 神經形態芯片作為AI加速器正式神經形態基準鋪平道路
神經形態芯片作為AI加速器正式神經形態基準鋪平道路
英特爾首次展示了將神經形態芯片Loihi與經典計算和主流深度學習加速器進行比較的性能結果摘要。結果表明,盡管Loihi可能無法提供比其他前饋神經網絡方法更多的優勢,但對于其他工作負載(例如遞歸神經網絡)卻可以實現較大的延遲和功率效率增益。英特爾希望第一組定量結果將為開發適用于所有類型神經形態硬件的正式神經形態基準鋪平道路。
英特爾已經將其Loihi芯片與其他計算架構進行了基準測試(圖片來源:英特爾)
“經過數十年的神經形態研究,人們對令人驚嘆的AI功能,效率的巨大突破做出了許多承諾,但是很少有公開的定量結果來表明這是否是真實的,如果是的話,我們到底從哪里得到這些信息?有收獲嗎?”英特爾神經形態研究主管Mike Davies告訴EE Times。
他繼續說:“這是我們研究計劃中的任務,在我們試圖將技術迅速推向商業應用之前,我們正在采取一種有條不紊的,有條不紊的研究方法,在此我們首先要了解許多不同方向中的哪一個。就神經科學的啟發而言,這實際上可以產生最令人信服的結果。”
深度學習比較
真的有可能在神經形態芯片和其他計算硬件的結果之間進行有意義的比較嗎?通常會演示神經形態硬件運行諸如尖峰神經網絡之類的“外來”算法,這與深度學習中發現的算法類型非常不同。
戴維斯說:“關于神經形態研究存在困惑,因為我們可以在像Loihi這樣的神經形態芯片上運行的東西與這些深度學習模型的作用之間存在重疊。”“在多個方面,我們有多種方法可以從深度學習社區中提取學習內容,并將其導入神經形態世界。”
英特爾神經形態研究社區(INRC)是一個由100多家使用英特爾Loihi硬件探索神經形態計算的公司組成的社區,作為這項工作的一部分,它能夠在Loihi上運行深度學習算法。算法可能是現有的以常規方式訓練的深度學習網絡,然后轉換為Loihi可以使用的格式,因此可以對其進行基準測試。這是一種方法,但是實際上可以在Loihi上運行深度學習算法的其他幾種方法(下圖中的區域1)。
一種是使用反向傳播,它是使深度學習取得成功的一種算法技術,因為它可以在訓練過程中對權重進行微調。經常由神經形態芯片(尖峰神經網絡)運行的網絡類型可以配制成數學上可微分的形式,允許應用反向傳播以優化結果。
另一個選擇是嘗試在芯片上執行反向傳播,這相當于當今(離線)訓練神經網絡的方式,但是用于基于采集的數據在現場進行增量訓練。
神經科學啟發的方法與機器學習之間的算法交叉。區域1代表深度學習。區域2是神經形態算法,例如尖峰神經網絡。區域3是目標-基于來自區域1和2的實驗方法的算法,這些算法已經數學上形式化,因此可以應用于其他類型的問題。圖片:英特爾)
基準測試結果結果
英特爾在INRC成員發表的論文(以下)上繪制了性能(潛伏期和功耗)結果圖表,其中包括Loihi與CPU,GPU,Movidius神經計算棒或IBM的Truemorph North Neuromorphic技術之間的量化比較。所有結果均適用于數據樣本一一到達(批大小為1)的應用,類似于實時生物系統。
Loihi系統與其他類型計算的實驗結果。標記的大小代表神經網絡的相對大小(圖片來源:英特爾)
戴維斯說:“這些[數據點]中的每一個都需要大量的工作,這就是為什么迄今為止在神經形態領域還沒有完成太多工作的原因。”“要獲得這些測量值,找到正確的基線比較點并真正完成這項嚴格的工作非常困難。但是我們一直在敦促合作者做到這一點,因為擁有這樣的情節非常令人興奮。”
圖上每個點的大小代表網絡的大小;較大的標記使用更多的Loihi籌碼,最大的代表500多個籌碼)。將這些Loihi系統與單個計算子系統(單個CPU / GPU加上內存)進行了比較。Davies說,要進行蘋果之間的比較并不容易,因為CPU可以添加DRAM來幫助擴展,而Loihi只能添加更多的Loihi芯片。
每個系統中是否可以有更多的計算芯片來改善CPU和GPU的性能?
戴維斯說:“對于這種規模的網絡,這是不可能的。”“按常規標準,支配該圖的小數據點都是很小的網絡……總的來說,對于我們正在研究的問題類型,它們并不能很好地并行化。Loihi實現能夠很好??地擴展的原因是因為存在非常精細的規模并行性,并且神經元之間的通信發生在微微秒的規模上,并且體系結構能夠對此進行處理。”
高度精細的并行通信是Loihi架構的基礎。常規體系結構將粗粒度的工作塊分開,以使工作負載并行化。對于深度學習,這通常是通過分批完成的。Davies說,這種技術在這里無濟于事,因為關鍵指標是處理單個數據樣本的延遲。
到目前為止獲得的結果的關鍵見解是,Loihi對于前饋網絡幾乎沒有提供性能優勢,前饋網絡是一種廣泛用于主流深度學習的神經網絡,因為它們更容易在常規深度學習加速器硬件上進行訓練(見圖)下面)。
戴維斯說:“非常值得注意的是,數據點如此干凈地分離,前饋網絡提供的吸引力最小,在某些情況下,Loihi更糟。”
在Loihi系統上運行遞歸神經網絡可獲得最大的收益,在該系統中,性能降低了1000到10,000倍,解決時間提高了100倍。
Loihi系統與其他類型的計算的實驗結果,突出顯示了哪些工作負載是前饋網絡。標記的大小代表神經網絡的相對大小(圖片來源:英特爾)
未來的基準測試
英特爾宣布打算將其用于此類工作的軟件開源,從而邁出了邁向神經形態基準測試的第一步。將此代碼開源,將允許其他人在其神經形態平臺上運行相同的工作負載,并降低進入神經形態計算和INRC的障礙。
戴維斯說:“我們很高興能夠開始比較不同組的神經形態芯片得到的結果。”“但是對我們而言,最初的工作重點是針對常規體系結構進行基準測試,以了解我們應將什么放入神經形態基準套件中,然后再用于推動神經形態領域的進步。”
未來神經形態基準測試的很大一部分是了解應包括哪些類型的算法。對于深度學習,候選人更為明顯– ResNet-50的使用如此廣泛,以至于它已成為事實上的基準。在神經形態空間中沒有等效項,因為它更加分散,并且硬件更具算法特定性。
“我認為重要的是,我們要從這類新興的工作負載中建立實際的方法,正式的基準測試,在這些工作負載中,我們可以看到神經形態硬件的好處,并在那里進行標準化。但是我認為這是下一步。”戴維斯說。“我們當然希望在這個方向上領導這一領域。為了使之成為可能,還需要進行進一步的融合,尤其是在軟件方面。”
通過這些結果,英特爾希望證明Loihi可以在一系列復雜的,困難的,以大腦為靈感的工作負載上提供巨大的性能提升,即使它尚不知道這些工作負載的外觀如何。
戴維斯說:“在英特爾,我們的目標比其他任何事情都重要,要確保這是各種各樣的工作負載。”“我們不打算制造用于約束滿足解決方案的點加速器,也不是機器人手臂操縱器。我們希望這是一種類似于CPU或GPU的新型計算機體系結構,但是如果優化得當,它將固有地很好地運行各種大腦啟發的智能工作負載。”
編輯:hfy
-
英特爾
+關注
關注
60文章
9900瀏覽量
171551 -
神經網絡
+關注
關注
42文章
4765瀏覽量
100568 -
深度學習
+關注
關注
73文章
5493瀏覽量
121000 -
AI加速器
+關注
關注
1文章
68瀏覽量
8629
發布評論請先 登錄
相關推薦
TDK成功研發出用于神經形態設備的自旋憶阻器
神經元是什么?神經元在神經系統中的作用
什么是神經網絡加速器?它有哪些特點?
神經元的結構及功能是什么
神經元的基本作用是什么信息
神經形態計算器件和陣列測試解決方案
西門子推出Catapult AI NN:重塑神經網絡加速器設計的未來
西門子推出Catapult AI NN軟件,賦能神經網絡加速器設計
我國科研人員聯合研發出一款新型類腦神經形態系統級芯片Speck
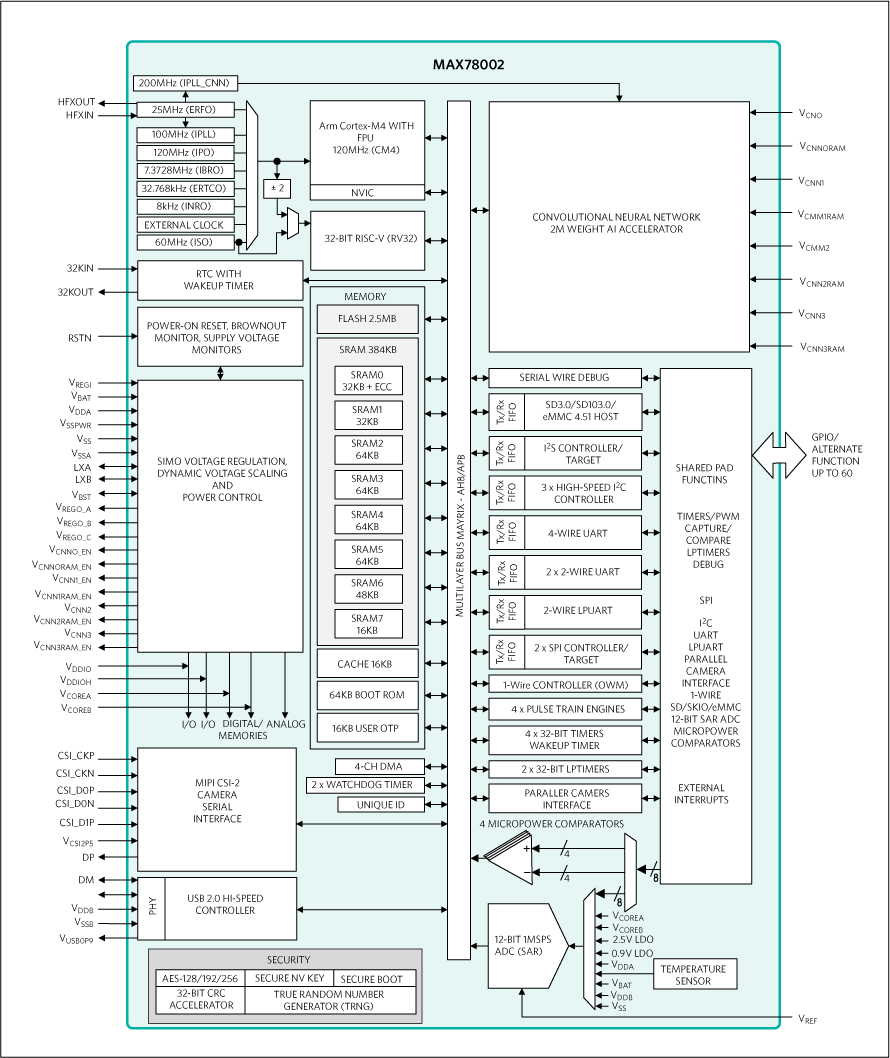
芯品#MAX78002 新型AI MCU,能夠使神經網絡以超低功耗運行





 工商網監
工商網監
評論