 如何輕松掌握機器學習概念和在工業自動化中的應用
如何輕松掌握機器學習概念和在工業自動化中的應用
要說現在最熱門的前沿技術,那非人工智能(AI)莫屬。而人工智能的核心卻是機器學習(ML)。可以說,掌握了機器學習,你也就掌握了人工智能技術。
那么,對于工業用戶來說,如何將機器學習引入到自動化領域,突破傳統自動化技術發展的天花板呢?面對人工智能、機器學習、深度學習、神經網絡……這些深奧的概念,如何快速了解和掌握呢?
今天,給我5分鐘,我告訴你答案!一文讓您對機器學習的概念、關鍵技術、如何應用到工業自動化之中等全部都輕松掌握!
首 先
我們先來看一個,用機器學習進行優化的一個運動控制案例,以便你對機器學習有一個感性的認識。
這是兩個相同的直線加圓弧的傳輸軌道,但我們可以看到,左邊軌道上的工件輸送十分平緩,而右邊軌道上的工件傳輸很不平穩,加速很急,產品都快要被甩出去了。這不僅對軌道上的工件影響很大,而且軌道自身的磨損也很嚴重,右邊軌道上工件運動曲線的設計顯然不如左邊的傳輸軌道。
那如何才能設計出左邊這樣的運動曲線呢?這里就需要用到機器學習,通過對工件多次的速度、加速度、位置等信息的記錄,再經過建立數據模型,不斷優化(訓練)模型,最后得出一個最佳的運動曲線。為何要用機器學習來設計呢,這是因為這樣的運動曲線設計并沒有現存的曲線(如正圓、橢圓、漸開線等),也不能通過數學方程計算出來,所以只有借助機器學習的“算法模型加訓練”來求解出來。
看完這個例子,你對機器學習的作用應該有了一個初步認識。下面我們再來理解幾個常見概念。
人工智能(AI)
能夠模仿人智力的智能,分為弱AI和強AI,目前AI處于弱AI階段。
機器學習(ML)
達到弱AI的水平,基于可以通過“訓練數據”學習特定任務的數學模型進行優化。
深度學習(DL)
專注于深度神經網絡(DNN)作為模型,需要大量數據集進行訓練的復雜模型,目前主要用于強大的視覺應用。
三者的關系是從屬關系,如下圖所示:
簡單理解,機器學習就是通過根據各類算法建立數學模型,然后通過數據不斷訓練模型,提高模型準確性,最后將訓練好的模型放到實際應用場景中運行做推理計算,解決用普通數學方法難以解決的實際問題。
所以我們可以總結一下,將機器學習引入到工業自動化中,需要三步:收集工業現場數據、建立模型并訓練模型、下載到實際應用中運行,如下圖所示:
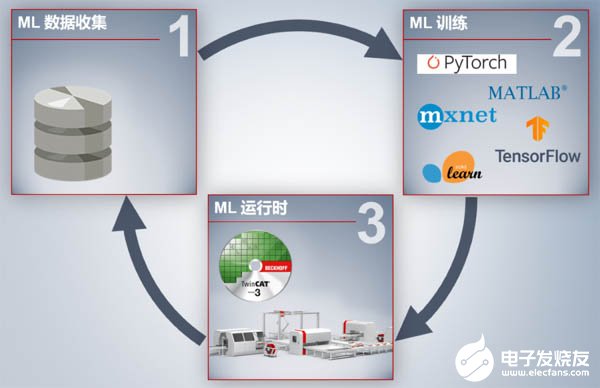
看上去是不是過程很簡單?
當然了,實際使用過程并非如此簡單,每個環節都會涉及到專業知識和工具,下面我們就來一一展開介紹一下,讓你不僅入門,而且成為“專家”!
第 /一/ 步 收集工業現場數據
首先,在數據收集階段,就是要通過各類傳感器和測試測量工具來采集現場數據,這個環節就會用到我們自動化控制中的很多產品,比如像倍福的TwinCAT3 Scope、TwinCAT3 Database Server、TwinCAT3 Data Agent和TwinCAT3 Analytics Logger等工具,可以利用這些工具將數據采集到本地數據庫或者云端存儲、呈現,以便下一步來建模和訓練。
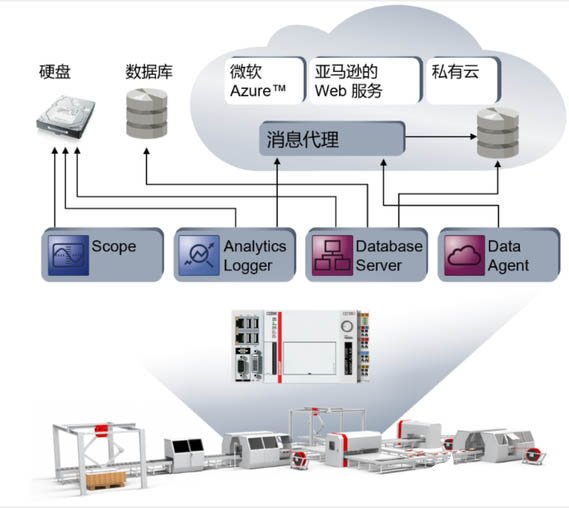
第 /二/ 步 模型的搭建和訓練
這一步是至關重要的一步,也是目前機器學習中最難、研究最多的一步。這一步里首先需要對上一步采集到的數據進行預處理,數據清洗除去異常值,數據轉化或者數據集成等。然后,選擇特征數據確定數學模型,進行學習微調,并進行未知數據的學習模型驗證。模型訓練后,生成導出一個可供TwinCAT3等模型運行環境的描述文件:XML文件或者ONNX文件。這一步中特征數據的挖掘,也就是提取哪些數據來建模是整個機器學習能否成功的關鍵,往往需要精通行業知識經驗的人才能做到。
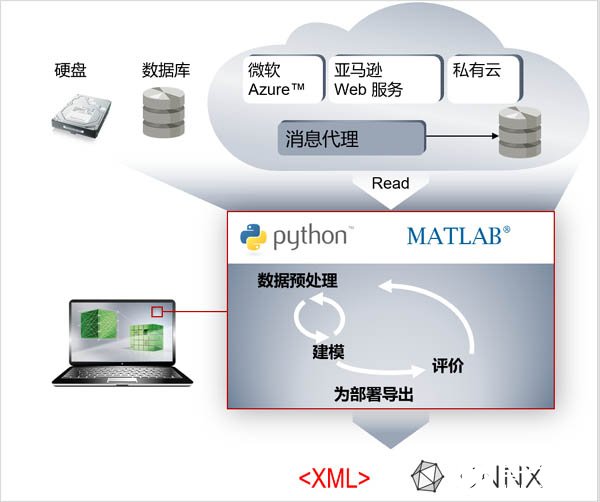
在這一步中,搭建模型時往往需要用到第三方框架(平臺工具),比如:Python SciKit、MATLAB Machine Learning Toolbox,以及深度學習框架TensorFlow (谷歌)、Keras (frontend for TensorFlow, CNTK, …)、PyTorch (臉書)、MxNet (亞馬遜)、CNTK (微軟)、MATLAB Deep Learning Toolbox (MathWorks)等,其中大多數是開源的和基于Python的。

當然,除了這些框架外,還有一個重要的事,數學模型的選擇和建立。在數學上,可以把萬事萬物所有問題分為兩大問題:回歸問題和分類問題。回歸問題通常是用來預測一個值,如預測房價、未來的天氣情況等。分類問題是用于將事物打上一個標簽,通常結果為離散值,如判斷一幅圖片上的動物是一只貓還是一只狗。解決這兩類問題需要用到不同的數學模型,比如常見的有支持向量機(SVM)、神經網絡、決策樹和隨機森林、線性回歸、貝葉斯線性回歸等,這些模型在框架中是現存的,可以直接使用。
在這里,還需要提到一個知識點,那就是ONNX開放神經網絡交換文件,這是一種針對機器學習所設計的開放式文件格式,用于存儲訓練好的模型。它使得不同的人工智能框架(如Pytorch,MXNet)可以采用相同格式存儲模型數據并交互。主要由微軟,亞馬遜 ,Facebook 和 IBM 等公司共同開發。

第 /三/ 步 加載模型到控制器里運行
說完了模型搭建和模型訓練后,最后一步就是將模型加載到工業電腦或者控制器中運行計算。由于模型描述文件并不能被工業控制器所識別,所以就需要用到像倍福TwinCAT 3這樣的自動化控制軟件平臺作為引擎,將訓練好的模型文件加載到控制器,才能在自動化中應用機器學習。
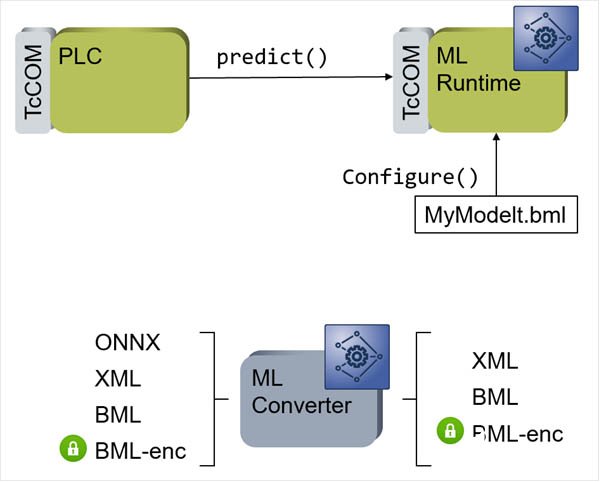
目前、TwinCAT3以及無縫集成了機器學習引擎接口。可以通過機器學習文件轉換器(ML Converter)把訓練生成的模型文件XML或者ONNX轉化成BML(倍福的機器學習文件)進行加密保護,經過TwinCAT3 的ML Runtime 進行加載,這樣已訓練好的模型就可以被TwinCAT TcCOM對象進行實時調用執行,同時可以被PLC、C/C++ 封裝的TcCOM的接口進行調用!如果神經網絡較小,如權值大小為10K的多層感知器(MLP)可以在一個亞毫秒的任務周期中多次調用,以確保實時性!
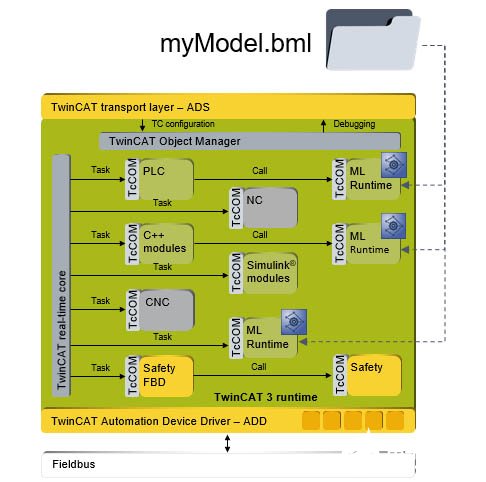
同時,TwinCAT 3本身所提供的支持多核技術也同樣適用于機器學習應用,不同的任務程序可以訪問同一個特定的TwinCAT 3推理引擎而不會相互限制。機器學習應用完全可以訪問TwinCAT中所有可用的現場總線接口和數據,這將使其能夠使用到大量數據。
TwinCAT 3現在有兩個機器學習推理引擎,TF380x TC3和TF381x TC3,前者是經典機器學習模型的推理引擎,包括支持向量機(SVM), 主成分分析(PCA), k均值(k-means)等,后者是神經網絡(NN)推理引擎,包括多層感知器(MPL),卷積神經網絡(CNN),長短期記憶模型(LSTM)等。
舉個例子 最優運動曲線是如何“機器學習”出來的
看完了上面的一般性方法介紹,下面我們再拿文章開頭的那個傳輸軌道最優運動曲線是如何通過機器學習來進行優化的。
首先,將這個運動曲線優化的問題轉化為數學問題,在一定的時間內,從pi順時針到pf找到最優(最柔和)的運動曲線,運動過程中加速度要盡量小。
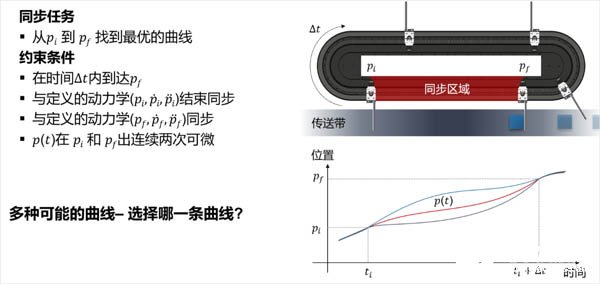
1第一步
就是要采集數據,包括工件的位置、速度、加速度、時間等,把這些數據收集存儲起來,以便下一步優化。

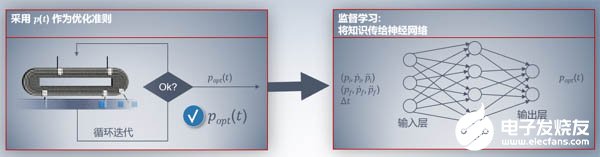
2第二步
提取步驟一里面的特征數據建立模型,用 ??(??) 來作為優化準則,通過神經網絡算法來循環迭代,監督學習訓練模型。
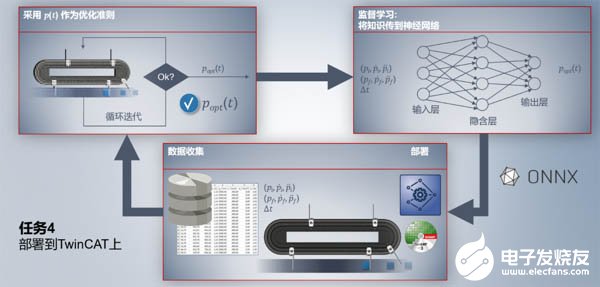
3第三步
將訓練好的模型通過ONNX文件部署到TwinCAT 3里,從而通過控制器實現最優的運動曲線。
舉個例子 一個不需要故障數據的風扇異常檢測
通常,我們通過大數據分析來做預測性維護,需要很多故障數據,可工業實際場景中往往沒有太多故障數據,比如一個風機在開始幾年并不太會有故障,只有到后期才有故障數據。可是,通過機器學習的方法,就可以解決這個問題,在無需故障數據的情況做到故障檢測。
比如,要檢測下圖服務器工作站上的風扇是否有異常,就可以通過機器學習來做。
首先,通過TwinCAT 3 Scope來采集大量風扇正常情況下的壓力、轉速、振動等數據,然后用MATLAB來讀取這些數據,使用one-class SVM(一類支持向量機)模型來訓練,等模型學習了大量正常數據后,就會自動產生一個正常數據的邊界。最后將模型從MATLAB導出為一個ONNX文件,轉換后加載到控制器的TwinCAT 3中。這樣,當采集的數據超出邊界時,控制器就會檢測到風扇發生了異常狀況。
這個應用看上去是十分簡單的,但是這其中最難的一部分是特征數據的挖掘和提取,也就是常說的特征工程。至于數據的采集、模型的創建、訓練,以及最后的控制器上的運行,已經有很多現存的工具和平臺,比如MATLAB和倍福的TwinCAT 3。站在這些“巨人”的肩膀上,你只要專注用工業現場知識和經驗,就可以輕松將機器學習這一“高大上”的新技術引入到工業自動化之中。
編輯:hfy
-
神經網絡
+關注
關注
42文章
4765瀏覽量
100559 -
機器學習
+關注
關注
66文章
8381瀏覽量
132431
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論