 研究:Magenta的微分數字信號處理
研究:Magenta的微分數字信號處理
簡介
Sounds of India 是一款獨特而有趣的交互式音樂體驗應用,以印度傳統為靈感,并由機器學習提供支持。當用戶在演唱印度歌曲時,瀏覽器中的機器學習模型會實時將他們通過移動設備上輸入的聲音轉換為各種印度古典樂器的聲音。
Sounds of India
https://soundsofindia.withgoogle.com/
完成整個體驗的開發過程僅需 12 周,您可了解開發者在使用 TensorFlow 生態系統時,如何快速地將模型從研究階段推進到規模化生產。
研究:Magenta 的微分數字信號處理
Magenta 是 Google AI 中的一個開源研究項目,旨在探索機器學習可以有哪些創新使用。微分數字信號處理 (Digital Signal Processing,DDSP) 是一個全新的開源庫,融合了現代機器學習與可解釋信號處理技術。
Magenta
https://magenta.tensorflow.org/
DDSP
https://magenta.tensorflow.org/ddsp
不同于訓練純深度學習模型(如 WaveNet)去逐個渲染樣本的波形,我們改為訓練輕量級模型,這些模型能夠向這些可微的 DSP 模塊中輸出隨時間變化的控制信號(因此,DDSP 中有一個額外的“D”),從而合成最終聲音。我們在 TensorFlow Keras 層的遞歸和卷積模型中整合了 DDSP,其有效生成音頻的速度為更大型自回歸模型的 1000 倍,而對模型參數和訓練數據的需求僅為后者的百分之一。
WaveNet
https://deepmind.com/blog/article/wavenet-generative-model-raw-audio
DDSP 中一個有趣的應用是音色轉換,即將用戶輸入的聲音轉換為樂器聲。先用目標薩克斯對 DDSP 模型開展 15 分鐘的訓練。然后,你可以演唱一段旋律,經過訓練的 DDSP 模型會將其重新渲染成薩克斯的聲音。我們已在 Sounds of India 中將這項技術應用于三種印度古典樂器:Bansuri、Shehnai 和 Sarangi。
音色轉換
https://colab.sandbox.google.com/github/magenta/ddsp/blob/master/ddsp/colab/demos/timbre_transfer.ipynb#scrollTo=Go36QW9AS_CD
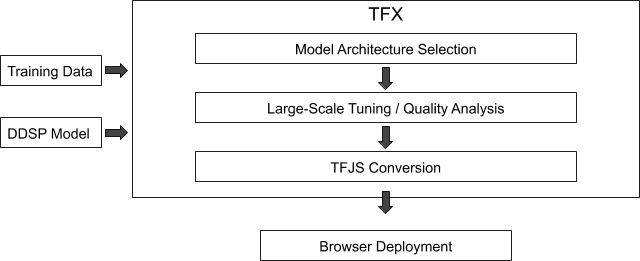
使用 TFX,TFJS 訓練并部署到瀏覽器中
TFX
TensorFlow Extended (TFX)是用于生產機器學習 (ML) 的端到端平臺,包括準備數據、訓練、驗證和在生產環境中部署模型。使用 TFX 訓練模型(將用戶的聲音轉換為上述某種樂器聲),然后將這些模型轉換為 TensorFlow.js 格式,以部署在標準網絡瀏覽器中。
TensorFlow Extended (TFX)
https://tensorflow.google.cn/tfx/
TensorFlow.js
https://tensorflow.google.cn/js
通過部署到瀏覽器中,為用戶帶來與機器學習模型交互的無縫體驗:僅需點擊超鏈接,加載網站頁面。而無需安裝工作。在瀏覽器中運行客戶端,我們能夠直接在傳感器數據源處執行推理,從而最大程度地減少延遲,降低與大型顯卡、CPU 和內存相關的服務器成本。此外,應用會將您的聲音用作輸入,因此用戶隱私十分重要。由于整個端到端的體驗都發生在客戶端和瀏覽器當中,因此傳感器或麥克風收集到的數據保留在用戶的設備上。
基于瀏覽器的機器學習模型需要進行優化以盡可能縮減其大小,從而降低所用帶寬。在這種情況下,每種樂器的理想超參數也大有不同。我們利用 TFX 對數百個模型進行大規模訓練和調試,確定每個樂器可用的最小模型尺寸。因此,我們能夠大幅降低其內存占用。例如,在未對音質產生明顯影響的情況下,Bansuri 樂器模型的磁盤占用量約降低至以前的二十分之一。
我們還可借助 TFX 在不同的模型架構(GRU、CNN)、不同類型的輸入(響度、RMS 能量)和不同的樂器數據源上執行快速迭代。我們每次都能夠快速有效地運行 TFX 流水線,生成具有所需特性的新模型。
TensorFlow.js
構建 TensorFlow.js DDSP 模型需要達到嚴格的性能和模型質量目標,所以具有獨特的挑戰性。模型需要高效執行音色轉換,以便在移動設備上有效運行。同時,一旦模型質量出現任何下降,便會導致音頻失真,進而破壞用戶體驗。
我們首先探索了眾多的 TensorFlow.js 后端和模型架構。WebGL 后端的優化程度最高,而 WebAssembly 后端則可在低端手機上運行良好。我們采用了基于 Convnet 的 DDSP 模型,并利用 WebGL 后端,以滿足 DDSP 的計算需求。
WebGL 后端
https://github.com/tensorflow/tfjs/tree/master/tfjs-backend-webgl
WebAssembly 后端
https://github.com/tensorflow/tfjs/tree/master/tfjs-backend-wasm
為縮短模型下載時間。我們研究了模型的拓撲結構,并使用 Fill/ZeroLike 算子壓縮了大量常數張量,從而將模型大小從 10MB 縮減到 300KB。
為使 TensorFlow.js 模型準備就緒,以便在生產環境中將其大規模部署在設備上,我們還重點關注了以下三個主要領域:推理性能、內存占用和數值穩定性。
推理性能優化
DDSP 模型中包括神經網絡和信號合成器。合成器部分包含許多需要大量算力的信號處理算子。為提升模型在移動設備上的性能,我們使用特殊的 WebGL Shader 重新編寫了內核,以便充分利用 GPU。例如,通過并行累積求和算子,推理時間可縮短 90%。
降低內存占用
我們的目標是盡可能在更多種類型的移動設備上運行模型。由于許多手機的 GPU 顯存有限,我們需要確保盡可能降低模型的內存占用。通過處理中間張量并添加新標記,我們能夠提早處理 GPU 紋理,從而實現這一目標。通過這些方法,我們可以將顯存占用減少 60%。
數值穩定性
DDSP 模型需要達到非常高的數值精度,才能生成動聽的音樂。這一點與常見的分類模型截然不同:在分類模型中,一定范圍內的精度降低并不會影響最終的分類結果。我們在此體驗中使用的 DDSP 模型為生成模型。任何精度較低和不連續的音頻輸出都可輕易被我們敏感的耳朵發覺。使用 float16 WebGL 紋理時,我們遇到了數值穩定性問題。因此,我們重新編寫了一些主要算子,以減少輸出結果的上溢和下溢。例如,在累積求和算子中,我們會確保在 Shader 內以全浮點精度完成累積,并在將輸出結果寫入 float16 紋理前,運用模數計算來避免結果溢出。
動手嘗試!
您可使用手機訪問 g.co/SoundsofIndia,嘗試此體驗。如您愿意,請與我們分享您的結果。我們十分期待看到您用自己的聲音所創作的音樂。
如果您有興趣了解機器學習如何增強創造力與創新性,可瀏覽 Magenta 團隊的博客,詳細了解該項目,并為他們的開源 GitHub 貢獻力量,也可查看 #MadeWithTFJS,從 TensorFlow.js 社區獲得更多瀏覽器端機器學習示例。如果您對使用 ML 最佳做法在生產環境中大規模訓練并部署模型比較感興趣,請查看 Tensorflow Extended。
博客
https://magenta.tensorflow.org/blog
GitHub
https://github.com/magenta/magenta
#MadeWithTFJS
https://twitter.com/search?q=%23madewithtfjs&src=typed_query
致謝
本項目的實現離不開 Miguel de Andrés-Clavera、Yiling Liu、Aditya Mirchandani、KC Chung、Alap Bharadwaj、Kiattiyot (Boon) Panichprecha、Pittayathorn (Kim) Nomrak、Phatchara (Lek) Pongsakorntorn、Nattadet Chinthanathatset、Hieu Dang、Ann Yuan、Sandeep Gupta、Chong Li、Edwin Toh、Jesse Engel 的巨大努力,以及 Michelle Carney、Nida Zada、Doug Eck、Hannes Widsomer 和 Greg Mikels 提供的其他幫助。非常感謝 Tris Warkentin 和 Mitch Trott 的大力支持。
-
數字信號處理
+關注
關注
15文章
557瀏覽量
45795 -
機器學習
+關注
關注
66文章
8377瀏覽量
132409 -
tensorflow
+關注
關注
13文章
328瀏覽量
60499
原文標題:案例分享 | 輕量而高效,12 周落地一個趣味音樂交互!
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論