 重點介紹數據科學領域需要知道的五大關鍵概念
重點介紹數據科學領域需要知道的五大關鍵概念
本文將重點介紹一些數據科學領域的關鍵概念,掌握它們對于你今后的職業生涯大有益處。這些概念或許你已經了解,或許你還未掌握。不論你現在是否清楚,筆者的目的是向你專業地解釋為何它們至關重要。
多重共線性、獨熱編碼、欠采樣和過采樣、誤差度量以及敘事能力,這是筆者在想到專業數據科學家日常工作時首先想到的關鍵概念。敘事能力或許算是技能和概念的結合,但筆者在此還是想強調它在數據科學家工作中的重要性。我們開始吧!
多重共線性
多重共線性雖然看起來又長又拗口,拆開來看還是易于理解的。“多重”指數量多,“共線性”則意味著線性相關。多重共線性可以描述為在回歸模型中,兩個或多個解釋變量解釋相似信息或高度相關。這一概念之所以引起關注,有以下幾個原因。
對于某些建模技術來說,多重共線性可能導致過擬合,最終降低模型性能。冗余數據時有出現,模型中的所有特征或屬性并非都是有必要的。因此,可以采用某些方法來找到應該被刪除的特征,正是它們導致了多重共線性。
方差膨脹系數(VIF)
相關矩陣
數據科學家們經常使用這兩種技術,尤其是相關矩陣和相關圖——通常用某種熱圖進行可視化,而VIF則不太為人所知。VIF值越高,該特征對回歸模型的用處就越小。
獨熱編碼
獨熱編碼是模型中的一種特征轉換形式,你可以通過編碼來數值化地體現類別特征。盡管類別特征本身有文本值,但是獨熱編碼會將這些信息轉置,以便每個值都成為特征,行中的觀察值記為0或1。例如,假設我們有分類變量gender,獨熱編碼后的數字表示如下(之前表示為gender,之后表示為male/female):

獨熱編碼處理前后對比
如果你不僅要使用數字化的特征,還需要使用文本/類別特征創建數字表示,那么此轉換非常有用。
采樣
當你擁有的數據不足時,可以使用過采樣作為一種補償。假設在處理一個分類問題時,有一個如下例所示的少數類:
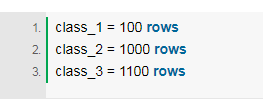
如你所見,class_1的類只有少量數據,這意味著你的數據集是不平衡的,也就是所謂的少數類。
有幾種過采樣方法。其中一種叫做SMOTE,即合成少數類過采樣技術(Synthetic Minority Over-samplingTechnique)。SMOTE的實現方式之一是采用K近鄰(K-neighbor)算法來找到最近的點以合成樣本。也有類似的技術反其道而行之,進行欠采樣。
當類或回歸數據中有離群值時,如果你希望確保模型運行在最能體現數據集的采樣結果之上,那么這些技術便能派上用場。
誤差度量
在數據科學中,有很多用于分類模型和回歸模型的誤差度量。以下是一些可以專門用于回歸模型的方法:
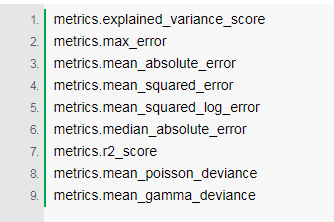
對回歸模型來說,上述誤差度量中最常用的兩種是MSE(均方誤差)和RMSE(均方根誤差):
MSE:平均絕對誤差回歸損失(引自sklearn)
RMSE:均方根誤差回歸損失(引自sklearn)
對于分類模型來說,可以用精度和ROC曲線下的面積(AUC,Area Under the Curve)來評價模型的性能。
敘事能力
敘事概念的重要性怎么強調都不為過。它可以被定義成一種概念或技能,但定義本身并不重要。重要的是,如何在商業環境中展現出自己解決問題的能力。許多數據科學家總是只關注模型的精度,但卻無法理解整個商業過程。該過程包括:
業務是什么?
問題是什么?
為何需要數據科學?
數據科學在其中的目標是什么?
何時能得到可用結果?
如何應用我們的結果?
我們的結果有什么影響?
如何分享我們的結果和整個過程?
上述問題與模型本身或提升精度無關,重點是如何使用數據來解決公司的問題。與利益相關者和非技術領域的同事相熟對此是大有助益的,在運行基礎模型之前,你需要和產品經理一道評估問題,和數據工程師一起收集數據。在模型過程結束時,你將向關鍵人員介紹結果,這些人最喜歡看可視化結果,因此掌握呈現和交流的技能也是有益的。
對于數據科學家和機器學習工程師來說,有許多需要掌握的關鍵概念。本文介紹的5點,你了解了嗎?
責編AJX
-
數據
+關注
關注
8文章
6892瀏覽量
88828 -
數字化
+關注
關注
8文章
8610瀏覽量
61640 -
數據科學
+關注
關注
0文章
165瀏覽量
10045
發布評論請先 登錄
相關推薦
智能穿戴產業的五大關鍵技術
五大關鍵詞解讀2010年半導體照明產業發展熱點
施耐德電機智能城市五大關鍵領域解決方案
決定人工智能發展的風向標五大關鍵之問
微服務五大關鍵好處揭秘
一文看懂LTE五大關鍵技術和日常維護
細談智能穿戴的五大關鍵技術
智能工廠的五大關鍵領域及特征
智能工廠五大關鍵領域及其特征體現
ADI在線研討會:精密數模轉換器的五大關鍵技術規格

制造業創新中心政策體系形成,主要聚集在五大關鍵領域







 工商網監
工商網監
評論