") 深度剖析MySQL/InnoDB的并發(fā)控制和加鎖技術(shù)
深度剖析MySQL/InnoDB的并發(fā)控制和加鎖技術(shù)
本文主要是針對MySQL/InnoDB的并發(fā)控制和加鎖技術(shù)做一個(gè)比較深入的剖析,并且對其中涉及到的重要的概念,如多版本并發(fā)控制(MVCC),臟讀(dirty read),幻讀(phantom read),四種隔離級別(isolation level)等作詳細(xì)的闡述,并且基于一個(gè)簡單的例子,對MySQL的加鎖進(jìn)行了一個(gè)詳細(xì)的分析。本文的總結(jié)參考了何登成前輩的博客,并且在前輩總結(jié)的基礎(chǔ)上,進(jìn)行了一些基礎(chǔ)性的說明,希望對剛?cè)腴T的同學(xué)產(chǎn)生些許幫助,如有錯(cuò)誤,請不吝賜教。按照我的寫作習(xí)慣,還是通過幾個(gè)關(guān)鍵問題來組織行文邏輯,如下:
什么是MVCC(多版本并發(fā)控制)?如何理解快照讀(snapshot read)和當(dāng)前讀(current read)?
什么是隔離級別?臟讀?幻讀?InnoDB的四種隔離級別的含義是什么?
什么是死鎖?
InnoDB是如何實(shí)現(xiàn)MVCC的?
一個(gè)簡單的sql在不同場景下的加鎖分析
一個(gè)復(fù)雜的sql的加鎖分析
接下來,我將按照這幾個(gè)關(guān)鍵問題的順序,對以上問題作一一解答,并且在解答的過程中,爭取將加鎖技術(shù)的細(xì)節(jié),闡述的更加清楚。
1.1 MVCC:Multi-Version Concurrent Control 多版本并發(fā)控制
MVCC是為了實(shí)現(xiàn)數(shù)據(jù)庫的并發(fā)控制而設(shè)計(jì)的一種協(xié)議。從我們的直觀理解上來看,要實(shí)現(xiàn)數(shù)據(jù)庫的并發(fā)訪問控制,最簡單的做法就是加鎖訪問,即讀的時(shí)候不能寫(允許多個(gè)西線程同時(shí)讀,即共享鎖,S鎖),寫的時(shí)候不能讀(一次最多只能有一個(gè)線程對同一份數(shù)據(jù)進(jìn)行寫操作,即排它鎖,X鎖)。這樣的加鎖訪問,其實(shí)并不算是真正的并發(fā),或者說它只能實(shí)現(xiàn)并發(fā)的讀,因?yàn)樗罱K實(shí)現(xiàn)的是讀寫串行化,這樣就大大降低了數(shù)據(jù)庫的讀寫性能。加鎖訪問其實(shí)就是和MVCC相對的LBCC,即基于鎖的并發(fā)控制(Lock-Based Concurrent Control),是四種隔離級別中級別最高的Serialize隔離級別。為了提出比LBCC更優(yōu)越的并發(fā)性能方法,MVCC便應(yīng)運(yùn)而生。
幾乎所有的RDBMS都支持MVCC。它的最大好處便是,讀不加鎖,讀寫不沖突。在MVCC中,讀操作可以分成兩類,快照讀(Snapshot read)和當(dāng)前讀(current read)。快照讀,讀取的是記錄的可見版本(可能是歷史版本,即最新的數(shù)據(jù)可能正在被當(dāng)前執(zhí)行的事務(wù)并發(fā)修改),不會(huì)對返回的記錄加鎖;而當(dāng)前讀,讀取的是記錄的最新版本,并且會(huì)對返回的記錄加鎖,保證其他事務(wù)不會(huì)并發(fā)修改這條記錄。在MySQL InnoDB中,簡單的select操作,如select * from table where ? 都屬于快照讀;屬于當(dāng)前讀的包含以下操作:
select * from table where ? lock in share mode; (加S鎖)
select * from table where ? for update; (加X鎖,下同)
insert, update, delete操作
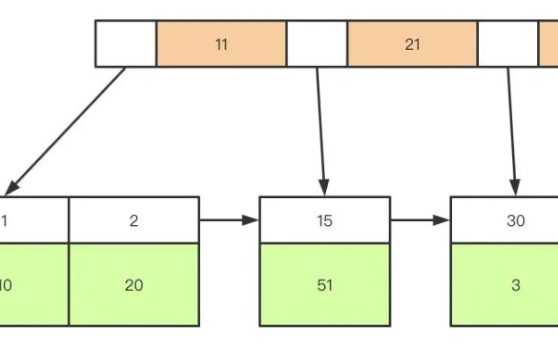
針對一條當(dāng)前讀的SQL語句,InnoDB與MySQL Server的交互,是一條一條進(jìn)行的,因此,加鎖也是一條一條進(jìn)行的。先對一條滿足條件的記錄加鎖,返回給MySQL Server,做一些DML操作;然后再讀取下一條加鎖,直至讀取完畢。需要注意的是,以上需要加X鎖的都是當(dāng)前讀,而普通的select(除了for update)都是快照讀,每次insert、update、delete之前都是會(huì)進(jìn)行一次當(dāng)前讀的,這個(gè)時(shí)候會(huì)上鎖,防止其他事務(wù)對某些行數(shù)據(jù)的修改,從而造成數(shù)據(jù)的不一致性。我們廣義上說的幻讀現(xiàn)象是通過MVCC解決的,意思是通過MVCC的快照讀可以使得事務(wù)返回相同的數(shù)據(jù)集。如下圖所示:
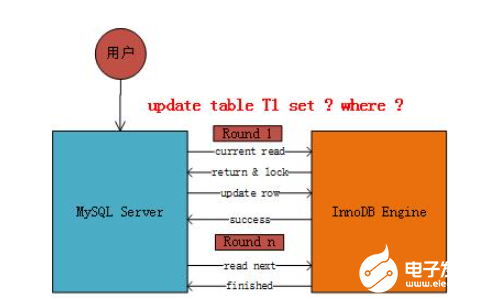
注意,我們一般說在MyISAM中使用表鎖,因?yàn)镸yISAM在修改數(shù)據(jù)記錄的時(shí)候會(huì)將整個(gè)表鎖起來;而InnoDB使用的是行鎖,即我們以上所談的MVCC的加鎖問題。但是,并不是InnoDB引擎不會(huì)使用表鎖,比如在alter table的時(shí)候,Innodb就會(huì)將該表用表鎖鎖起來。
1.2 隔離級別
在SQL的標(biāo)準(zhǔn)中,定義了四種隔離級別。每一種級別都規(guī)定了,在一個(gè)事務(wù)中所做的修改,哪些在事務(wù)內(nèi)和事務(wù)間是可見的,哪些是不可見的。低級別的隔離可以執(zhí)行更高級別的并發(fā),性能好,但是會(huì)出現(xiàn)臟讀和幻讀的現(xiàn)象。首先,我們從兩個(gè)基礎(chǔ)的概念說起:
臟讀(dirty read):兩個(gè)事務(wù),一個(gè)事務(wù)讀取到了另一個(gè)事務(wù)未提交的數(shù)據(jù),這便是臟讀。
幻讀(phantom read):兩個(gè)事務(wù),事務(wù)A與事務(wù)B,事務(wù)A在自己執(zhí)行的過程中,執(zhí)行了兩次相同查詢,第一次查詢事務(wù)B未提交,第二次查詢事務(wù)B已提交,從而造成兩次查詢結(jié)果不一樣,這個(gè)其實(shí)被稱為不可重復(fù)讀;如果事務(wù)B是一個(gè)會(huì)影響查詢結(jié)果的insert操作,則好像新多出來的行像幻覺一樣,因此被稱為幻讀。其他事務(wù)的提交會(huì)影響在同一個(gè)事務(wù)中的重復(fù)查詢結(jié)果。
下面簡單描述一下SQL中定義的四種標(biāo)準(zhǔn)隔離級別:
READ UNCOMMITTED (未提交讀):隔離級別:0. 可以讀取未提交的記錄。會(huì)出現(xiàn)臟讀。
READ COMMITTED (提交讀):隔離級別:1. 事務(wù)中只能看到已提交的修改。不可重復(fù)讀,會(huì)出現(xiàn)幻讀。(在InnoDB中,會(huì)加行所,但是不會(huì)加間隙鎖)該隔離級別是大多數(shù)數(shù)據(jù)庫系統(tǒng)的默認(rèn)隔離級別,但是MySQL的則是RR。
REPEATABLE READ (可重復(fù)讀):隔離級別:2.在InnoDB中是這樣的:RR隔離級別保證對讀取到的記錄加鎖 (記錄鎖),同時(shí)保證對讀取的范圍加鎖,新的滿足查詢條件的記錄不能夠插入 (間隙鎖),因此不存在幻讀現(xiàn)象。但是標(biāo)準(zhǔn)的RR只能保證在同一事務(wù)中多次讀取同樣記錄的結(jié)果是一致的,而無法解決幻讀問題。InnoDB的幻讀解決是依靠MVCC的實(shí)現(xiàn)機(jī)制做到的。
SERIALIZABLE (可串行化):隔離級別:3. 該隔離級別會(huì)在讀取的每一行數(shù)據(jù)上都加上鎖,退化為基于鎖的并發(fā)控制,即LBCC。
需要注意的是,MVCC只在RC和RR兩個(gè)隔離級別下工作,其他兩個(gè)隔離級別都和MVCC不兼容。
1.3 死鎖
死鎖是指兩個(gè)或者多個(gè)事務(wù)在同一資源上相互作用,并請求鎖定對方占用的資源,從而導(dǎo)致惡性循環(huán)的現(xiàn)象。當(dāng)多個(gè)事務(wù)試圖以不同的順序鎖定資源時(shí),就可能產(chǎn)生死鎖。多個(gè)事務(wù)同時(shí)鎖定同一個(gè)資源時(shí),也會(huì)產(chǎn)生死鎖。且看下面的兩個(gè)產(chǎn)生死鎖的例子:
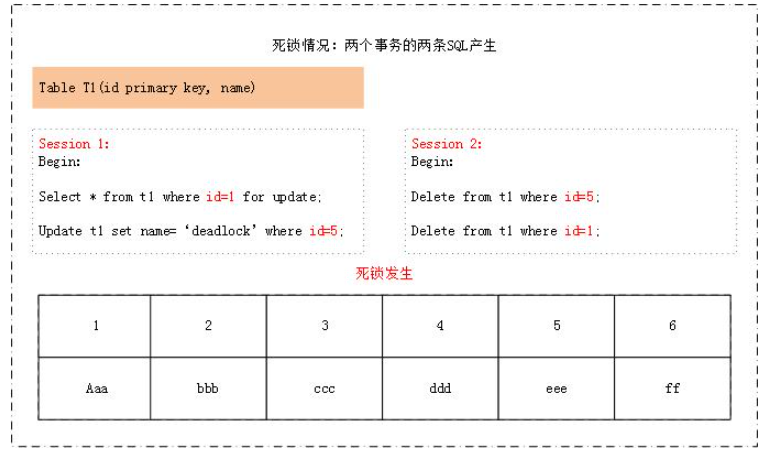

第一個(gè)死鎖很好理解,而第二個(gè)死鎖,由于在主索引(聚簇索引表)上仍舊是對兩條記錄進(jìn)行了不同順序的加鎖,因此仍舊會(huì)造成死鎖。死鎖的發(fā)生與否,并不在于事務(wù)中有多少條SQL語句,死鎖的關(guān)鍵在于:兩個(gè)(或以上)的Session加鎖的順序不一致。因此,我們通過分析加鎖細(xì)節(jié),可以判斷所寫的sql是否會(huì)發(fā)生死鎖,同時(shí)發(fā)生死鎖的時(shí)候,我們應(yīng)該如何處理。
1.4 InnoDB的MVCC實(shí)現(xiàn)機(jī)制
MVCC可以認(rèn)為是行級鎖的一個(gè)變種,它可以在很多情況下避免加鎖操作,因此開銷更低。MVCC的實(shí)現(xiàn)大都都實(shí)現(xiàn)了非阻塞的讀操作,寫操作也只鎖定必要的行。InnoDB的MVCC實(shí)現(xiàn),是通過保存數(shù)據(jù)在某個(gè)時(shí)間點(diǎn)的快照來實(shí)現(xiàn)的。一個(gè)事務(wù),不管其執(zhí)行多長時(shí)間,其內(nèi)部看到的數(shù)據(jù)是一致的。也就是事務(wù)在執(zhí)行的過程中不會(huì)相互影響。下面我們簡述一下MVCC在InnoDB中的實(shí)現(xiàn)。
InnoDB的MVCC,通過在每行記錄后面保存兩個(gè)隱藏的列來實(shí)現(xiàn):一個(gè)保存了行的創(chuàng)建時(shí)間,一個(gè)保存行的過期時(shí)間(刪除時(shí)間),當(dāng)然,這里的時(shí)間并不是時(shí)間戳,而是系統(tǒng)版本號,每開始一個(gè)新的事務(wù),系統(tǒng)版本號就會(huì)遞增。在RR隔離級別下,MVCC的操作如下:
select操作。a.InnoDB只查找版本早于(包含等于)當(dāng)前事務(wù)版本的數(shù)據(jù)行。可以確保事務(wù)讀取的行,要么是事務(wù)開始前就已存在,或者事務(wù)自身插入或修改的記錄。b.行的刪除版本要么未定義,要么大于當(dāng)前事務(wù)版本號。可以確保事務(wù)讀取的行,在事務(wù)開始之前未刪除。
insert操作。將新插入的行保存當(dāng)前版本號為行版本號。
delete操作。將刪除的行保存當(dāng)前版本號為刪除標(biāo)識。
update操作。變?yōu)閕nsert和delete操作的組合,insert的行保存當(dāng)前版本號為行版本號,delete則保存當(dāng)前版本號到原來的行作為刪除標(biāo)識。
由于舊數(shù)據(jù)并不真正的刪除,所以必須對這些數(shù)據(jù)進(jìn)行清理,innodb會(huì)開啟一個(gè)后臺(tái)線程執(zhí)行清理工作,具體的規(guī)則是將刪除版本號小于當(dāng)前系統(tǒng)版本的行刪除,這個(gè)過程叫做purge。
1.5 一個(gè)簡單SQL的加鎖分析
在MySQL的InnoDB中,都是基于聚簇索引表的。而且普通的select操作都是基于快照讀,是不需要加鎖的。那么我們在分析其他的sql語句的時(shí)候,如何分析加鎖細(xì)節(jié)?下面我們以一個(gè)簡單的delete操作的SQL為例,進(jìn)行一個(gè)詳細(xì)的闡述。且看下面的SQL:
delete from t1 where id=10;
如果對這條SQL進(jìn)行加鎖分析,那么MySQL是如何加鎖的呢?一般情況下,我們直觀的感受是:會(huì)在id=10的記錄上加鎖。但是,這樣輕率的下結(jié)論是片面的,要想確定MySQL的加鎖情況,我們還需要知道更多的條件。還需要知道哪些條件呢?比如:
id列是不是主鍵?
系統(tǒng)的隔離級別是什么?
id非主鍵的話,其上有建立索引嗎?
建立的索引是唯一索引嗎?
該SQL的執(zhí)行計(jì)劃是什么?索引掃描?全表掃描?
接下來,我將這些問題的答案進(jìn)行組合,然后按照從易到難的順序,逐個(gè)分析每種組合下,對應(yīng)的SQL會(huì)加哪些鎖。
組合1:id列是主鍵,RC隔離級別
組合2:id列是二級唯一索引,RC隔離級別
組合3:id列是二級非唯一索引,RC隔離級別
組合4:id列上沒有索引,RC隔離級別
組合5:id列是主鍵,RR隔離級別
組合6:id列是二級唯一索引,RR隔離級別
組合7:id列是二級非唯一索引,RR隔離級別
組合8:id列上沒有索引,RR隔離級別
組合9:Serializable隔離級別
組合1:id列是主鍵,RC隔離級別
當(dāng)id是主鍵的時(shí)候,我們只需要在該id=10的記錄上加上x鎖即可。如下圖所示:
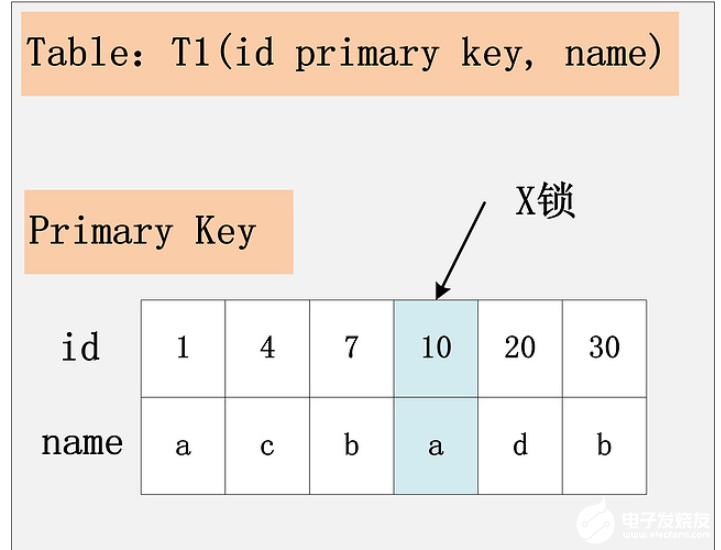
組合2:id列是二級唯一索引,RC隔離級別
在這里我先解釋一下聚簇索引和普通索引的區(qū)別。在InnoDB中,主鍵可以被理解為聚簇索引,聚簇索引中的葉子結(jié)點(diǎn)就是相應(yīng)的數(shù)據(jù)行,具有聚簇索引的表也被稱為聚簇索引表,數(shù)據(jù)在存儲(chǔ)的時(shí)候,是按照主鍵進(jìn)行排序存儲(chǔ)的。我們都知道,數(shù)據(jù)庫在select的時(shí)候,會(huì)選擇索引列進(jìn)行查找,索引列都是按照B+樹(多叉搜索樹)數(shù)據(jù)結(jié)構(gòu)進(jìn)行存儲(chǔ),找到主鍵之后,再回到聚簇索引表中進(jìn)行查詢,這叫回表查詢。那我們自然會(huì)問,當(dāng)使用索引進(jìn)行查詢的時(shí)候,與索引相對應(yīng)的記錄會(huì)被上鎖嗎?會(huì)的。如果id是唯一索引,那么只給該唯一索引所對應(yīng)的索引記錄上x鎖;如果id是非唯一索引,那么所對應(yīng)的所有的索引記錄上都會(huì)上x鎖。如下圖所示:
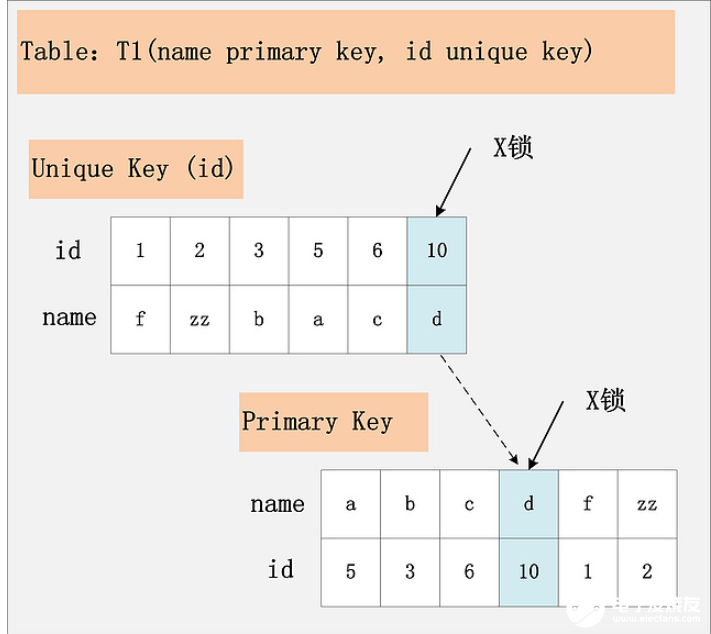
組合3:id列是二級非唯一索引,RC隔離級別
解釋同上,如下圖:
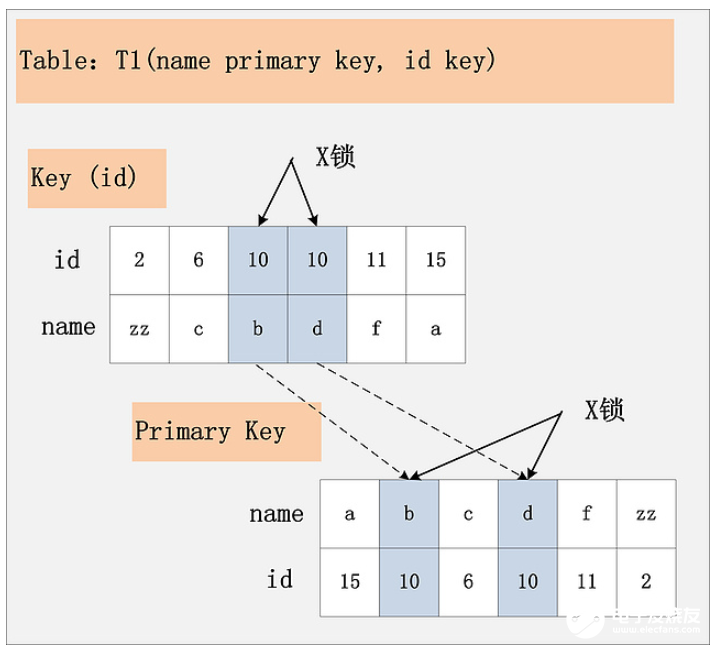
組合4:id列上沒有索引,RC隔離級別
由于id列上沒有索引,因此只能走聚簇索引,進(jìn)行全部掃描。有人說會(huì)在表上加X鎖;有人說會(huì)在聚簇索引上,選擇出來的id = 10 的記錄加上X鎖。真實(shí)情況如下圖:
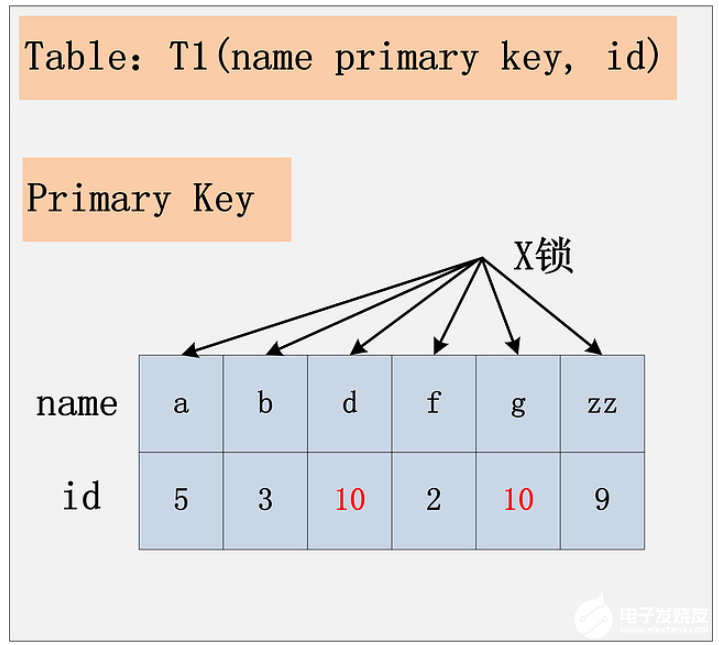
若id列上沒有索引,SQL會(huì)走聚簇索引的全掃描進(jìn)行過濾,由于過濾是由MySQL Server層面進(jìn)行的。因此每條記錄,無論是否滿足條件,都會(huì)被加上X鎖。但是,為了效率考量,MySQL做了優(yōu)化,對于不滿足條件的記錄,會(huì)在判斷后放鎖,最終持有的,是滿足條件的記錄上的鎖,但是不滿足條件的記錄上的加鎖/放鎖動(dòng)作不會(huì)省略。同時(shí),優(yōu)化也違背了2PL的約束(同時(shí)加鎖同時(shí)放鎖)。
組合5,6同以上(因?yàn)橹挥幸粭l結(jié)果記錄,只能在上面加鎖)
組合7:id列是二級非唯一索引,RR隔離級別
在RR隔離級別下,為了防止幻讀的發(fā)生,會(huì)使用Gap鎖。這里,你可以把Gap鎖理解為,不允許在數(shù)據(jù)記錄前面插入數(shù)據(jù)。首先,通過id索引定位到第一條滿足查詢條件的記錄,加記錄上的X鎖,加GAP上的GAP鎖,然后加主鍵聚簇索引上的記錄X鎖,然后返回;然后讀取下一條,重復(fù)進(jìn)行。直至進(jìn)行到第一條不滿足條件的記錄[11,f],此時(shí),不需要加記錄X鎖,但是仍舊需要加GAP鎖,最后返回結(jié)束。如下圖所示:

組合8:id列無索引,RR隔離級別
在這種情況下,聚簇索引上的所有記錄,都被加上了X鎖。其次,聚簇索引每條記錄間的間隙(GAP),也同時(shí)被加上了GAP鎖。如下圖:
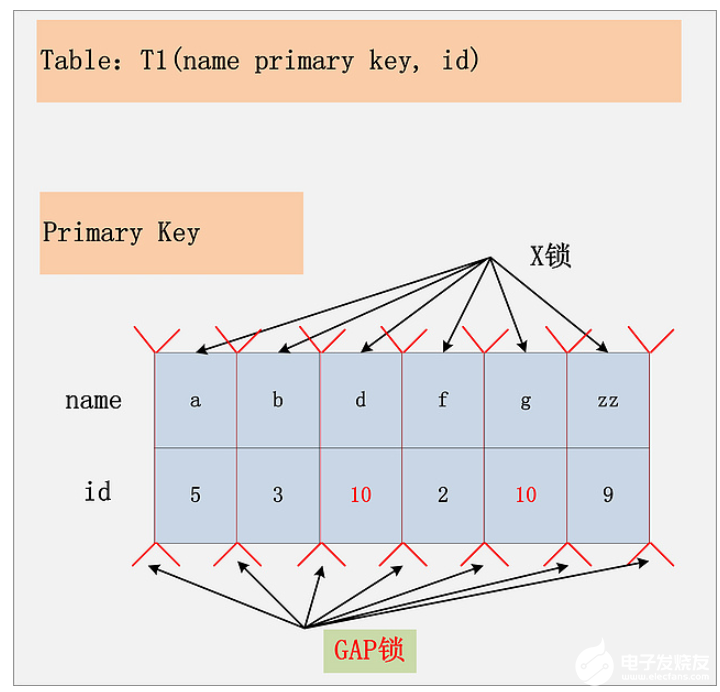
但是,MySQL是做了相關(guān)的優(yōu)化的,就是所謂的semi-consistent read。semi-consistent read開啟的情況下,對于不滿足查詢條件的記錄,MySQL會(huì)提前放鎖,同時(shí)也不會(huì)添加Gap鎖。
組合9:Serializable隔離級別
和RR隔離級別一樣。
1.6 一個(gè)復(fù)雜的SQL的加鎖分析
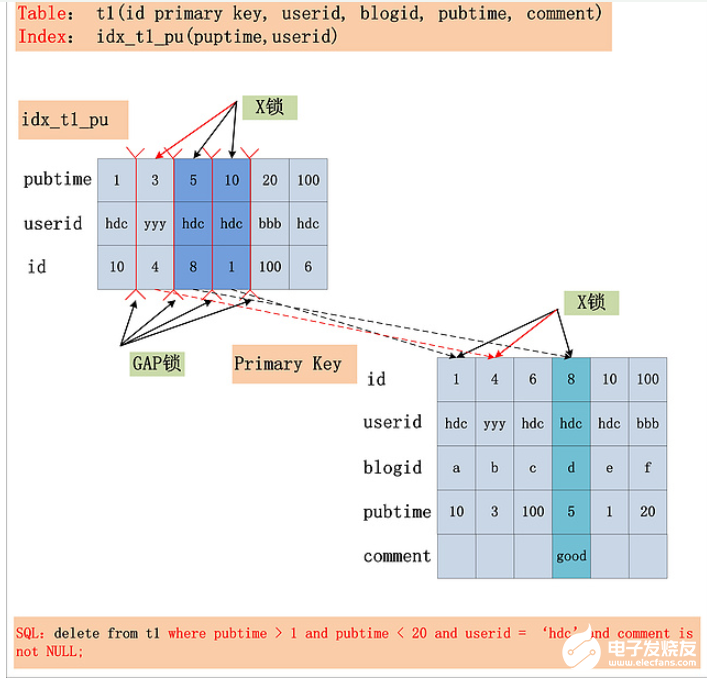
這里我們只是列出一個(gè)結(jié)論,因?yàn)橐婕暗組ySQL的where查詢條件的分析,因此這里先不做詳細(xì)介紹,我會(huì)在之后的博客中詳細(xì)說明。如下圖:

結(jié)論:在RR隔離級別下,針對一個(gè)復(fù)雜的SQL,首先需要提取其where條件。Index Key確定的范圍,需要加上GAP鎖;Index Filter過濾條件,視MySQL版本是否支持ICP,若支持ICP,則不滿足Index Filter的記錄,不加X鎖,否則需要X鎖;Table Filter過濾條件,無論是否滿足,都需要加X鎖。加鎖的結(jié)果如下所示:
總結(jié)
本文只是對MVCC的一些基礎(chǔ)性的知識點(diǎn)進(jìn)行了詳細(xì)的總結(jié),參考了網(wǎng)上和書上比較多的資料和實(shí)例。
編輯:hfy
-
死鎖
+關(guān)注
關(guān)注
0文章
25瀏覽量
8066 -
MySQL
+關(guān)注
關(guān)注
1文章
802瀏覽量
26444 -
MVCC
+關(guān)注
關(guān)注
0文章
13瀏覽量
1461
發(fā)布評論請先 登錄
相關(guān)推薦
詳解Mysql數(shù)據(jù)庫InnoDB存儲(chǔ)引擎事務(wù)
最有用的mysql問答
MySQL中的高級內(nèi)容詳解
關(guān)于InnoDB的內(nèi)存結(jié)構(gòu)及原理詳解
innodb究竟是如何存數(shù)據(jù)的
MySQL5.6 InnoDB支持全文檢索
剖析MySQL InnoDB存儲(chǔ)原理(上)
剖析MySQL InnoDB存儲(chǔ)原理(下)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論