gè)數(shù)據(jù)包均具有長(zhǎng)度為Ii的指令的代碼路徑,并且具有平均長(zhǎng)度的中斷。最后,隨機(jī)選擇的輸入分組具有屬于類別i的概率Pi。表II中顯示了運(yùn)行示例的Ii,li和Pi的值。
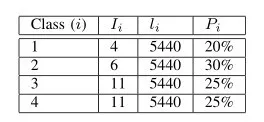
表2 i,li和Pi值,用于運(yùn)行第IV -E節(jié)中的示例
對(duì)于這些計(jì)算,我們將假設(shè)BPF CPU每條指令需要四個(gè)周期,即CPI =4。如果CPU以時(shí)鐘周期T秒運(yùn)行,那么BPF CPU(RCPU)的平均比特率為:

公式1中的分母表示CPU處理單個(gè)數(shù)據(jù)包所需的時(shí)間(以秒為單位)。
RCPU代表BPF CPU的比特率。但是,要選擇正確數(shù)量的BPF核心,請(qǐng)計(jì)算RCore,即BPF核心的比特率:

其中512位×100 MHz表示可用于填充BPF核心的分組存儲(chǔ)器的最大比特率(c.f.第IV-c節(jié))。
因此,所需的并行BPF核心數(shù)是N =“100G/RCore”。在我們的示例中,RCPU=19.8G,因此RCore=19.8G,N=6。在實(shí)際應(yīng)用程序中,F(xiàn)FShark用戶必須根據(jù)對(duì)正在調(diào)試的系統(tǒng)的了解,對(duì)k、Ii、li和pi進(jìn)行有根據(jù)的猜測(cè)。
一般來(lái)說(shuō),我們已經(jīng)發(fā)現(xiàn)六個(gè)并行核心足以用于常見的過濾器,例如選擇所有到/來(lái)自特定地址或端口范圍的數(shù)據(jù)包。更復(fù)雜的濾波器可能需要更多的BPF核,并且應(yīng)該完成所描述的估計(jì)所需數(shù)量的過程。然而,即使當(dāng)一個(gè)過濾器變得更復(fù)雜時(shí),過濾器代碼也能夠在被拒絕的包上提前終止,而被接受的包的比例通常會(huì)降低。考慮表3所示的例子:這個(gè)例子為一個(gè)過濾器建模,其中有更多的條件應(yīng)用于與我們前面的例子相同的流量模式。具體來(lái)說(shuō),過濾器檢查包含數(shù)據(jù)的任何HTTP包。類1和類2仍然被提前拒絕,類4在被拒絕之前需要另外兩條指令。然而,類3分為兩類:3a是通過新過濾器的某些條件但最終被拒絕的包,3b是通過所有條件的包。即使接受包的指令數(shù)要大得多,在本例中,所需的并行核心數(shù)仍然是6。

表3 Ii、li和PiVALUES用于過濾器TCP端口80和((IP[2:2]-((IP[0]&0XF)>2))!=0)
4.6 乒乓控制器
BPF內(nèi)核是一個(gè)BPF CPU,配備了一個(gè)指令存儲(chǔ)器和一個(gè)數(shù)據(jù)包存儲(chǔ)器(圖6)。立即我們注意到,包內(nèi)存在三個(gè)代理之間共享:斬波器,BPF CPU和轉(zhuǎn)發(fā)器。一個(gè)重要的性能優(yōu)化是“乒乓球”緩沖區(qū),如圖8所示。此方案使所有三個(gè)代理可以同時(shí)全速訪問內(nèi)存。

圖8 乒乓緩沖區(qū)
自定義互連維護(hù)三個(gè)fifo,表示每個(gè)代理的作業(yè)隊(duì)列。在任何給定時(shí)刻,多路復(fù)用器都會(huì)使用代理隊(duì)列頭部的令牌將代理與Ping、Pang或Pong緩沖區(qū)之一連接。
圖9展示了實(shí)際的技術(shù)。左上角的塊表示作業(yè)隊(duì)列的初始狀態(tài),可以理解為“所有三個(gè)緩沖區(qū)都在等待斬波器讀取數(shù)據(jù)包,斬波器當(dāng)前連接到Ping緩沖區(qū)”。當(dāng)斬波器完成將數(shù)據(jù)包讀入Ping緩沖區(qū)時(shí),Ping令牌將從斬波器隊(duì)列中彈出并添加到CPU隊(duì)列(右上角塊)。此時(shí),斬波器現(xiàn)在連接到Pang緩沖區(qū),CPU開始在Ping緩沖區(qū)中處理數(shù)據(jù)包。左下角的塊顯示了如果斬波器在CPU完成其程序執(zhí)行之前讀取完數(shù)據(jù)包會(huì)發(fā)生什么情況:Pang令牌從斬波器隊(duì)列中彈出并添加到CPU隊(duì)列中。右下角的圖顯示了CPU接受數(shù)據(jù)包的結(jié)果:Ping令牌從CPU隊(duì)列中彈出并添加到轉(zhuǎn)發(fā)器隊(duì)列中。

圖9 乒乓球互連中的作業(yè)隊(duì)列
4.7代理
接收到數(shù)據(jù)包后,BPF核心將Ping,Pang或Pong緩沖區(qū)之一放在轉(zhuǎn)發(fā)器的工作隊(duì)列上。然后,轉(zhuǎn)發(fā)器從緩沖區(qū)讀取并在512位寬的AXI流(以100 MHz輸出)上輸出數(shù)據(jù)包數(shù)據(jù)。
如果目標(biāo)FPGA器件配備了三個(gè)(或更多)QSFP28端口,則可以重新組合接受的數(shù)據(jù)包流并以全100G速率發(fā)送出去。這項(xiàng)工作中使用的FPGA只有兩個(gè)QSFP28端口,但是具有到連接的ARM CPU的高帶寬通道。
從Vega等人的工作中借鑒[18],擴(kuò)展了它們的協(xié)議,實(shí)現(xiàn)了FPGA與ARM處理器之間的雙向消息傳輸。使用該方案,我們能夠連接來(lái)自BPF核心的已接受數(shù)據(jù)包并將其轉(zhuǎn)發(fā)到ARM核心。還添加了一個(gè)頭,以允許一些元數(shù)據(jù)隨數(shù)據(jù)包一起傳輸。一旦進(jìn)入ARM核心,就可以根據(jù)需要處理消息。出于功能目的,初始測(cè)試將過濾后的消息打印到ARM處理器的終端上。為了更實(shí)際的實(shí)現(xiàn),單獨(dú)開發(fā)的存儲(chǔ)系統(tǒng)[19]允許我們可靠地、低開銷地將收集到的消息存儲(chǔ)到遠(yuǎn)程存儲(chǔ)服務(wù)器。該系統(tǒng)可同時(shí)供FPGAs和cpu使用。然而,由于我們?nèi)鄙俚谌齻€(gè)網(wǎng)絡(luò)端口,數(shù)據(jù)包被轉(zhuǎn)發(fā)到ARM以使用ARM的網(wǎng)絡(luò)端口。
為了將這個(gè)通道用于接收的數(shù)據(jù)包流,我們?yōu)檗D(zhuǎn)發(fā)器構(gòu)建了一個(gè)自定義數(shù)據(jù)寬度轉(zhuǎn)換器,該轉(zhuǎn)換器將時(shí)鐘保持在100MHz,但將總線寬度減小到64位(比特率為6.4 Gbps)。對(duì)于ARM處理器而言,這足夠慢以接收接受的數(shù)據(jù)包。如果接受的數(shù)據(jù)包的帶寬超過了此6.4 Gbps瓶頸的速度,則“過濾扇區(qū)”將丟棄數(shù)據(jù)包,但“直通扇區(qū)”不會(huì)受到影響。
5. 結(jié)果與討論
對(duì)于這些結(jié)果,F(xiàn)FShark系統(tǒng)在Zynq Ultrascale + XCZU19EG-FFVC1760-2-I上實(shí)現(xiàn)[15]。該芯片在同一硅芯片上包括FPGA和ARM CPU。兩者可以通過幾個(gè)高速AXI通道進(jìn)行通信。FPGA具有110萬(wàn)個(gè)邏輯元件和9.8 MB的片上存儲(chǔ)器。該處理器是64位ARM Cortex-A53。該芯片是Fidus Sidewinder 100 [15] FPGA板的一部分,該板將MPSoC連接到兩個(gè)QSFP28 4x25G端口,一個(gè)1G以太網(wǎng)端口以及許多其他外設(shè)。
為了表征FFShark的性能,我們收集了三種測(cè)量方法:增加的直通業(yè)務(wù)延遲、包丟棄率、濾波器和直通扇區(qū)的性能以及設(shè)計(jì)所需的FPGA資源數(shù)量。
5.1 插入延遲
此測(cè)試的目標(biāo)是測(cè)量lP,即FFShark的passthrough扇區(qū)的插入延遲,定義為數(shù)據(jù)包在一個(gè)QSFP端口上進(jìn)入另一個(gè)QSFP端口上離開所用的時(shí)間。圖10概述了測(cè)試設(shè)置。圖中的每個(gè)灰盒代表一個(gè)側(cè)板,每個(gè)連接都是2 m 100G電纜。UDP被選為具有一致延遲的輕量級(jí)可路由協(xié)議,可以從總延遲中減去。

圖10 延遲測(cè)量的測(cè)試設(shè)置
測(cè)量了直接連接的往返時(shí)間,如圖10a所示。此數(shù)量用LD表示,并表示數(shù)據(jù)包到達(dá)以下狀態(tài)所花費(fèi)的時(shí)間:
1)100G UDP內(nèi)核進(jìn)行處理[16]
2)穿過2 m的電纜(lC)
3)進(jìn)入和退出環(huán)回
4)傳遞通過2 m的電纜。
5)返回流量生成器后,由100G UDP核心進(jìn)行處理。
當(dāng)數(shù)據(jù)包發(fā)送到UDP核心時(shí)(步驟1),以及數(shù)據(jù)包返回后離開UDP核心時(shí)(步驟5),流量生成器板都會(huì)保存時(shí)間戳。
接下來(lái),如圖10b所示,測(cè)量包括FFShark的往返時(shí)間。該數(shù)量用LP表示。

表4 直接連接和通過測(cè)試的往返時(shí)間
表IV列出了各種數(shù)據(jù)包大小(包括36字節(jié)UDP報(bào)頭)的LD和LP的測(cè)量值,連續(xù)100G傳輸中平均超過4000個(gè)數(shù)據(jù)包。給定通過銅電纜的傳播速度,發(fā)現(xiàn)2 m電纜的傳播延遲lC為0.009μs[20]。圖11示出了計(jì)算值lP =(LP-LD-2·lC)/ 2。用Dell Z9100-ON 100G交換機(jī)代替FFShark進(jìn)行了類似的測(cè)試,如圖10c所示。在圖11中還示出了該交換機(jī)ls的測(cè)量的插入等待時(shí)間,以呈現(xiàn)FFShark和商品100G硬件之間的比較。請(qǐng)注意,該交換機(jī)不支持大于MTU限制1.5KB的數(shù)據(jù)包。

圖11 FFShark(LP)與Dell Z9100-ON 100G交換機(jī)(LS)的插入等待時(shí)間
小于100字節(jié)的數(shù)據(jù)包記錄了更高的延遲。這是由于我們的測(cè)試超出了第V-D節(jié)中所述的小數(shù)據(jù)包的最大數(shù)據(jù)包速率。當(dāng)比特率降低時(shí),大小為100字節(jié)或更小的數(shù)據(jù)包的插入等待時(shí)間大約等于164字節(jié)大小的數(shù)據(jù)包的測(cè)試等待時(shí)間(約0.3μs)。此外,F(xiàn)FShark的延遲隨著數(shù)據(jù)包大小的增加而增加。目前,我們正在使用Xilinx CMAC控制器,這迫使我們存儲(chǔ)和轉(zhuǎn)發(fā)整個(gè)數(shù)據(jù)包,而不是使用直通方法。
5.2 最高性能
為了測(cè)試最高性能,通過FFShark以全100G比特率將32768個(gè)數(shù)據(jù)包(大小從16B到1500B)發(fā)送到回送設(shè)備,并在原始位置重新收集。原始設(shè)備驗(yàn)證了數(shù)據(jù)包的完整性,并計(jì)算了丟失或損壞的數(shù)據(jù)包的數(shù)量。在此高度擁塞的應(yīng)用程序中,正確返回了99.41%的數(shù)據(jù)包。沒有數(shù)據(jù)包被返回?fù)p壞。修改測(cè)試以測(cè)試大小在176B到1500B之間的數(shù)據(jù)包時(shí),沒有數(shù)據(jù)包被丟棄。V-D節(jié)探討了這些數(shù)據(jù)包丟棄的來(lái)源。可以添加握手或流控制來(lái)減輕這些數(shù)據(jù)包丟失。
已顯示直通扇區(qū)和過濾扇區(qū)永遠(yuǎn)不會(huì)丟失數(shù)據(jù)包4。通過多次運(yùn)行測(cè)試來(lái)證明這一點(diǎn),在該測(cè)試中,具有唯一標(biāo)頭的單個(gè)數(shù)據(jù)包被隱藏在100G流量突發(fā)中的不同位置。對(duì)數(shù)據(jù)包過濾器進(jìn)行編程以檢測(cè)簽名。在所有情況下,F(xiàn)FShark都能正確識(shí)別數(shù)據(jù)包并將其轉(zhuǎn)發(fā)給ARM,而忽略所有其他數(shù)據(jù)包。
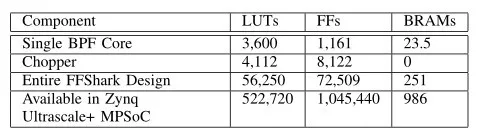
表5 FFSHARK和所選子組件的資源使用
5.3 資源使用
表5顯示了該項(xiàng)目的資源使用情況。前兩行顯示單個(gè)BPF Core和Chopper的資源使用情況。第三行顯示了最終FFShark設(shè)計(jì)的全部成本;該表包括六個(gè)BPF內(nèi)核,一個(gè)斬波器,以及直通扇區(qū)以及將指令存儲(chǔ)器和轉(zhuǎn)發(fā)器與板載ARM CPU接口所需的額外邏輯。此設(shè)計(jì)中未使用DSP。由于此設(shè)計(jì)僅使用FPGA總?cè)萘康囊恍〔糠郑虼耸S噘Y源可用于添加更多的過濾核心,或?qū)FShark嵌入更大的設(shè)計(jì)中。或者,可以將FFShark放置在更小,更便宜的FPGA上。
5.4 討論
在包含小于176B的數(shù)據(jù)包(100G比特率)的測(cè)試中,發(fā)現(xiàn)了高延遲和偶爾的數(shù)據(jù)包丟棄。已經(jīng)發(fā)現(xiàn),F(xiàn)PGA上的100G CMAC和收發(fā)器具有每個(gè)數(shù)據(jù)包的開銷[21],除了最大比特率約束之外,還創(chuàng)建了最大數(shù)據(jù)包率約束。在使用小數(shù)據(jù)包的測(cè)試中,每秒的數(shù)據(jù)包數(shù)超過了此最大值,并且網(wǎng)絡(luò)硬件開始施加反壓。GULF流UDP內(nèi)核具有內(nèi)部緩沖區(qū),可以暫時(shí)緩解此問題。然而,隨著這些緩沖區(qū)的填滿,數(shù)據(jù)包的積壓意味著等待時(shí)間線性增加,導(dǎo)致在較小的數(shù)據(jù)包大小下出現(xiàn)高等待時(shí)間,如第V-A節(jié)所示。最終,GULF流FIFO完全填滿,導(dǎo)致在V-B節(jié)中看到的基于擁塞的數(shù)據(jù)包丟失很少。對(duì)于較小的數(shù)據(jù)包大小,當(dāng)降低比特率時(shí),對(duì)于所有數(shù)據(jù)包大小,數(shù)據(jù)包丟棄都會(huì)停止,并且延遲遵循相同的趨勢(shì)。
除了基于硬件的限制之外,F(xiàn)FShark的性能達(dá)到了預(yù)期的目標(biāo),與高端100G交換機(jī)相比,它增加了更小的延遲,并且不影響數(shù)據(jù)包數(shù)據(jù)。當(dāng)不超過轉(zhuǎn)發(fā)器的帶寬時(shí),篩選器可以檢查100%的傳入數(shù)據(jù)包。
總體設(shè)計(jì)僅占用FPGA資源的不到四分之一,并且Chopper能夠以400G的速度正確分配輸入流。當(dāng)MAC /收發(fā)器支持可用時(shí),這會(huì)使FFShark立即擴(kuò)展到400G。
6. 未來(lái)的工作
這項(xiàng)工作具有廣闊的發(fā)展前景,因?yàn)樗梢詳U(kuò)展到各種速度,并且用途廣泛。雖然在這種情況下,它用于交互式分析網(wǎng)絡(luò)流量,但可以通過修改直通扇區(qū)來(lái)調(diào)試任何類型的數(shù)據(jù)通信。例如,PCIe信號(hào)也可以轉(zhuǎn)換為AXI流,并以類似方式進(jìn)行[P1] 觀察。FFShark還可以用于監(jiān)視和調(diào)試FPGA設(shè)計(jì)中的常規(guī)信號(hào)。
尋找和是否可以修改BPF語(yǔ)言以更好地用作交互式調(diào)試工具是一個(gè)研究問題。例如,eBPF[22]在Linux內(nèi)核中用于跟蹤文件系統(tǒng)調(diào)用,創(chuàng)建I/O傳輸?shù)闹狈綀D以及其他高級(jí)調(diào)試任務(wù)。并非eBPF支持的所有功能都能很好地映射到FPGA實(shí)現(xiàn)中,但是共享內(nèi)存模型對(duì)于以100G的速度收集全局統(tǒng)計(jì)信息至關(guān)重要。
BPF Core是可以接受任意程序的處理器。盡管通用統(tǒng)計(jì)信息易于收集,但我們希望為用戶創(chuàng)建一種方法,以編程新類型的測(cè)量并讓該系統(tǒng)報(bào)告實(shí)時(shí)值。然后,SDN應(yīng)用程序可以使用這些自定義統(tǒng)計(jì)信息來(lái)改進(jìn)路由和其他決策。
當(dāng)前這項(xiàng)工作與Wireshark兼容,因?yàn)樗褂孟嗤腂PF機(jī)器代碼并返回相同的結(jié)果。但是,需要一些工作才能將其與Wireshark代碼庫(kù)集成在一起,以便可以使用熟悉的Wireshark GUI和實(shí)用程序。這可以通過創(chuàng)建一個(gè)自定義OS網(wǎng)絡(luò)驅(qū)動(dòng)程序來(lái)完成,該驅(qū)動(dòng)程序?qū)⒑Y選器程序傳輸?shù)紽FShark,而不是在內(nèi)核中執(zhí)行它們。
7. 結(jié)論
我們創(chuàng)建了一個(gè)工作在100G的直通設(shè)備,可以對(duì)其進(jìn)行編程以標(biāo)記和存儲(chǔ)觀察到的數(shù)據(jù)包的子集。該子集使用PCAP過濾語(yǔ)言指定,允許用戶繼續(xù)使用熟悉的語(yǔ)法。該器件還被證明可以在全100G的速度下運(yùn)行而不會(huì)丟包,并且一旦收發(fā)器和FPGA網(wǎng)絡(luò)支持可用,它就可以立即擴(kuò)展到400G。與商用100G交換機(jī)相比,該設(shè)備為網(wǎng)絡(luò)數(shù)據(jù)增加了400ns的延遲。由于網(wǎng)絡(luò)設(shè)計(jì)期望延遲在此范圍內(nèi),并且FFShark不會(huì)顯著改變環(huán)境,因此這證明它可用于實(shí)時(shí)環(huán)境中的調(diào)試。
8. 致謝
M.A.Merlini和J.C.V.ega是這項(xiàng)工作的同等貢獻(xiàn)者。作者們要感謝匿名評(píng)論者的深刻反饋。我們感謝Edward S.Rogers高級(jí)電氣和計(jì)算機(jī)工程系、安大略大學(xué)研究生獎(jiǎng)學(xué)金、華為、Xilinx和NSERC的資助。最后,我們感謝Xilinx和Fidus系統(tǒng)捐贈(zèng)芯片、工具和支持。
9. 參考文獻(xiàn)
[1] Wireshark, “Wireshark User’s Guide Version 3.3.0,” 2018, https://www. wireshark.org/docs/wsug html/.
[2] Intel, “Intel Core I9 9900KS processor speci?cations,” 2019, https://www.intel.ca/content/www/ca/en/products/processors/core/i9-proce....
[3] PCIe-Consortium, “PCI Express? Base Speci?cation Revision 3.0,” PCIe Group, pp. 1–860, 2010, http://www.lttconn.com/res/lttconn/pdres/ 201402/20140218105502619.pdf.
[4] M. Merlini and C. Vega, “A versatile Wireshark-compatible packet ?lter, capable of 100G speeds and higher,” 2020, https://github.com/ UofT-HPRC/fpga-bpf.
[5] V. Jacobson, C. Leres, and S. McCanne, pcap-?lter(7) - Linux man page, Lawrence Berkely National Laboratory.
[6] S. McCanne and V. Jacobson, “The BSD Packet Filter: A New Archi- tecture for User-level Packet Capture.” in USENIX winter, vol. 46, 1993.
[7] S. Campbell and J. Lee, “Prototyping a 100G monitoring system,” in 2012 20th Euromicro International Conference on Parallel, Distributed and Network-based Processing.IEEE,2012,pp.293–297.
[8] V. Paxson, “Bro: a system for detecting network intruders in real-time,”Computer networks, vol. 31, no. 23-24, pp. 2435–2463, 1999.
[9] A.Cardigliano,“PF-RING-nBPF,”92019,https://github.com/ntop/PFRING/tree/dev/userland/nbpf.
[10] D. Luca, “nBPF,” Sharkfest Europe, pp. 26–37, 2016, https:// sharkfesteurope.wireshark.org/assets/presentations16eu/02.pdf.
[11] “NetcopeP4,”productBrief.[Online].Available:https://www.xilinx. com/products/intellectual-property/1-pcz517.html
[12] “P4 Language Speci?cation,” 2019. [Online]. Available: https://p4.org/ p4-spec/docs/P4-16-v1.2.0.pdf
[13] “Full Line Rate Sustained 100Gbit Packet Capture,” product Brief. [On- line]. Available: https://www.fmad.io/products-100G-packet-capture. html
[14] “10/25/40/100G Packet Broker with PCAP Filtering,” product Brief. [Online]. Available: https://www.bittware.com/ 102540100g-packet-broker-with-pcap-?ltering/
[15] Fidus, “Sidewinder-100 Datasheet,” 2018, https://?dus.com/wp-content/ uploads/2019/01/Sidewinder Data Sheet.pdf.
[16] Q. Shen, “100G UDP Link for FPGAs though AXI STREAM (GULF STREAM),” 2019, https://github.com/UofT-HPRC/GULF-Stream.
[17] R. Fung, V. Betz, and W. Chow, “Simultaneous Short-Path and Long- Path Timing Optimization for FPGAs,” IEEE/ACM International Confer- ence on Computer Aided Design, pp. 838–845, 2004, https://ieeexplore. ieee.org/document/1382691.
[18] J. Vega, Q. Shen, A. Leon-Garcia, and P. Chow, “Introducing ReCPRI: A Field Re-con?gurable Protocol for Backhaul Communication in a Radio Access Network,” IEEE/IFIP International Symposium on Integrated Network Management, pp. 329–336, 2019, https://ieeexplore.ieee.org/ document/8717902.
[19] J. Vega, “SHIP: A Storage System for Hybrid Interconnected Proces- sors,” Master’s thesis, University of Toronto, Department of Electrical and Computer Engineering, Apr. 2020.
[20] Mellanox, “100Gb/s QSFP28 Direct Attach Copper Cable,” 2018, https://www.mellanox.com/related-docs/prod cables/PB MCP1600-Exxx 100Gbps QSFP28 DAC.pdf.
[21] Xilinx, “UltraScale Devices Integrated 100G Ethernet Subsystem v2.5,” 2019, https://www.xilinx.com/support/documentation/ip documentation/ cmac/v2 5/pg165-cmac.pdf.
[22] B. Gregg, BPF Performance Tools. Addison-Wesley Professional, 2019.
編輯:hfy
-
FPGA
+關(guān)注
關(guān)注
1626文章
21671瀏覽量
601902 -
斬波器
+關(guān)注
關(guān)注
0文章
60瀏覽量
9145 -
以太網(wǎng)交換機(jī)
+關(guān)注
關(guān)注
0文章
124瀏覽量
14220 -
PCAP
+關(guān)注
關(guān)注
0文章
12瀏覽量
12598
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
如何實(shí)現(xiàn)FPGA的IO輸出脈沖信號(hào)放大?
FPGA技術(shù)的主要應(yīng)用
基于FPGA的人臉識(shí)別技術(shù)
FPGA無(wú)芯片HDMI接入方案及源碼
FPGA實(shí)現(xiàn)LeNet-5卷積神經(jīng)網(wǎng)絡(luò)
如何在FPGA上實(shí)現(xiàn)神經(jīng)網(wǎng)絡(luò)
采用創(chuàng)新的FPGA 器件來(lái)實(shí)現(xiàn)更經(jīng)濟(jì)且更高能效的大模型推理解決方案
珠海鏨芯實(shí)現(xiàn)28納米FPGA流片
基于FPGA設(shè)計(jì)頻率計(jì)方案介紹分享
深度剖析FPGA實(shí)現(xiàn)ARM系統(tǒng)處理的解決方案

科普 | 一文了解FPGA技術(shù)知識(shí)
FPGA實(shí)現(xiàn)原理
IIC總線的FPGA實(shí)現(xiàn)說(shuō)明
如何能夠實(shí)現(xiàn)通用FPGA問題?
集成電源解決方案-Altera FPGA應(yīng)用介紹






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論