 深層神經網絡模型的訓練:過擬合優化
深層神經網絡模型的訓練:過擬合優化
·過擬合(Overfitting)
深層神經網絡模型的訓練過程,就是尋找一個模型能夠很好的擬合現有的數據(訓練集),同時能夠很好的預測未來的數據。
在訓練過程中由于模型建立的不恰當,往往所訓練得到的模型能夠對訓練集的數據非常好的擬合,但是卻在預測未來的數據上表現得非常差,這種情況就叫做過擬合(Overfitting)。
為了訓練出高效可用的深層神經網絡模型,在訓練時必須要避免過擬合的現象。過擬合現象的優化方法通常有三種,分別是:正則化(Regulation),擴增訓練集(Data augmentation)以及提前停止迭代(Early stopping)。
·正則化(Regulation)
正則化方法是指在進行損失函數(costfunction)優化時,在損失函數后面加上一個正則項。
正則化方法中目前常用的有兩種方法:L2 正則化和 Dropout 正則化。
L2 正則
L2 正則是基于 L2 范數,即在函數后面加上參數的 L2 范數的平方,即:
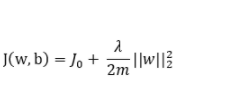
其中J0是原損失函數,m 表示數據集的大小。使用下式對參數進行更新:
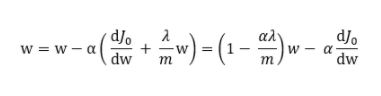
其中 ,因此知道 w 在進行權重衰減。在神經網絡中,當一個神經元的權重越小時,那么該神經元在神經網絡中起到的作用就越小,當權重為 0 時,那么該神經元就可以被神經網絡剔除。而過擬合現象出現的原因之一就是,模型復雜度過高。那么,也就是說 L2 正則化后,權重會衰減,從而降低了模型的復雜度,從而一定程度上避免對數據過擬合。
,因此知道 w 在進行權重衰減。在神經網絡中,當一個神經元的權重越小時,那么該神經元在神經網絡中起到的作用就越小,當權重為 0 時,那么該神經元就可以被神經網絡剔除。而過擬合現象出現的原因之一就是,模型復雜度過高。那么,也就是說 L2 正則化后,權重會衰減,從而降低了模型的復雜度,從而一定程度上避免對數據過擬合。
隨機失活(Dropout)正則
其實 Dropout 的思路與 L2 的思路是一致的,都是降低模型的復雜度,從而避免過擬合。只是實現的方法有所不同。
Dropout 的做法是,在訓練過程中,按照一定的概率隨機的忽略掉一些神經元,使其失活,從而就降低了模型的復雜度,提高了泛化的能力,一定程度上避免了過擬合。

常用的實現方法是 InvertedDropout。
使用 Dropout 的小技巧
·1、通常丟棄率控制在 20%~50%比較好,可以從 20%開始嘗試。如果比例太低則起不到效果,比例太高則會導致模型的欠學習。
·2、在大的網絡模型上應用。當 dropout 用在較大的網絡模型時更有可能得到效果的提升,模型有更多的機會學習到多種獨立的表征。
·3、在輸入層(可見層)和隱藏層都使用 dropout。在每層都應用 dropout 被證明會取得好的效果。
·4、增加學習率和沖量。把學習率擴大 10~100 倍,沖量值調高到 0.9~0.99.
·5、限制網絡模型的權重。大的學習率往往導致大的權重值。對網絡的權重值做最大范數正則化等方法被證明會提升效果。
·擴增訓練集(Data augmentation)
“有時候不是因為算法好贏了,而是因為擁有更多的數據才贏了。”
特別在深度學習中,更多的訓練數據,意味著可以訓練更深的網絡,訓練出更好的模型。
然而很多時候,收集更多的數據并不那么容易,要付出很大的代價。那么,為了得到更多的訓練數據,我們可以在原有的數據上做一些改動產生新的可用數據,以圖片數據為例,將圖片水平翻轉,放大或者選擇一個小角度都可以得到新的圖片數據用于訓練。
雖然這樣的效果沒有全新的數據更加好,但是付出的代價卻是接近于零的。所以,很多情況下,這是一個非常好的數據擴增方法。
·提前停止迭代(Early stopping)
在訓練過程中繪制訓練集誤差函數的同時也繪制交叉驗證集的誤差。從下面的圖可以看出,訓練集誤差隨著迭代次數增加而不斷降低,而驗證集誤差卻是先降低后上升。很明顯,在這個模型中,我們希望驗證集誤差和訓練集誤差都盡量的小,那么最優點就是在驗證集誤差的最低點,訓練應該在該點處停止,也就是選取該點處的權重值作為神經網絡的參數。
但是這種優化方法有很大的缺點。因為提前停止訓練,也就是停止優化訓練集的誤差,通常情況下,在驗證集誤差達到最小值時,訓練集誤差還未處于一個足夠小的值。從而使得該模型雖然沒有出現過擬合現象,卻是出現了欠擬合的情況。當然,這種優化方法還是有著表現優異的使用場景的。
編輯:hfy
-
神經網絡
+關注
關注
42文章
4762瀏覽量
100535
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論