 OpenAI重磅推出語言模型DALL·E和圖像識別系統CLIP
OpenAI重磅推出語言模型DALL·E和圖像識別系統CLIP
人工智能(AI)研究組織OpenAI重磅推出了最新的語言模型DALL·E和圖像識別系統CLIP。
這兩個模型是OpenAI第三代語言生成器的一個分支。兩種神經網絡都旨在生成能夠理解圖像和相關文本的模型。OpenAI希望這些升級后的語言模型能夠以接近人類解釋世界的方式來解讀圖像。
2020年5月,OpenAI發布了迄今為止全球規模最大的預訓練語言模型GPT-3。GPT-3具有1750億參數,訓練所用的數據量達到45TB。對于所有任務,應用GPT-3無需進行任何梯度更新或微調,僅需要與模型文本交互為其指定任務和展示少量演示即可使其完成任務。
GPT-3在許多自然語言處理數據集上均具有出色的性能,包括翻譯、問答和文本填空任務,還包括一些需要即時推理或領域適應的任務等,已在很多實際任務上大幅接近人類水平。
新發布的語言模型DALL·E,是GPT-3的120億參數版本,可以按照自然語言文字描述直接生成對應圖片!
這個新系統的名稱DALL·E,來源于藝術家薩爾瓦多·達利(Salvador Dali)和皮克斯的機器人英雄瓦力(WALL-E)的結合。新系統展示了“為一系列廣泛的概念”創造圖像的能力,可從文字標題直接創建圖像以表達概念。通過從文本描述而不是標簽數據生成圖像,可以為模型提供了更多有關含義的上下文。
開發人員將DALL·E稱為“轉換語言模型”(transformer language model),能夠將文本和圖像作為單個數據流接收。這種訓練程序使得DALL·E不僅可以從零開始生成圖像,而且還可以重新生成現有圖像的任何矩形區域……。以一種與文本提示一致的方式。
這種語言模型能夠反映人類語言的微妙之處,包括 “將不同的想法結合起來合成物體的能力”。例如,在DALL·E模型中輸入“牛油果形狀的扶手椅”,它就可以生成這樣的圖片:

DALL·E還擴展了被稱為“零樣本推理”(zero-shotreasoning)的GPT-3功能,這是一種強大的常識性機器學習形式。DALL·E將這一功能擴展到了視覺領域,并且在以正確的方式提示時能夠執行多種圖像到圖像的翻譯任務。

圖像識別系統CLIP的通用性比當前針對單個任務的系統更好,可以用網上公開的文字圖像配對數據集來訓練。CLIP系統可用于對比語言-圖像預訓練,通過從網絡圖像中收集的自然語言監督學習視覺概念。OpenAI表示CLIP的工作方式是提供要識別的視覺類別的名稱。
當將其應用于圖像分類基準時,可以指示模型執行一系列基準,而無需針對每個測試進行優化。OpenAI表示:“通過不直接針對基準進行優化,我們證明它變得更具代表性。” CLIP方法可將“穩健性差距”縮小多達75%。
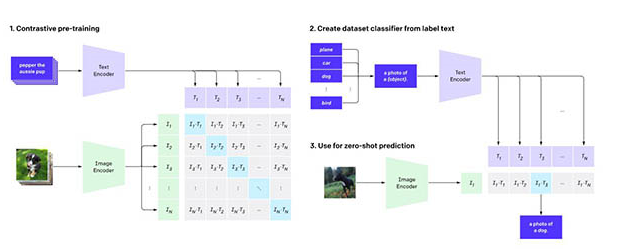
OpenAI 聯合創始人、首席科學家 Ilya Sutskever認為,人工智能的長期目標是構建多模態神經網絡,即AI能夠學習不同模態之間的概念(文本和視覺領域為主),從而更好地理解世界,而 DALL·E 和 CLIP 使我們更接近“多模態 AI 系統”這一目標。
未來,我們將擁有同時理解文本和圖像的模型。人工智能將能夠更好地理解語言,因為它可以看到單詞和句子的含義。
編輯:hfy
-
神經網絡
+關注
關注
42文章
4764瀏覽量
100542 -
圖像識別
+關注
關注
9文章
519瀏覽量
38239 -
人工智能
+關注
關注
1791文章
46872瀏覽量
237593 -
Clip
+關注
關注
0文章
31瀏覽量
6651 -
OpenAI
+關注
關注
9文章
1044瀏覽量
6408
發布評論請先 登錄
相關推薦
AI圖像識別攝像機

AI大模型在圖像識別中的優勢
圖像識別算法都有哪些方法
圖像識別算法的提升有哪些
圖像識別算法的優缺點有哪些
圖像識別技術包括自然語言處理嗎
圖像識別技術的原理是什么
圖像識別屬于人工智能嗎
如何利用CNN實現圖像識別
愛芯元智推出邊端側智能SoCAX650N,讓視覺更智能
OpenAI推出專用的AI檢測工具
微軟封禁員工討論OpenAI DALL-E 3模型漏洞
圖像識別技術原理 圖像識別技術的應用領域
基于TensorFlow和Keras的圖像識別






 工商網監
工商網監
評論