") 大數(shù)據(jù)技術(shù)發(fā)展史簡介 淺談大數(shù)據(jù)挖掘與機(jī)器學(xué)習(xí)
大數(shù)據(jù)技術(shù)發(fā)展史簡介 淺談大數(shù)據(jù)挖掘與機(jī)器學(xué)習(xí)
目前大數(shù)據(jù)已經(jīng)成為了各家互聯(lián)網(wǎng)公司的核心資產(chǎn)和競爭力了,其實(shí)不僅是互聯(lián)網(wǎng)公司,包括傳統(tǒng)企業(yè)也擁有大量的數(shù)據(jù),也想把這些數(shù)據(jù)發(fā)揮出作用。在這種環(huán)境下,大數(shù)據(jù)技術(shù)的重要性和火爆程度相信沒有人去懷疑。
而AI人工智能又是基于大數(shù)據(jù)技術(shù)基礎(chǔ)上發(fā)展起來的,大數(shù)據(jù)技術(shù)已經(jīng)很清晰了,但是AI目前還未成熟啊,所以本文就天馬行空一下,從大數(shù)據(jù)的技術(shù)變遷歷史中來找出一些端倪,猜一猜AI人工智能未來的發(fā)展。
最近斷斷續(xù)續(xù)的在看《極客時間》中「 從0開始學(xué)大數(shù)據(jù) 」專欄的文章,受益匪淺,學(xué)到了很多。尤其是非常喜歡作者李智慧講的那句話“學(xué)習(xí)大數(shù)據(jù)最好的時間是十年前,其次就是現(xiàn)在”,把這句話改到AI也適用,“學(xué)習(xí)AI最好的時間是十年前,其次就是現(xiàn)在”,任何知識都是這樣。下面我們就來詳細(xì)聊一聊。
一、先聊一聊大數(shù)據(jù)技術(shù)發(fā)展史?
我們使用的各種大數(shù)據(jù)技術(shù),最早起源于Google當(dāng)年公布的三篇論文,Google FS(2003年)、MapReduce(2004年)、BigTable(2006年),其實(shí)Google當(dāng)時并沒有公布其源碼,但是已經(jīng)把這三個項(xiàng)目的原理和實(shí)現(xiàn)方式在公布的論文中詳細(xì)的描述了,這幾篇論文面世后,就引爆了行業(yè)的大數(shù)據(jù)學(xué)習(xí)和研究的浪潮。
隨后一個叫 Doug Cutting 的技術(shù)大牛(也就是寫 Lucene 的那位,做JAVA的同學(xué)應(yīng)該都很熟悉)就開始根據(jù)Google公布的論文去開發(fā)相關(guān)系統(tǒng),后來慢慢發(fā)展成了現(xiàn)在的 Hadoop,包括 MapReduce 和 HDFS。
但是在當(dāng)時,使用 MapReduce 進(jìn)行數(shù)據(jù)分析和應(yīng)用還是有很大門檻的,畢竟要編寫 Map 和 Reduce 程序。只能大數(shù)據(jù)工程師上馬,普通BI分析師還是一臉懵逼。所以那個時候都是些大公司在玩。
既然有這么大門檻,就會有人勇于站出來去解決門檻,比如 Yahoo,他們開發(fā)一個叫做 Pig 的東西,Pig是一個腳本語言,按照Pig的語法寫出來的腳本可以編譯成 MapReduce 程序,然后直接在 Hadoop 上運(yùn)行了。
這個時候,大數(shù)據(jù)開發(fā)的門檻確實(shí)降了一點(diǎn)。
不過,Pig大法雖好,但還是需要編寫腳本啊,這還是碼農(nóng)的活兒啊。人們就在想,有沒有不用寫代碼的方法就能做大數(shù)據(jù)計(jì)算呢,還真有,這個世界的進(jìn)步就是由一群善于思考的“懶人”推動的。
于是,F(xiàn)acebook公司的一群高智商家伙發(fā)布了一個叫做 Hive 的東西,這個 Hive 可以支持使用 SQL 語法直接進(jìn)行大數(shù)據(jù)計(jì)算。原理其實(shí)就是,你只需要寫一個查詢的 SQL,然后 Hive 會自動解析 SQL 的語法,將這個SQL 語句轉(zhuǎn)化成 MapReduce 程序去執(zhí)行。
這下子就簡單了,SQL 是BI/數(shù)據(jù)分析師們最為常用的工具了,從此他們可以無視碼農(nóng),開開心心的獨(dú)立去寫Hive,去做大數(shù)據(jù)分析工作了。Hive從此就火爆了,一般公司的大多數(shù)大數(shù)據(jù)作業(yè)都是由Hive完成的,只有極少數(shù)較為復(fù)雜的需求才需要數(shù)據(jù)開發(fā)工程師去編寫代碼,這個時候,大數(shù)據(jù)的門檻才真真的降低了,大數(shù)據(jù)應(yīng)用也才真正普及,大大小小的公司都開始在自己的業(yè)務(wù)上使用了。
但是,人們的追求不止如此,雖然數(shù)據(jù)分析便利了,但是大家又發(fā)現(xiàn) MapReduce 程序執(zhí)行效率不夠高啊,其中有多種原因,但有一條很關(guān)鍵,就是 MapReduce 主要是以磁盤作為存儲介質(zhì),磁盤的性能極大的限制了計(jì)算的效率。
在這個時候,Spark 出現(xiàn)了,Spark 在運(yùn)行機(jī)制上、存儲機(jī)制上都要優(yōu)于 MapReduce ,因此大數(shù)據(jù)計(jì)算的性能上也遠(yuǎn)遠(yuǎn)超過了 MapReduce 程序,很多企業(yè)又開始慢慢采用 Spark 來替代 MapReduce 做數(shù)據(jù)計(jì)算。
至此,MapReduce 和 Spark 都已成型,這類計(jì)算框架一般都是按“天”為單位進(jìn)行數(shù)據(jù)計(jì)算的,因此我們稱它們?yōu)椤按髷?shù)據(jù)離線計(jì)算”。既然有“離線計(jì)算”,那就必然也會有非離線計(jì)算了,也就是現(xiàn)在稱為的“大數(shù)據(jù)實(shí)時計(jì)算”。
因?yàn)樵跀?shù)據(jù)實(shí)際的應(yīng)用場景中,以“天”為顆粒出結(jié)果還是太慢了,只適合非常大量的數(shù)據(jù)和全局的分析,但還有很多業(yè)務(wù)數(shù)據(jù),數(shù)據(jù)量不一定非常龐大,但它卻需要實(shí)時的去分析和監(jiān)控,這個時候就需要“大數(shù)據(jù)實(shí)時計(jì)算”框架發(fā)揮作用了,這類的代表有:Storm、Spark Streaming、Flink 為主流,也被稱為 流式計(jì)算,因?yàn)樗臄?shù)據(jù)源像水流一樣一點(diǎn)點(diǎn)的流入追加的。
當(dāng)然,除了上面介紹的那些技術(shù),大數(shù)據(jù)還需要一些相關(guān)底層和周邊技術(shù)來一起支撐的,比如 HDFS 就是分布式文件系統(tǒng),用于負(fù)責(zé)存儲數(shù)據(jù)的,HBase 是基于HDFS的NoSQL系統(tǒng)、與 HBase類似的還有 Cassandra也都很熱門。
二、再看一看大數(shù)據(jù)技術(shù)架構(gòu)?
了解大數(shù)據(jù)相關(guān)技術(shù)可以先看下圖:
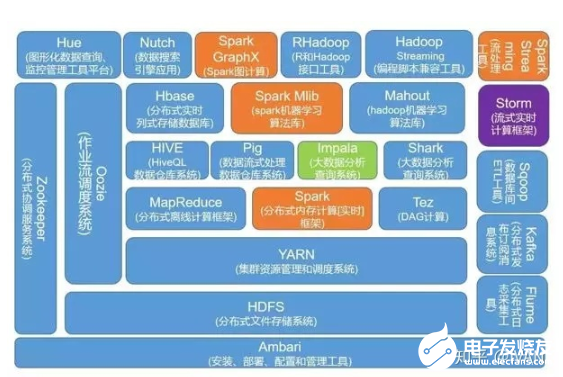
(圖片來源網(wǎng)絡(luò))
這圖基本上很全面的展示了大數(shù)據(jù)的技術(shù)棧,下面將其主要的部分羅列一下,以便有個清晰的認(rèn)知:
大數(shù)據(jù)平臺基礎(chǔ):
- MapReduce,分布式離線計(jì)算框架
- Spark,分布式離線計(jì)算框架
- Storm,流式實(shí)時計(jì)算框架
- Spark Streaming,流式實(shí)時計(jì)算框架
- Flink,流式實(shí)時計(jì)算框架
- Yarn,分布式集群資源調(diào)度框架
- Oozie,大數(shù)據(jù)調(diào)度系統(tǒng)
分布式文件系統(tǒng):
- HDFS,分布式文件系統(tǒng)
- GFS,分布式文件系統(tǒng)
SQL引擎:
- Spark SQL (Shark),將SQL語句解析成Spark的執(zhí)行計(jì)劃在Spark上執(zhí)行
- Pig,Yahoo的發(fā)布的腳本語言,編譯后會生成MapReduce程序
- Hive,是Hadoop大數(shù)據(jù)倉庫工具,支持SQL語法來進(jìn)行大數(shù)據(jù)計(jì)算,把SQL轉(zhuǎn)化MapReduce程序
- Impala,Cloudera發(fā)布的運(yùn)行在HDFS上的SQL引擎
數(shù)據(jù)導(dǎo)入導(dǎo)出:
- Sqoop,專門用將關(guān)系數(shù)據(jù)庫中的數(shù)據(jù) 批量 導(dǎo)入導(dǎo)出到Hadoop
- Canal,可以 實(shí)時 將關(guān)系數(shù)據(jù)庫的數(shù)據(jù)導(dǎo)入到Hadoop
日志收集:
Flume,大規(guī)模日志分布式收集
大數(shù)據(jù)挖掘與機(jī)器學(xué)習(xí):
- Mahout,Hadoop機(jī)器學(xué)習(xí)算法庫
- Spark MLlib,Spark機(jī)器學(xué)習(xí)算法庫
- TensorFlow,開源的機(jī)器學(xué)習(xí)系統(tǒng)
三、猜一猜AI人工智能的發(fā)展?
通過上面的回顧,我們知道了,因?yàn)榇罅繑?shù)據(jù)的產(chǎn)生導(dǎo)致大數(shù)據(jù)計(jì)算技術(shù) MapReduce 的出現(xiàn),又因?yàn)?MapReduce 的參與門檻問題,導(dǎo)致了 Pig、Hive的出現(xiàn),正是因?yàn)檫@類上手容易的工具的出現(xiàn),才導(dǎo)致大量的非專業(yè)化人員也能參與到大數(shù)據(jù)這個體系,因此導(dǎo)致了大數(shù)據(jù)相關(guān)技術(shù)的飛速發(fā)展和應(yīng)用,又從而進(jìn)一步推動了機(jī)器學(xué)習(xí)技術(shù)的出現(xiàn),有了現(xiàn)在的AI人工智能的發(fā)展。
但目前人工智能技術(shù)的門檻還比較高,并不是任何企業(yè)都能入場的,需要非常專業(yè)化的高端技術(shù)人才去參與,普通人員只能望而卻步,因此AI技術(shù)的應(yīng)用受到了極大的限制,所以也不斷的有人提出對人工智能提出質(zhì)疑。
講到這里,有沒有發(fā)現(xiàn)點(diǎn)什么問題?
歷史的規(guī)律總是那么相似。可以猜測一下,人工智能的門檻有一天也會像 MapReduce 的開發(fā)門檻一樣被打破,一旦人工智能的參與門檻降低了,各類大小企業(yè)都能結(jié)合自己的業(yè)務(wù)場景進(jìn)入AI領(lǐng)域發(fā)揮優(yōu)勢了,那AI就真的進(jìn)入高速發(fā)展的通道了,AI相關(guān)實(shí)際應(yīng)用的普及就指日可待了。
恩,一定是這樣的,哈哈,現(xiàn)在就可以等著大牛們將AI的基礎(chǔ)平臺建設(shè)好,然后降低參與門檻,進(jìn)一步就迎來了AI的一片光明,大家從此就可以過上AI服務(wù)人類的美好生活了(暢想中…)。
以上,就是從大數(shù)據(jù)技術(shù)變遷想到AI人工智能發(fā)展的一些想法。
-
人工智能
+關(guān)注
關(guān)注
1787文章
46060瀏覽量
234947 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8306瀏覽量
131838 -
大數(shù)據(jù)
+關(guān)注
關(guān)注
64文章
8805瀏覽量
136989
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論