 防止網絡擁塞現象的TCP擁塞控制算法
防止網絡擁塞現象的TCP擁塞控制算法
為了防止網絡的擁塞現象,TCP提出了一系列的擁塞控制機制。最初由V.Jacobson在1988年的論文中提出的TCP的擁塞控制由“慢啟動(Slowstart)”和“擁塞避免(Congestionavoidance)”組成,后來TCPReno版本中又針對性的加入了“快速重傳(Fastretransmit)”、“快速恢復(FastRecovery)”算法,再后來在TCPNewReno中又對“快速恢復”算法進行了改進,近些年又出現了選擇性應答(selectiveacknowledgement,SACK)算法,還有其他方面的大大小小的改進,成為網絡研究的一個熱點。
TCP的擁塞控制主要原理依賴于一個擁塞窗口(cwnd)來控制,在之前我們還討論過TCP還有一個對端通告的接收窗口(rwnd)用于流量控制。窗口值的大小就代表能夠發送出去的但還沒有收到ACK的最大數據報文段,顯然窗口越大那么數據發送的速度也就越快,但是也有越可能使得網絡出現擁塞,如果窗口值為1,那么就簡化為一個停等協議,每發送一個數據,都要等到對方的確認才能發送第二個數據包,顯然數據傳輸效率低下。TCP的擁塞控制算法就是要在這兩者之間權衡,選取最好的cwnd值,從而使得網絡吞吐量最大化且不產生擁塞。
由于需要考慮擁塞控制和流量控制兩個方面的內容,因此TCP的真正的發送窗口=min(rwnd,cwnd)。但是rwnd是由對端確定的,網絡環境對其沒有影響,所以在考慮擁塞的時候我們一般不考慮rwnd的值,我們暫時只討論如何確定cwnd值的大小。關于cwnd的單位,在TCP中是以字節來做單位的,我們假設TCP每次傳輸都是按照MSS大小來發送數據的,因此你可以認為cwnd按照數據包個數來做單位也可以理解,所以有時我們說cwnd增加1也就是相當于字節數增加1個MSS大小。
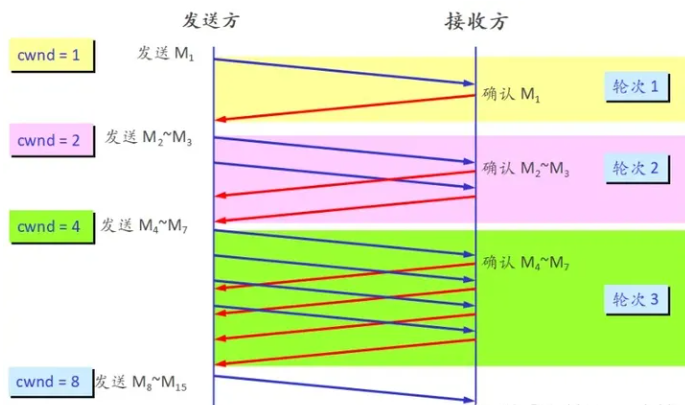
慢啟動:最初的TCP在連接建立成功后會向網絡中發送大量的數據包,這樣很容易導致網絡中路由器緩存空間耗盡,從而發生擁塞。因此新建立的連接不能夠一開始就大量發送數據包,而只能根據網絡情況逐步增加每次發送的數據量,以避免上述現象的發生。具體來說,當新建連接時,cwnd初始化為1個最大報文段(MSS)大小,發送端開始按照擁塞窗口大小發送數據,每當有一個報文段被確認,cwnd就增加1個MSS大小。這樣cwnd的值就隨著網絡往返時間(RoundTripTime,RTT)呈指數級增長,事實上,慢啟動的速度一點也不慢,只是它的起點比較低一點而已。我們可以簡單計算下:
開始 --->cwnd=1
經過1個RTT后--->cwnd=2*1=2
經過2個RTT后---> cwnd=2*2=4
經過3個RTT后---> cwnd=4*2=8
如果帶寬為W,那么經過RTT*log2W時間就可以占滿帶寬。
擁塞避免:從慢啟動可以看到,cwnd可以很快的增長上來,從而最大程度利用網絡帶寬資源,但是cwnd不能一直這樣無限增長下去,一定需要某個限制。TCP使用了一個叫慢啟動門限(ssthresh)的變量,當cwnd超過該值后,慢啟動過程結束,進入擁塞避免階段。對于大多數TCP實現來說,ssthresh的值是65536(同樣以字節計算)。擁塞避免的主要思想是加法增大,也就是cwnd的值不再指數級往上升,開始加法增加。此時當窗口中所有的報文段都被確認時,cwnd的大小加1,cwnd的值就隨著RTT開始線性增加,這樣就可以避免增長過快導致網絡擁塞,慢慢的增加調整到網絡的最佳值。
上面討論的兩個機制都是沒有檢測到擁塞的情況下的行為,那么當發現擁塞了cwnd又該怎樣去調整呢?
首先來看TCP是如何確定網絡進入了擁塞狀態的,TCP認為網絡擁塞的主要依據是它重傳了一個報文段。上面提到過,TCP對每一個報文段都有一個定時器,稱為重傳定時器(RTO),當RTO超時且還沒有得到數據確認,那么TCP就會對該報文段進行重傳,當發生超時時,那么出現擁塞的可能性就很大,某個報文段可能在網絡中某處丟失,并且后續的報文段也沒有了消息,在這種情況下,TCP反應比較“強烈”:
1.把ssthresh降低為cwnd值的一半
2.把cwnd重新設置為1
3.重新進入慢啟動過程。
從整體上來講,TCP擁塞控制窗口變化的原則是AIMD原則,即加法增大、乘法減小。可以看出TCP的該原則可以較好地保證流之間的公平性,因為一旦出現丟包,那么立即減半退避,可以給其他新建的流留有足夠的空間,從而保證整個的公平性。
其實TCP還有一種情況會進行重傳:那就是收到3個相同的ACK。TCP在收到亂序到達包時就會立即發送ACK,TCP利用3個相同的ACK來判定數據包的丟失,此時進行快速重傳,快速重傳做的事情有:
1.把ssthresh設置為cwnd的一半
2.把cwnd再設置為ssthresh的值(具體實現有些為ssthresh+3)
3.重新進入擁塞避免階段。
后來的“快速恢復”算法是在上述的“快速重傳”算法后添加的,當收到3個重復ACK時,TCP最后進入的不是擁塞避免階段,而是快速恢復階段。快速重傳和快速恢復算法一般同時使用。快速恢復的思想是“數據包守恒”原則,即同一個時刻在網絡中的數據包數量是恒定的,只有當“老”數據包離開了網絡后,才能向網絡中發送一個“新”的數據包,如果發送方收到一個重復的ACK,那么根據TCP的ACK機制就表明有一個數據包離開了網絡,于是cwnd加1。如果能夠嚴格按照該原則那么網絡中很少會發生擁塞,事實上擁塞控制的目的也就在修正違反該原則的地方。
具體來說快速恢復的主要步驟是:
1.當收到3個重復ACK時,把ssthresh設置為cwnd的一半,把cwnd設置為ssthresh的值加3,然后重傳丟失的報文段,加3的原因是因為收到3個重復的ACK,表明有3個“老”的數據包離開了網絡。
2.再收到重復的ACK時,擁塞窗口增加1。
3.當收到新的數據包的ACK時,把cwnd設置為第一步中的ssthresh的值。原因是因為該ACK確認了新的數據,說明從重復ACK時的數據都已收到,該恢復過程已經結束,可以回到恢復之前的狀態了,也即再次進入擁塞避免狀態。
快速重傳算法首次出現在4.3BSD的Tahoe版本,快速恢復首次出現在4.3BSD的Reno版本,也稱之為Reno版的TCP擁塞控制算法。
可以看出Reno的快速重傳算法是針對一個包的重傳情況的,然而在實際中,一個重傳超時可能導致許多的數據包的重傳,因此當多個數據包從一個數據窗口中丟失時并且觸發快速重傳和快速恢復算法時,問題就產生了。因此NewReno出現了,它在Reno快速恢復的基礎上稍加了修改,可以恢復一個窗口內多個包丟失的情況。具體來講就是:Reno在收到一個新的數據的ACK時就退出了快速恢復狀態了,而NewReno需要收到該窗口內所有數據包的確認后才會退出快速恢復狀態,從而更一步提高吞吐量。
SACK就是改變TCP的確認機制,最初的TCP只確認當前已連續收到的數據,SACK則把亂序等信息會全部告訴對方,從而減少數據發送方重傳的盲目性。比如說序號1,2,3,5,7的數據收到了,那么普通的ACK只會確認序列號4,而SACK會把當前的5,7已經收到的信息在SACK選項里面告知對端,從而提高性能,當使用SACK的時候,NewReno算法可以不使用,因為SACK本身攜帶的信息就可以使得發送方有足夠的信息來知道需要重傳哪些包,而不需要重傳哪些包。
編輯:hfy
-
TCP
+關注
關注
8文章
1349瀏覽量
78986 -
數據包
+關注
關注
0文章
252瀏覽量
24363 -
SACK
+關注
關注
0文章
2瀏覽量
7417
發布評論請先 登錄
相關推薦

基于衛星網絡的TCP擁塞控制算法
MANET網絡TCP非擁塞控制識別序列與恢復
基于RED算法的非線性擁塞控制
Linux中傳輸控制協議的擁塞控制分析
基于模糊控制和壓縮感知的無線傳感網絡擁塞算法
具有預測與自我調節能力的擁塞控制算法
如何用eBPF寫TCP擁塞控制算法?
Linux內核網絡擁塞控制算法的具體實現框架(一)
Linux內核網絡擁塞控制算法的實現框架(二)
Linux內核網絡擁塞控制算法的實現框架(三)






 工商網監
工商網監
評論