") 基于直方圖算法進(jìn)行FPGA架構(gòu)設(shè)計(jì)
基于直方圖算法進(jìn)行FPGA架構(gòu)設(shè)計(jì)
引言
直方圖統(tǒng)計(jì)在圖像增強(qiáng)和目標(biāo)檢測(cè)領(lǐng)域有重要應(yīng)用,比如直方圖均衡,梯度直方圖。直方圖的不同種類(lèi)和統(tǒng)計(jì)方法請(qǐng)見(jiàn)之前的文章。本章就是用FPGA來(lái)進(jìn)行直方圖的計(jì)算,并且利用FPGA的特性對(duì)計(jì)算過(guò)程進(jìn)行加速。安排如下:
首先基于直方圖算法進(jìn)行FPGA架構(gòu)設(shè)計(jì),這里主要考慮了如何加速以及FPGA資源的利用兩個(gè)因素;最后基于system Verilog搭建一個(gè)驗(yàn)證系統(tǒng)。
FPGA設(shè)計(jì)架構(gòu)
不論是圖像灰度直方圖還是梯度直方圖,本質(zhì)上是對(duì)數(shù)據(jù)的分布進(jìn)行計(jì)數(shù)。從FPGA角度來(lái)看,只關(guān)心以下幾點(diǎn):
1) 根據(jù)數(shù)據(jù)大小確定其分布區(qū)間,統(tǒng)計(jì)分布在不同區(qū)間的數(shù)據(jù)個(gè)數(shù),區(qū)間的大小可以調(diào)節(jié),比如灰度直方圖區(qū)間為1,梯度直方圖通常大于1;
2) 如何利用FPGA對(duì)直方圖統(tǒng)計(jì)進(jìn)行加速,以及如何考慮到芯片有限資源;
首先來(lái)考慮加速方式,直方圖統(tǒng)計(jì)過(guò)程用偽代碼表示為:
For(int i=0;i Index = get_index(data[i]);
Hist[index]++;
}
Get_index函數(shù)是為了確定數(shù)據(jù)屬于哪個(gè)區(qū)間,如果區(qū)間大小為1,那么index就是數(shù)據(jù)自身。如果區(qū)間是平均分布,那么就需要進(jìn)行數(shù)據(jù)的大小比較。如果區(qū)間大小是2的冪次,那么index只需要數(shù)據(jù)進(jìn)行移位得到。
FPGA在加速計(jì)算中最主要就是利用并行化和流水線,并行化就是將一個(gè)任務(wù)拆解成多個(gè)子任務(wù),多個(gè)子任務(wù)并行完成。而流水線是在處理一個(gè)子任務(wù)的時(shí)候,下一個(gè)來(lái)的子任務(wù)也可以進(jìn)行處理,處理模塊不會(huì)等待。流水線本質(zhì)上是對(duì)子任務(wù)也進(jìn)行“分割”,分割的每一塊可以在處理模塊中同時(shí)進(jìn)行。
統(tǒng)計(jì)N個(gè)數(shù)據(jù),可以將N分成M份,在FPGA上同時(shí)進(jìn)行M個(gè)統(tǒng)計(jì),用偽代碼表示為:
For(int k=0;k //并行化
For(int i=0;i Index = get_index(data[k][i]);
Hist[k][index]++;
}
}
如果區(qū)間不是2的冪次,就需要比較器,這樣并行M次,就需要M個(gè)同等比較器,這對(duì)資源消耗很大。因此目前設(shè)計(jì)僅僅支持2的冪次的區(qū)間。整個(gè)設(shè)計(jì)架構(gòu)如圖1.2。
圖2.1 流水線處理
圖2.2 直方圖統(tǒng)計(jì)架構(gòu)
主要分為以下幾個(gè)模塊:
1)statis:這個(gè)是核心計(jì)算模塊,統(tǒng)計(jì)數(shù)據(jù)分布。ram中存放直方圖統(tǒng)計(jì)數(shù)據(jù),地址對(duì)應(yīng)著數(shù)據(jù)分布區(qū)間。這里有一個(gè)問(wèn)題需要考慮,在對(duì)ram中直方圖統(tǒng)計(jì)數(shù)據(jù)計(jì)數(shù)時(shí),需要讀出然后計(jì)數(shù)。如果ram讀端口沒(méi)有寄存器,那么讀出來(lái)直接加1,再寫(xiě)入。但是這樣并不好,因?yàn)閞am不經(jīng)過(guò)寄存器時(shí)序不好。所以增加了一級(jí)寄存器,這樣就造成了寫(xiě)入的延時(shí),那么有可能下一次數(shù)據(jù)來(lái)臨也會(huì)讀取同樣地址的數(shù)據(jù),此時(shí)讀取到的直方圖數(shù)據(jù)就是還沒(méi)有寫(xiě)入的。為了解決這個(gè)問(wèn)題,判斷進(jìn)入的前后兩個(gè)數(shù)據(jù)是否相同,如果相同就不寫(xiě)入而繼續(xù)計(jì)數(shù),如果不同就寫(xiě)入。并行多個(gè)statis模塊的代碼為:
genvar i;
generate
for(i=0;i
statis #(
.PIX_BW(PIX_BW),
.HIST_BW(HIST_BW),
.ADDR_BW(HIST_LEN_BW),
.BIN_W(BIN_W)
)u_statis(
.clk(clk),
.rst(rst),
.clr(clr),
.enable(1'b1),
.pix_valid(pix_valid),
.pix(img_i[i*PIX_BW +: PIX_BW]),
.hist_rd(branch_hist_rd),
.hist_raddr(branch_hist_raddr),
.hist(branch_hist[i*HIST_BW +: HIST_BW])
);
end
endgenerate
2)serders:這個(gè)是并轉(zhuǎn)串。M個(gè)statis模塊會(huì)產(chǎn)生M組hist結(jié)果,這些結(jié)果還要進(jìn)行求和,那么就要用到加法樹(shù),如果M較大,會(huì)造成加法樹(shù)很大,多以這里加了serders可以調(diào)節(jié)加法樹(shù)資源。
3) addTree:加法樹(shù)。
module addTree #(
parameter DATA_BW = 32,//bit width of data
parameter TREE_DEPTH = 3,//depth of the add tree
parameter ADD_N = 4//add number
)
(
input clk,
input rst,
input [ADD_N*DATA_BW-1:0] adnd_x,
input [ADD_N*DATA_BW-1:0] adnd_y,
input adnd_valid,
output reg[DATA_BW-1:0] finl_sum,
output reg finl_sum_valid
);
reg [TREE_DEPTH-1:0]midl_valid;
genvar dept_i, leaf_i;
generate
for(dept_i=TREE_DEPTH-1;dept_i>=0;dept_i=dept_i-1)begin: ADD_DPET
localparam LEAF_N = 2**dept_i;
wire[DATA_BW-1:0] midl_sum[LEAF_N-1:0];
for(leaf_i=0;leaf_i
reg [DATA_BW-1:0] midl_add_x;
reg [DATA_BW-1:0] midl_add_y;
if(dept_i==TREE_DEPTH-1)begin
always @(posedge clk)begin
midl_add_x midl_add_y end
end
else begin
always @(posedge clk)begin
midl_add_x midl_add_y end
end
adder #(
.DATA_BW(DATA_BW)
)
u_adder(
.adnd_x(midl_add_x),
.adnd_y(midl_add_y),
.sum(midl_sum[leaf_i])
);
end
if(dept_i==TREE_DEPTH-1)
always @(posedge clk)begin
midl_valid[dept_i] end
else
always @(posedge clk)begin
midl_valid[dept_i] end
end
endgenerate
always @(posedge clk)begin
finl_sum end
always @(posedge clk)begin
if(rst)
finl_sum_valid else
finl_sum_valid end
endmodule
4) accum:累加器。如果加法樹(shù)沒(méi)有完成M個(gè)hist數(shù)據(jù)的求和,那么就需要通過(guò)累加器來(lái)完成。
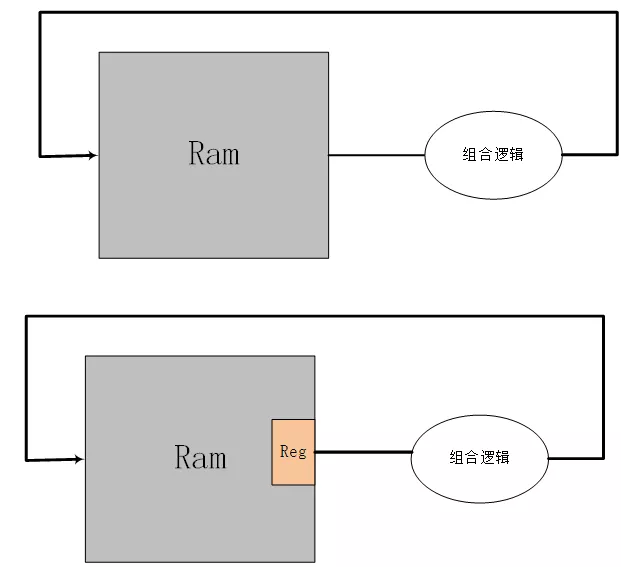
圖2.3 對(duì)ram的處理
驗(yàn)證結(jié)構(gòu)
1) img_trans:這個(gè)是隨機(jī)化圖像數(shù)據(jù)定義,主要通過(guò)SV中constraint來(lái)對(duì)圖像大小做一些約束;
class img_trans;
rand int img_w;
rand int img_h;
rand int img_blank;
rand logic[`PIX_BW-1:0] img[`MAX_IMG_W*`MAX_IMG_H];
constraint img_cfg_cnst{
img_w img_w > 0;
img_w % `PARALL == 0;
img_h img_h > 0;
img_blank img_blank >= 0;
}
extern function void write(input string f_name);
endclass
2) driver:產(chǎn)生image并且發(fā)送給DUT,同時(shí)通過(guò)mailbox發(fā)送給ref_model用于對(duì)比;
class img_obj;
logic [`PIX_BW-1:0] img_que[$];
endclass
class driver;
int img_w;
int img_h;
int img_blank;
logic [`PARALL*`PIX_BW-1:0] img;
logic [`PIX_BW-1:0] img_ele;
img_obj imgObj;
img_trans imgTrans;
extern task drive(mailbox img_mbx, virtual img_inf.test imgInf);
endclass
3) ref_model:自己統(tǒng)計(jì)直方圖和DUT的結(jié)果進(jìn)行比對(duì);
class ref_modl;
logic [`PIX_BW-1:0] img;
int addr;
img_obj imgObj;
int hist[`HIST_LEN];
extern task calc(input logic clk, mailbox img_mbx);
extern task comp(virtual img_inf.test imgInf);
extern task run(input logic clk, mailbox img_mbx, virtual img_inf.test imgInf);
extern function void clear();
endclass
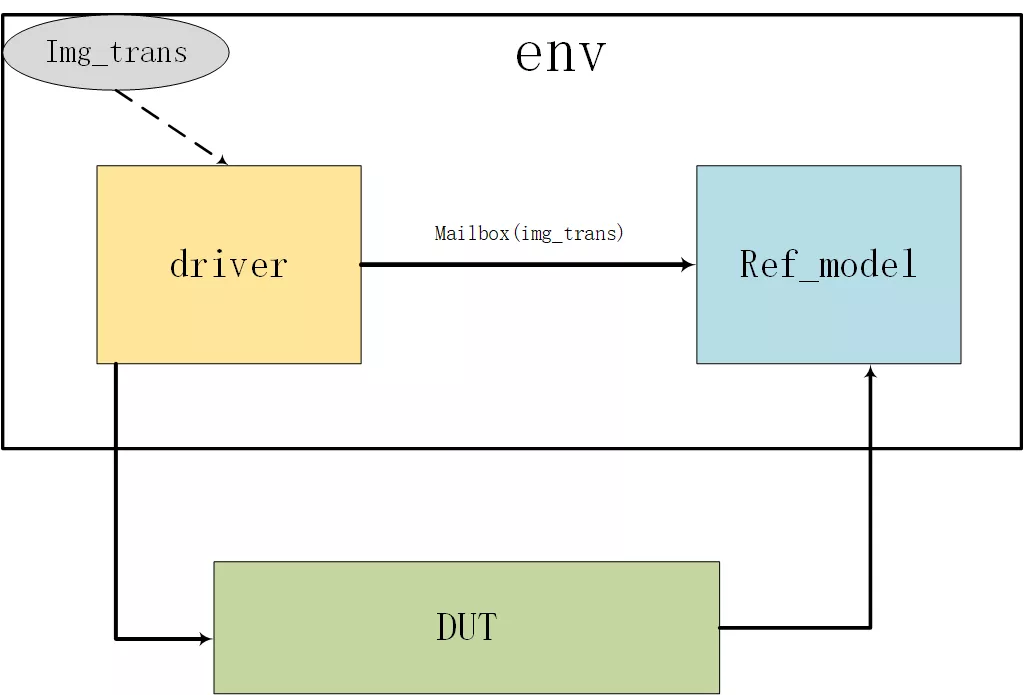
圖3.1 驗(yàn)證架構(gòu)圖
最后添加一下modelsim仿真波形文件和結(jié)果,純粹為了增加篇幅。
圖3.2 modelsim仿真波形和結(jié)果
編輯:hfy
-
FPGA
+關(guān)注
關(guān)注
1626文章
21678瀏覽量
602037 -
直方圖
+關(guān)注
關(guān)注
0文章
19瀏覽量
7878
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
深入理解 Llama 3 的架構(gòu)設(shè)計(jì)
邊緣計(jì)算架構(gòu)設(shè)計(jì)最佳實(shí)踐
FPGA設(shè)計(jì)中,對(duì)SPI進(jìn)行參數(shù)化結(jié)構(gòu)設(shè)計(jì)
FPGA設(shè)計(jì)中,對(duì)SPI進(jìn)行參數(shù)化結(jié)構(gòu)設(shè)計(jì)
交換芯片架構(gòu)設(shè)計(jì)
交換芯片架構(gòu)設(shè)計(jì)
fpga是什么架構(gòu)
華為企業(yè)架構(gòu)設(shè)計(jì)方法及實(shí)例

怎么用FPGA做算法 如何在FPGA上實(shí)現(xiàn)最大公約數(shù)算法
一文帶你了解FPGA直方圖操作
FPGA圖像處理-CLAHE算法介紹(一)
為什么不能直接對(duì)RGB圖做直方圖均衡化

揭秘GPU: 高端GPU架構(gòu)設(shè)計(jì)的挑戰(zhàn)

fpga布局布線算法加速
FPGA直方圖處理方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論