") 臺積電5nm與三星5nm的本質差異 三星5LPE與臺積電N5詳解
臺積電5nm與三星5nm的本質差異 三星5LPE與臺積電N5詳解
“5nm翻車”也算是近期的一個熱門話題了,似乎去年下半年發(fā)布的,包括驍龍888、麒麟9000、蘋果A14等在內(nèi)的一眾應用了5nm工藝的手機芯片,都在功耗和發(fā)熱表現(xiàn)上不夠理想。
驍龍888(小米11)跑個Geekbench 5,單CPU功耗就達到了7.8W,堪稱驍龍近代能耗比最差,Adreno GPU性能首次遜于隔壁Mali;而麒麟9000(華為Mate40 Pro)雖說GPU性能上去了,但在光明山脈測試中,跑出了11W的峰值功耗;這都是向著PC功耗看齊的節(jié)奏了。很多媒體也因此將5nm冠以“集體翻車”的名號。
高通驍龍888、三星Exynos 2100選擇三星5nm,而海思麒麟9000、蘋果A14選擇了臺積電5nm。事實上,即便都叫5nm,臺積電和三星的5nm工藝也差異甚遠——所以“集體翻車”這種說法首先就值得商榷。這兩者甚至不該直接比較。本文我們根據(jù)Wikichip、Semiwiki、Semiconductor Digest等機構所做的研究,嘗試談談兩家5nm工藝的一些基本差異。
雖說從微觀層面,比如材料、晶體管性能等無法直接比較;而且臺積電甚至沒有公開5nm工藝晶體管的關鍵尺寸(暫時也沒有5nm工藝的相關“拆解”)。本文僅嘗試給出兩者大方向上的差異。
雖說主流芯片功耗爆表是否真的與臺積電、三星的5nm工藝有關,個人持保留意見。但通過這篇文章,我們也能更好地理解,如今的尖端工藝發(fā)展成了什么樣。
到底晶體管的哪個部分是5nm?
在探討兩種5nm工藝差異前,首先仍需明確一個概念。即現(xiàn)在的“幾nm”工藝這樣的稱謂,頂多就是個營銷概念。不管是7nm還是5nm,晶體管或者芯片微觀層面,都不存在哪個幾何參數(shù)是7nm或5nm。如此一來,5nm也就名副其實地成為了一個虛指,它僅能用于表達一個工藝節(jié)點,“5”不存在實際意義。
早在1997年以前,幾點幾微米或幾百納米工藝,的確是指晶體管上gate(柵或閘)的長度(Lg)。比如0.35μm,350nm,確實就是指gate長度為350nm。在350nm制造工藝以前的時代,工藝數(shù)字步進以0.7倍為節(jié)奏,比如350nm x0.7,下一代工藝就該是250nm了。
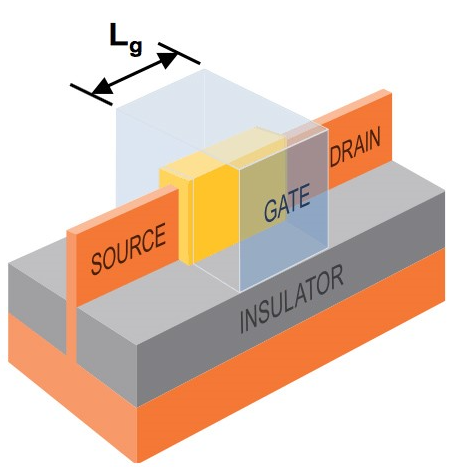
FinFET結構晶體管
不過到了奔騰3時期的250nm工藝,實則已經(jīng)不再真正指代晶體管gate長度。250nm節(jié)點的gate長度已經(jīng)來到了190nm,但晶體管的其他部分卻無法以對等的比例來同步縮減。從這一時期開始,工藝節(jié)點的這一數(shù)字便不再具有太大的實際意義。2012年22nm節(jié)點問世時,隨之而來的FinFET晶體管結構。這種3D結構要用一個數(shù)字來衡量晶體管尺寸也更難了。
在20nm以后,越來越多的節(jié)點數(shù)字也拋棄了0.7倍步進的傳統(tǒng)。14nm、7nm、5nm雖然仍遵循0.7倍步進傳統(tǒng),但12nm、8nm、6nm、4nm等則顯然更具營銷意味了。自不必說,這些數(shù)字本身,除了表達工藝迭代之外,便再無更多意義。
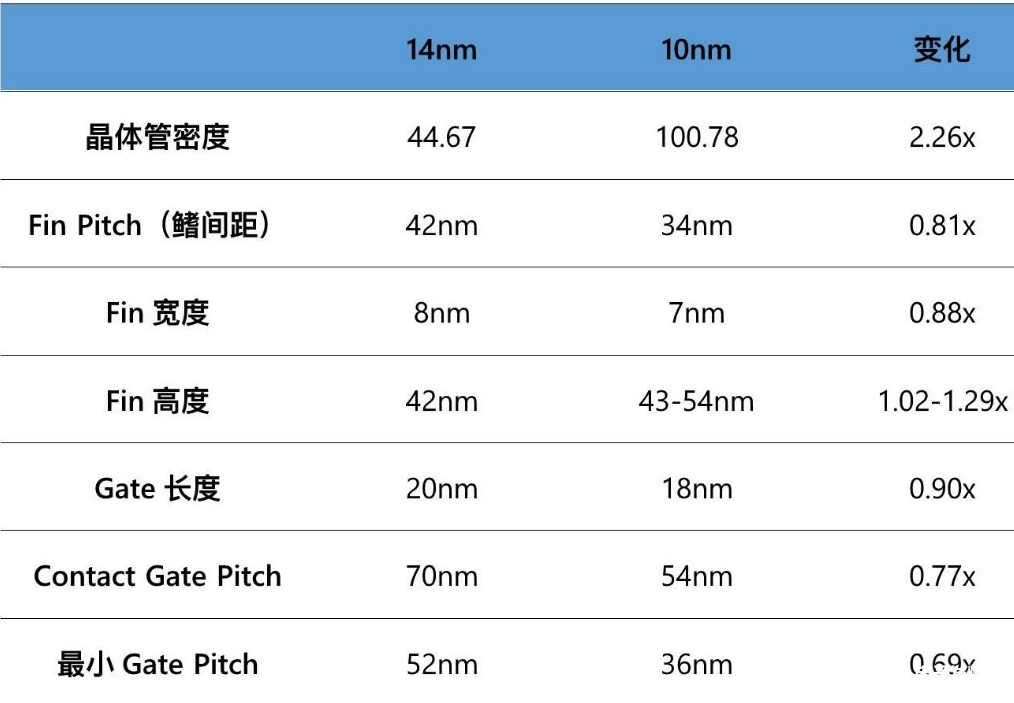
若一定要說在晶體管上,與如今這個節(jié)點數(shù)字還有所關聯(lián)的部分,那大概就是fin寬度了,上面這張圖是Intel的14nm與10nm兩代工藝,晶體管各關鍵參數(shù)的變化,其中fin寬度大致與節(jié)點數(shù)字是一個量級。
臺積電5nm與三星5nm的本質差異
我在去年《同樣是臺積電7nm,蘋果和華為的7nm其實不一樣》一文中曾大致總結過,臺積電與三星7nm可認為是同代工藝,從Wikichip預估的數(shù)字來看,這兩者的晶體管密度(高密度庫)應該也差不了多少。
但這兩家fab的工藝路線方向卻已經(jīng)發(fā)生了較大差異。在7nm時代,三星foundry以更激進的姿態(tài),率先在多個疊層采用了EUV(極紫外)光刻。臺積電的7nm路線圖中,至少N7與N7P工藝仍然沒有采用EUV,直到N7+才用上了4層EUV光刻層。
臺積電N7+工藝的情況比較特別。市面上選擇了N7+的芯片似乎很少——知名的大概也就是Kirin 990 5G版了(Kirin 990 4G版用的是N7工藝)。而且N7+與N7/N7P并不兼容。
臺積電N7后續(xù)的完整迭代自然就是N5了——節(jié)點數(shù)字也符合0.7倍步進的節(jié)奏。所以對臺積電而言,5nm的確就是7nm的迭代工藝。
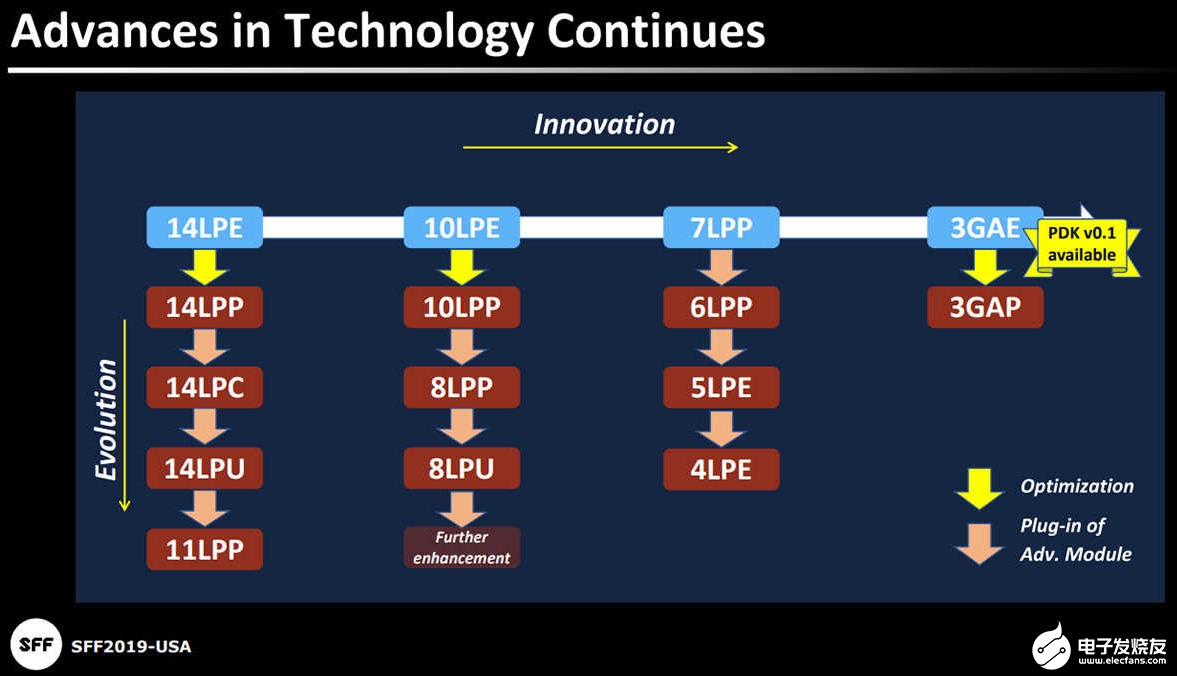
但三星這邊可不一樣。三星近些年的路線演進,開始走完整迭代時的大步子。比如在三星眼中,10nm到7nm屬于節(jié)點的完整迭代,所以7LPP就相對激進地用上了EUV。在7LPP往后,三星foundry路線圖的完整迭代,下一代工藝應該是3nm(3GAA)。且7nm->3nm的工藝迭代,邁的大步在于晶體管結構從FinFET,演進至GAAFET(Gate-All-Around FET)或/和MBCFET,也就是傳說中的納米線和納米片。
而5nm在三星眼中實則屬于1/4代工藝,或者說5LPE屬于7LPP工藝的同代加強,是向3nm工藝的過渡。三星的7nm與5nm的關系,更類似于其10nm與8nm的關系,如上圖所示。三星7LPP工藝同代加強,還包括了6nm、5nm、4nm。
如此一來,臺積電和三星(以及Intel)未來的工藝迭代可能要進一步發(fā)生分歧。比如臺積電預期中的3nm,至少前期并不打算采用GAA結構。當然,3nm就屬于題外話了,而且雖然三星的3GAA工藝PDK前年就進入了Alpha階段,但其量產(chǎn)至少也要等到明年。
這種迭代節(jié)奏上的差異(以及雙方7nm的起點差不多),導致了臺積電在5nm節(jié)點上跨的步子,會明顯比三星更大,或者說更先進。至于后續(xù)3nm如何,尚不得而知。所以N5與5LPE理論上是兩家公司的兩個不同產(chǎn)品,而不應將其理解為某個固定標準下,雙方各自交出的答卷。
兩種5nm工藝的晶體管密度
鑒于篇幅關系,本文就不再科普FinFET晶體管結構,以及Fin Pitch、Gate Pitch、CPP、不同金屬層的基本概念了。對這些內(nèi)容感興趣的同學,可閱讀《為什么說Intel的10nm工藝比別家7nm更先進?(上)》,里面有比較詳細的科普。
下面這兩張圖表給出的數(shù)據(jù)分別來自Scotten Jones(IC Knowledge,via Semiwiki)和David Schor(WikiChip Fuse)。下圖綜合了三星、臺積電已公開的信息,以及針對現(xiàn)有公開信息的一些分析。
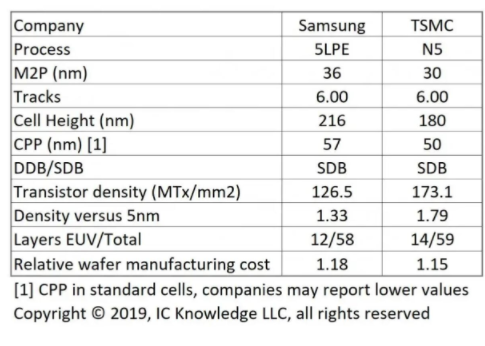
來源:Scotten Jones, IC Knowledge via SemiWiki[1],發(fā)布于2019.5
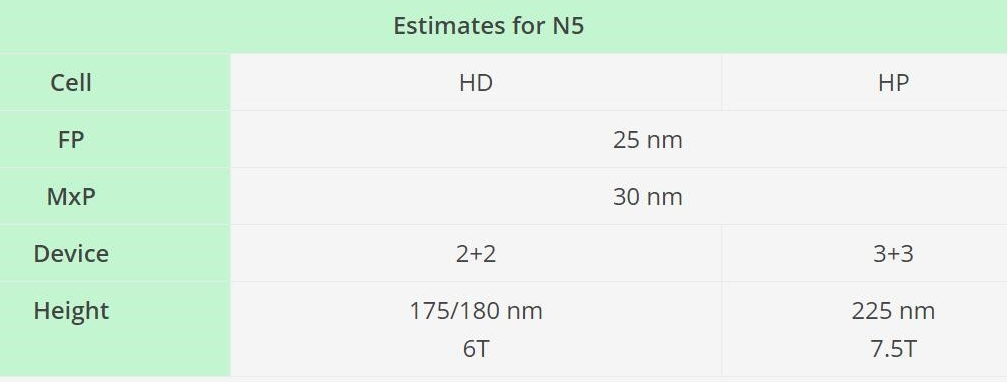
來源:David Schor, WikiChip Fuse[2],發(fā)布于2020.3
這其中值得一提的主要是晶體管密度(Transistor Density),此處IC Knowledge預計臺積電N5工藝的密度為173.1 MTr/mm2(百萬晶體管每平方毫米,特指邏輯電路HD高密度單元庫),WikiChip Fuse此前預估數(shù)字則為171.3 MTr/mm2[2]。
IC Knowledge預計三星5LPE工藝的晶體管密度(UHD超高密度單元)126.5 MTr/mm2,WikiChip則預估為126.89 MTr/mm2[3]。
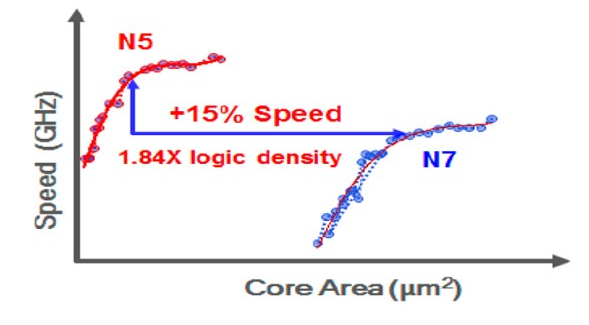
臺積電N5邏輯電路1.84倍晶體管密度提升,與同功耗水平下15%速度提升
雖然有區(qū)別,但量級上差不多,臺積電N5還是比三星5LPE要高出不少的(Scotten Jones在2019年年末又更新過一次晶體管密度預估,似乎又大了不少[4])。無論如何,這一點也能看出臺積電和三星的5nm雖然都叫5nm,但跨步幅度還是很不一樣。
另外在CPP(contacted poly pitch,柵間距)、M2P(Metal 2 Pitch,金屬間距)這樣的晶體管關鍵數(shù)值上,大神們預估的值也有一些差異,IC Knowledge標臺積電N5工藝的CPP是50nm,WikiChip則估算為48nm;而M2P,IC Knowledge后來又將其更新到了28nm。這兩張表格僅供參考——注意其發(fā)布時間也有差異。
事實上,三星5LPE與上一代7LPP相比,就單個晶體管的關鍵參數(shù)來看,各部分是幾乎沒有變化的,晶體管密度提升依靠的主要是單元庫變化,以及各種scaling booster方法(比如SDB)。
臺積電N5可不是這樣。此處未詳細列出N5相比N7的晶體管各部分關鍵參數(shù)變化。從WikiChip提供的數(shù)據(jù)來看,CPP間距N7為57nm,N5則為48nm;MMP則從40nm縮減到了30nm[5]。這也進一步佐證了三星5LPE屬于7LPP的同代加強或過渡,而臺積電N5是N7的完整迭代。
驍龍888“翻車”都是5nm的鍋嗎?
很多人說高通被三星坑了,這話大抵上是站不住腳的,或者其功耗表現(xiàn)不佳并不只是三星的鍋。芯片設計12-18個月周期,在前期定義配置時,選擇的制造工藝就已經(jīng)定下來了,如今設計與制造的緊密程度是相當之甚的——且當代工藝差異,也不大可能在芯片設計階段中途突然就轉到另一種工藝上。
高通驍龍888選擇三星5LPE工藝,必然是有自己的考量的。高通也絕對不可能不知道,前文提到5LPE與N5工藝這些最基本的差異。至于高通的考量究竟是制造成本本身,還是設計IP的遷移便利性,就不得而知了。或許將來TechInsights的深度拆解能探索一二。
此前的文章里提到過,這些晶體管密度數(shù)字只具有參考價值。一方面在于不同時代計算晶體管密度的方法是有差別的,這在《為什么說Intel的10nm工藝比別家7nm更先進?(上)》一文中就已經(jīng)詳細提過了。而且一顆芯片上,晶體管并不是只有邏輯電路,更非僅采用HD高密度單元,晶體管也不是均勻分布。具體的仍要看芯片本身的設計。
在IEDM上,臺積電提到對于包含60%邏輯單元、30% SRAM,以及10%模擬I/O的移動SoC而言,其5nm工藝能夠縮減芯片35%-40%的尺寸——這樣的值是更具參考價值的。
至于工藝迭代或增強,對性能、功耗產(chǎn)生的具體影響,廠商公布的數(shù)字恐怕是很難驗證的。后文會提到三星5LPE通過引入6T UHD單元、減fin以減少單元高度的方式來實現(xiàn)晶體管密度33%的增加。它對性能帶來的影響也很難考證,或者我們這些業(yè)外人士也無法搞清楚,這種方案究竟是好還是不好。
去年在上海舉辦的Exynos芯片發(fā)布會上,三星有提到5LPE令芯片面積降低35%,功耗效率提升20%,性能表現(xiàn)提升10%。臺積電則針對N5的功耗和性能數(shù)字提過,同功耗下速度提升15%,同性能下功耗降低30%。這些數(shù)字的意義可能都并不大,尤其在面對各種不同的IC設計時。
舉個例子,驍龍888的CPU部分,大核心Cortex-X1。Cortex-X1是Arm的Greek家族CPU架構,它與當時一同公布的Cortex-A78在設計理念上就有較大差異。通常移動CPU更看重低功耗,并且要在功耗、性能與面積(PPA)之間達成平衡,功耗與能耗比更是每年Arm升級IP的重點。

但Cortex-X1是打破了這種傳統(tǒng)的。其設計指針更偏向性能,且在功耗、面積方面有一定妥協(xié)。X1架構有了明顯拓寬,在A78設計基礎上,再加包括前端5-wide解碼寬度,renaming帶寬最高每周期8 Mop,NEON加倍,L2、L3 cache加倍等。Mop cache條目加倍,甚至比Intel Sunny Cove(十代酷睿)還要大。
比較具有代表性的是Re-order Buffer(ROB)增加到224條目,此前是160,以提升指令亂序與并行度。以前Arm在這方面是一直偏保守的。Arm以前曾提過,ROB拓寬帶來的性能提升,與芯片面積增加,兩者關系不呈線性,而且還需要以功耗為代價。Cortex-X1顯然已經(jīng)看破這些了。更多有關Cortex-X1的架構拓寬,不是本文要探討的重點。
雖然論架構寬度,Cortex-X1的基礎設計還是沒法和蘋果Firestorm(M1與A14)比,但Cortex-X1面向芯片制造商開始采用一種”Cortex-X Custom Program”授權計劃。這種授權方式下,客戶可以對微架構做進一步定制,比如說要求更大的ROB、改進的prefetcher等。我們不知驍龍888針對Cortex-X1的具體實施,不過它以性能為更高優(yōu)先級的設計,致驍龍888產(chǎn)生不對等的功耗,設計與IP也是重要因素。
Arm在此前發(fā)布Cortex-X1時大力宣傳了其IPC及性能提升,但對功耗和面積效益語焉不詳。AnandTech猜測,X1面積和功耗都可能是A78的1.5倍;在預設功耗(power)下,X1核心的能效(energy efficiency,每焦耳的性能)會比A78糟糕23%[6]。
當然我們不能就此認定,驍龍888峰值性能下的功耗與能效比都是Cortex-X1的問題,而且Cortex-X1設計原則本身就是如此。驍龍888涉及到的問題可能覆蓋了Arm、高通、EDA工具廠商,以及三星foundry。何況驍龍888 GPU部分的Adreno 660針對上代改進(提頻)也比較倉促。單純說驍龍888的功耗問題需要三星5LPE工藝背鍋,顯然是不靠譜的。
至于很多人說5nm“集體翻車”,前文談到了臺積電N5工藝與三星5LPE差異較大,演進方向也不同。而將5nm一概而論,以驍龍888和麒麟9000為例來說“這一代工藝都不行”更是無稽之談。在麒麟9000的GPU IP上,Arm為Mali G78設計,堆至多24個核心原本就相當令人困惑。
即便要說臺積電N5工藝“翻車”,或者三星5LPE“翻車”,這兩輛車“翻”的姿勢和方向應該也有很大差異。
再提一提后續(xù)改進版工藝,三星方面自然就是4LPE了,而臺積電則為N5P。4LPE的晶體管和大部分基本思路都與5LPE一致,不過金屬互聯(lián)間距有進一步的縮減;而臺積電的N5P與N5有著相同的設計規(guī)則,完全的IP兼容性,同功耗下7%性能提升,同性能夠下15%功耗降低。
三星5LPE與臺積電N5詳解(選讀)
以下部分作為本文選讀內(nèi)容,僅針對感興趣的讀者。這部分內(nèi)容只反映了臺積電和三星公開的有關N5和5LPE的事實,無法作為直接比較的依據(jù)(因為三星和臺積電公開的信息內(nèi)容其實并不對稱);另外也包含來自WikiChip Fuse、Semiconductor Digest的點評和設想;另外個人進行了少量信息補充,貽笑大方之處歡迎指正。其中的大部分內(nèi)容是早就公開的信息。
(1)三星5LPE
有關三星5LPE工藝,Exynos 1080剖析文章中已經(jīng)有比較詳細的介紹,這里做一些簡單概括。
如前文所述,在晶體管尺寸方面,5LPE相比7LPP幾乎沒有變化,包括fin pitch、gate pitch、各層金屬間距等。對于芯片設計方而言,7LPP到5LPE的設計IP可極大程度復用[8]。5LPE的幾個改進重點包括:
引入一種新型的6T UHD(超高密度)單元庫。6T UHD單元相比三星7nm HD單元縮減了一個fin。如此一來,整個單元高度就變小了,可實現(xiàn)面積縮減、密度提升。當然,為了防止性能下降,需要考慮做材料或結構加強,包括low-k spacer、DC等方面。具體細節(jié)不了解。
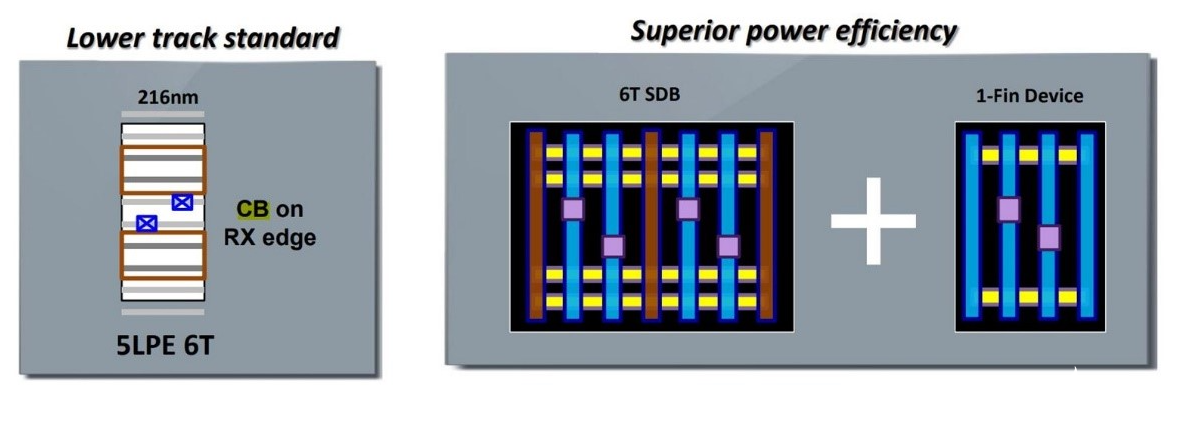
來源:Arm TechCon 2019[7]
6T UHD單元包括采用SDB(single diffusion break)、36nm的M2金屬間距,CB on RX edge(RX是指單元的活躍區(qū)域,CB屬于額外的本地互聯(lián)層,在單元內(nèi)橫向布局,將接觸層的觸點連接到多晶硅本地互聯(lián)——位于第一層金屬層之下,也就是MOL互聯(lián);所以CB on RX edge也就是CB互聯(lián)層用到單元活躍區(qū)域邊緣)。
UHD單元可實現(xiàn)33%的密度提升,不過這種單元庫并不會應用于高性能需求的關鍵路徑部分,畢竟高性能總是以犧牲密度為代價的。更稀疏的7.5T HD單元仍然是必要選擇(似乎比7nm HD單元還要高),三星的數(shù)字是其性能提升11%。7.5T UHD單元之間并未采用SDB,而是MDB(pMOS為SDB,nMOS為DDB)。
另外5LPE工藝還引入一種低漏電的1-fin device(1個p fin,1個n fin),可提供至多20%的功耗節(jié)約。實際上,從這些改進也不難發(fā)現(xiàn),5LPE的確主要是基于7LPP工藝的加強——雖然有關6T UHD單元的晶體管加強細節(jié)信息并不多。
(2)臺積電N5
最后主要來說說臺積電N5工藝。事實上,臺積電公開N5工藝的細節(jié)也不多,前文提到有關N5晶體管的數(shù)字,都是大佬們自己依據(jù)經(jīng)驗給出的。臺積電在IEDM2019放出了比較多有關N5工藝的消息。

首先是EUV光刻技術的采用,前文的表格中也提到了N5有14層EUV光刻層——這比N7+就多了不少(先前的數(shù)據(jù)是N7+的EUV光刻層為4層,N6可能是5層)。此前7nm介紹文章中提到過,像偏底部、間距比較小的金屬層,在常規(guī)DUV下就需要依靠SAQP或者LE3外加多個刻版掩模才能搞定。應用EUV之后,所需掩模層就少了很多。臺積電在paper中提到N5的EUV層,替換了此前至少4倍的浸入層(immersion layer)——對比的可能是N7+。
可以從上圖看到,EUV掩模圖案也更清晰,或者說有更高的保真度;減少掩模數(shù)量、提升保真度,本身也對生產(chǎn)時間成本、良率有幫助。當然三星5LPE所用的EUV層從前文的圖表看來,也并不少。
臺積電N5相比N7,總體上就減少了掩模——而且似乎是工藝迭代歷史上,首次減少了掩模數(shù)量(WikiChip給出的數(shù)據(jù)是,14/16nm大約60層掩模,10nm則為78層,7nm為87層,5nm回到了81層;如果沒有應用EUV的話,WikiChip預計N5需要115片掩模[2])。
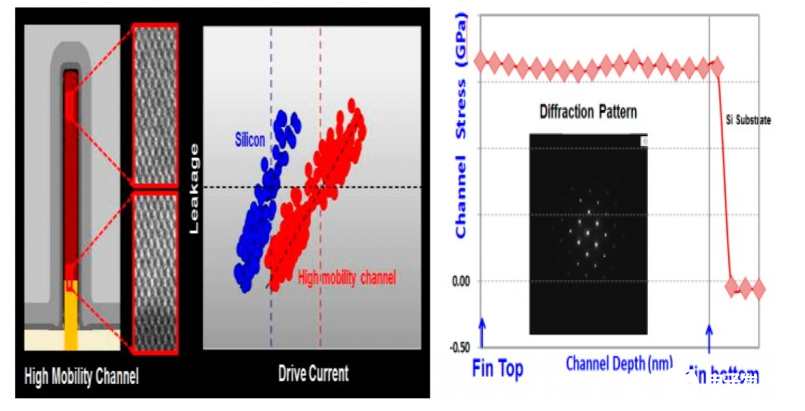
N5迭代的第二個重點是晶體管的HMC(High Mobility Channel,高遷移溝道)。這項改進主要是為了提升驅動電流。上圖有展示HMC與硅,兩種溝道材料方案的驅動電流與漏電流關系比較,HMC有18%的性能優(yōu)勢。
其中右圖展示的是,從fin頂端到底部,隨溝道深度變化而產(chǎn)生的溝道應力變化。臺積電沒有給出HMC的更多信息。WikiChip認為,HMC的本質是針對pMOS采用SiGe(鍺化硅)[2],Semiconductor Digest也在分析文章中做了類似的猜測[9]。

Intel 10nm工藝介紹中的SDB,單元之間共享一個dummy gate,以節(jié)約空間
Intel 10nm工藝介紹中的COAG,MOL與gate的接觸點位置發(fā)生變化,以節(jié)約空間
在工藝迭代中,有一個詞叫scaling booster。這個詞描述的是在常規(guī)晶體管尺寸縮減技術之外的加強方案。比如說SDB、COAG——這些在Intel 10nm介紹文章的上篇中都有談到過,Intel在宣傳中稱其為hyperscaling。前文三星5LPE的某些尺寸縮減方案也能見到scaling booster,比如SDB。
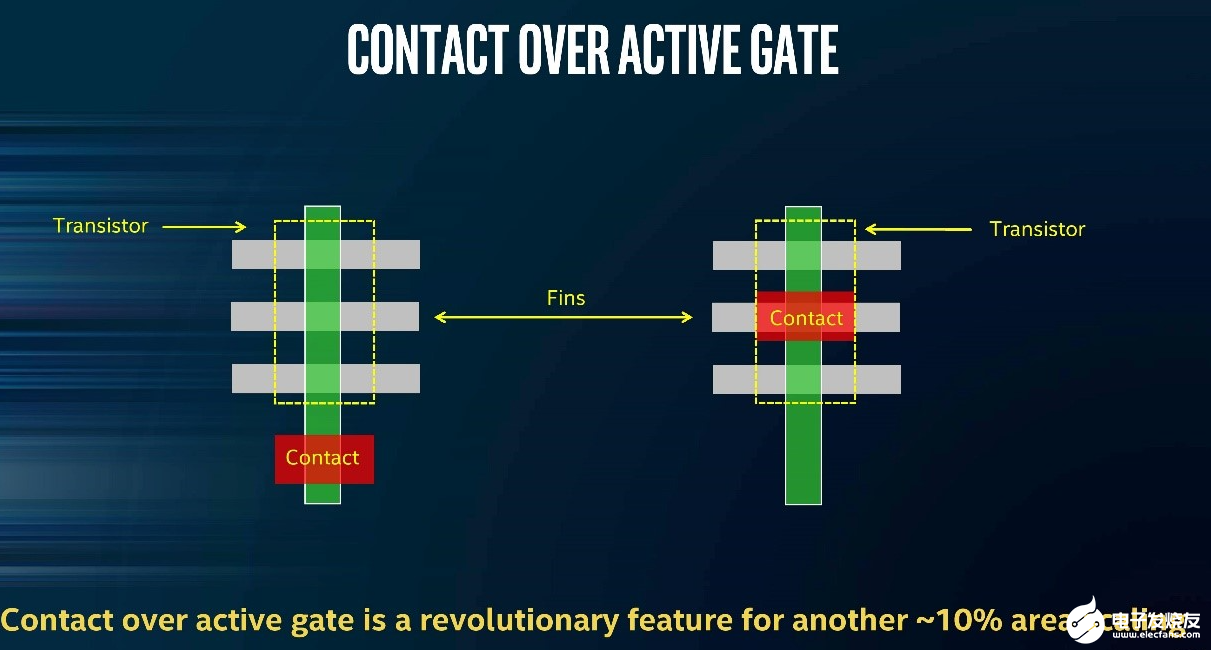
臺積電N5工藝的scaling booster方案主要包括了“unique diffusion termination”,國外這些分析機構普遍認為,這項技術的本質應該就是SDB[2][9],即單元之間共享一個dummy gate(如上圖);另外,N5也采用了COAG方案,即將gate contact直接放在晶體管active區(qū)域上方(如上圖)——Intel 10nm工藝也采用了這項技術。這兩種技術更多的介紹,都可參見Intel 10nm技術文章。
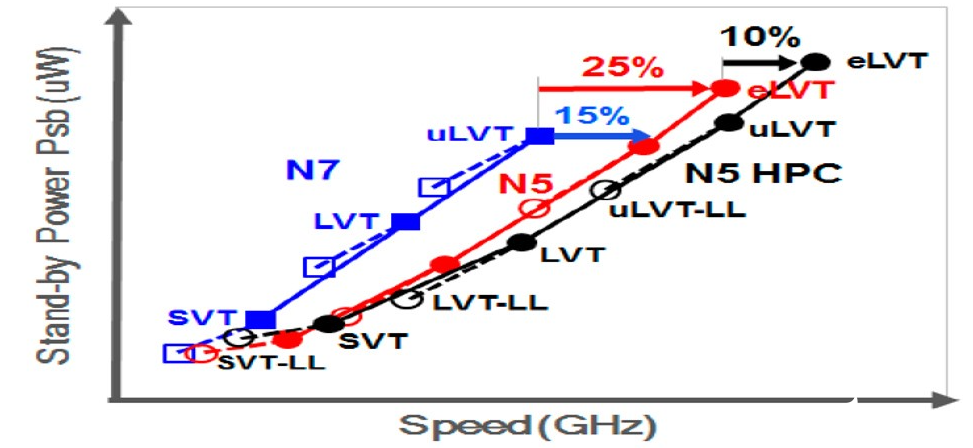
此外,N5的每個晶體管類型都有至多7種Vt(閾值電壓)選擇,以此來滿足不同的能效需求。其中有個新的eLVT(extreme LVT,LVT是指Low Voltage Threshold)晶體管,相比7nm能夠實現(xiàn)15-25%的速度提升。
臺積電還談到一種3 fin的單元——面向HPC應用(此前規(guī)劃中N5就有面向移動客戶和HPC客戶兩種),有額外10%的性能優(yōu)勢,密度也會相對低一些。
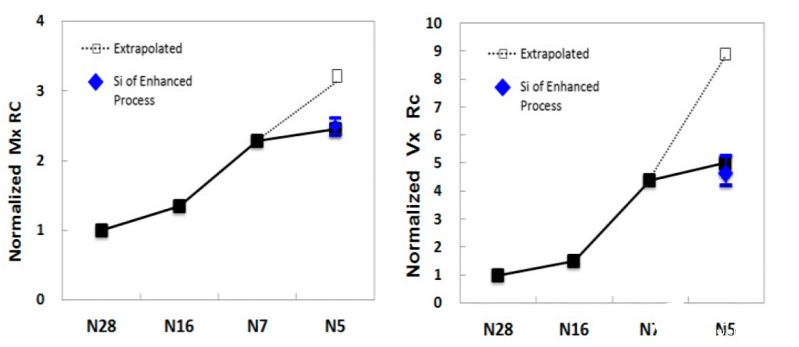
BEOL金屬互層的改進在于,間距最小的RC(接觸電阻)與via電阻(通路電阻)相比N7工藝的增加并不大。臺積電實現(xiàn)這一點靠的是EUV,以及“innovative scaled barrier/liner, ESL/ELK dielectrics, and Cu reflow”。
Barrier和liner(阻隔層與襯墊)以及電介質(etch-stop layer, extreme low-k)在此前的文章里已經(jīng)有過介紹,不過此處在表達上比較模糊,這里的銅reflow不清楚具體是什么工藝。不過電阻的控制,在互聯(lián)延遲方面是有很大價值的。
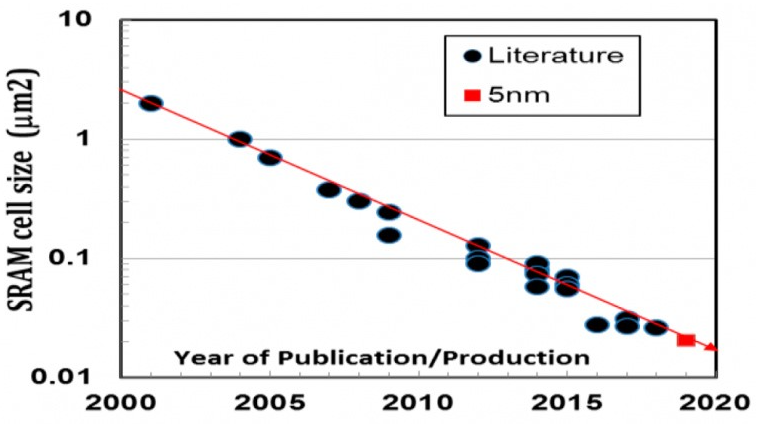
SRAM部分,在N5工藝下,HC(高性能)單元面積0.025 μm2,HD(高密度)單元面積0.021 μm2。WikiChip提到即便是其中的“高性能”單元,其密度也高于市面上已知的SRAM單元[2]。另外還有ULHD(超低漏電)單元有更高的能效,HSHD高速單元則在面積方面有優(yōu)勢,可替代HC單元[10]。
下面這張圖是ULHD、HD、HSHD單元的電流與漏電流關系;以及HD SRAM的Vin與Vout對應曲線。
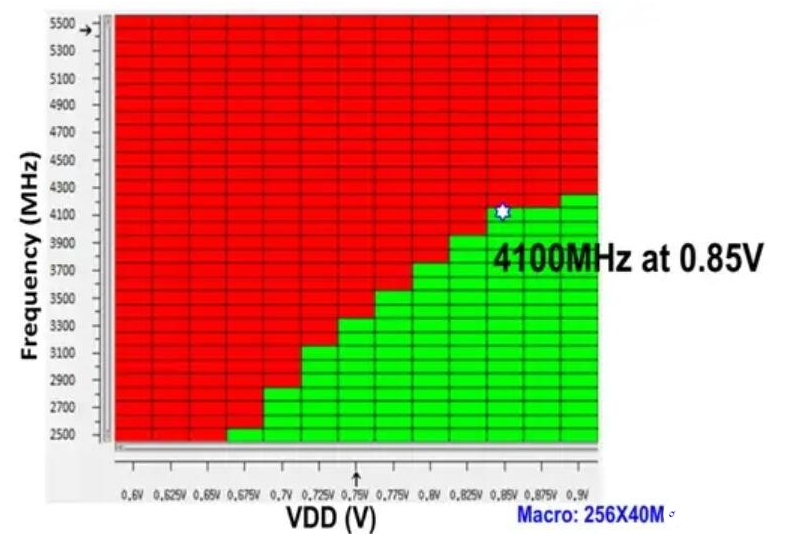
上面這張圖則展示了N5工藝下的HD單元陣列作為L1 cache時(基于135Mb測試芯片),0.85V能夠達到4.1GHz的頻率。
N5的其他改進還包括了面向高速IO,PAM-4 SerDes在112Gb/s速率下功耗0.78pJ/bit,130Gb/S功耗0.96pJ/bit。金屬互聯(lián)上層MiM(Metal-insulator-Metal)相比一般HD-MiM高出4倍的電容密度,提升4.2% Fmax等。[11]
更多有關臺積電N5與三星5LPE工藝的內(nèi)容,可參見參考來源中給出的這些鏈接以及IEDM的paper,以上只簡略地談到了其中一部分。從這些資料也能大致上看出,如果將5nm作為一個統(tǒng)一的節(jié)點,則臺積電N5顯然有著更積極的部署,而三星5LPE則是個過渡工藝;后續(xù)4LPE與N5P的競爭也不會改變這一局面。但3nm的競爭可能又會大不一樣了。
編輯:hfy
-
臺積電
+關注
關注
43文章
5505瀏覽量
165550 -
晶體管
+關注
關注
77文章
9403瀏覽量
136637 -
5nm
+關注
關注
1文章
342瀏覽量
25907 -
麒麟9000
+關注
關注
1文章
154瀏覽量
7862 -
驍龍888
+關注
關注
0文章
147瀏覽量
11930
發(fā)布評論請先 登錄
相關推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論