 arm smmu的原理
arm smmu的原理
1: arm smmu的原理
1.1: smmu 基本知識

如上圖所示,smmu 的作用和mmu 類似,mmu作用是替cpu翻譯頁表將進程的虛擬地址轉換成cpu可以識別的物理地址。同理,smmu的作用就是替設備將dma請求的地址,翻譯成設備真正能用的物理地址,但是當smmu bypass的時候,設備也可以直接使用物理地址來進行dma;
1.2: smmu 的數據結構
smmu的重要的用來dma地址翻譯的數據結構都是放在內存中的,由smmu的寄存器保存著這些表在內存中的基地址,首先就是StreamTable(STE),這ste 表既包含stage1的翻譯表結構也包含stage2的翻譯結構,所謂stage1負責VA 到 PA的轉換,stage2負責IPA到PA的轉換。
接下來我們重點看一下這個STE的結構,到底在內存中是如何組織的;
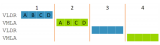
對smmu來說,一個smmu可以給很多個設備服務,所以,在smmu里面為了區分的對每個設備進行管理,smmu 給每一個設備一個ste entry,那設備如何定位這個ste entry呢?對于一個smmu來說,我們給他所管理的每個設備一個唯一的device id,這個device id又叫 stream id;對于設備比較少的情況下,我們的smmu 的ste 表,很明顯只需要是1維數組就可以了,如下圖:

注意,這里ste采用線性表并不是真是由設備的數量來決定的,而是寫在smmu 的ID0寄存器中的,也就是配置好了的,對于華為鯤鵬上的smmu基本不采用這種結構;
對于設備數量較多的情況下,我們為了 smmu 更加的皮實點,可以采用兩層ste表的結構,如下圖:

這里的結構其實很類似我們的mmu的頁表了,在arm smmu v3 我們第一層的目錄desc的目錄結夠,大小采用8(STRTAB_SPLIT)位,也就是stream id的高8位,stream id剩下的低位全部用來尋址第二層真正的ste entry;
介紹完了 smmu 中管理設備的ste的表的兩種結構后,我們來看看這個ste表的具體結構是啥,里面有啥奧秘呢:

如上如所示,紅框中就是smmu中一個ste entry的全貌了,從紅框中能看出來,這個ste entry同時管理了stage1 和 stage2的數據結構;其中config是表示ste有關的配置項,這個不需要理解也不需要記憶,不知道的查一下smmuv3的手冊即可,里面的VMID是指虛擬機ID,這里我們重點關注一下S1ContextPtr和S2TTB。
首先我們來說S1ContextPtr:
這個S1ContextPtr指向的一個Context Descriptor的目錄結構,這張圖為了好理解只畫了一個,在我們arm中,如果沒有虛擬機參與的話,無論是cpu還是smmu地址翻譯都是從va->pa/iova->pa,我們稱之為stage1,也就是不涉及虛擬,只是一階段翻譯而已。
重要的CD表,讀到這里,你是不是會問一個問題,在smmu中我們為何要使用CD表呢?原因是這樣的,一個smmu可以管理很多設備,所以用ste表來區分每個設備的數據結構,每個設備一個ste表。那如果每個設備上跑了多個任務,這些任務又同時使用了不同的page table 的話,那咋管理呢?對不對?所以smmu 采用了CD表來管理每個page table;
看一看cd 表的查找規則:

先說另外一個重要的概念:SubstreamID(pasid),這個叫substreamid又稱之為pasid,也是非常簡單的概念,既然有表了,那也得有id來協助查找啊,所以就出來了這個id,從這里也可以看出來,道理都一樣,用了表了就有id 啊!

CD表,在smmu中也是可以是線性的或者兩級的,這個都是在smmu 寄存器中配置好了的,由smmu驅動來讀去,進行按對應的位進行分級,和ste表一樣的原理;
介紹了兩個基本的也重要的數據結構后我,smmu是在支持虛擬化的時候,可以同時進行stage1 和 stage2的翻譯的,如下圖所示:

當我們在虛擬機的guest中啟用smmu的時候,smmu是需要同時開啟stage1 和 stage2的,當然了,smmu 也是可以進行bypass的;
1.3:smmu的地址翻譯流程

如上圖,基本可以很明顯的概括出了一個外設請求 smmu 的地址翻譯的基本流程,當一個外設需要dma的物理地址的時候,開始請求smmu的地址翻譯,這時候外設給 smmu 3個比較重要的信息,分別是:streamid:協助smmu 找到管理外設的ste entry,subsreamid:當找到ste entry后,協助smmu找到對應的cd 表,通過這兩個id smmu 就可以找到對應的iopge table了,smmu找到page table 后結合外設提交過來的最后一個信息iova,即可開始進行地址翻譯;
smmu 也有tlb的緩存,smmu首先會根據當前cd表中存放的asid來查查tlb緩存中有沒有對應page table的緩存,這里其實和mmu找頁表的原理是一樣的,不過多解釋了,很簡單;
上圖中的地址翻譯還涉及到了stage2,這里不解釋了,smmu涉及到虛擬化的過程比較復雜,這個有機會再解釋;
2 smmu驅動與iommu框架
2.1:smmu v3驅動初始化
簡單的介紹了上面的兩個重要表以及smmu內部的基本的查找流程后,我們現在來看看在linux內核中,smmu驅動是如何完成初始化的過程,借著這個分析,我們看看smmu里的重要的幾種隊列:
smmuv3的在內核中的代碼路徑:drivers/iommu/arm-smmu-v3.c:

上面是smmu驅動中初始化流程的前半部分,從中可以很容易看出來,內核中每個smmu都有一個結構體struct arm_smmu_device來管理,實際上初始化的流程就是在填充著個結構。看上圖,首先就是從slub/slab中分配一個對象空間,隨后一個比較重要的是函數
arm_smmu_device_dt_probe 和 arm_smmu_device_acpi_probe,這倆函數會從dts中的smmu節點和acpi的smmu配置表中讀取一些smmu中斷等等屬性;
隨后調用函數platform_get_resource來從dts或者apci表中讀取smmu的寄存器的基地址,這個很重要,后續所有的初始化都是圍繞著個配置來的;

繼續看剩下的部分,開頭很容易看出來,要讀取smmu的幾個中斷號,smmu 硬件給軟件消息有隊列buffer,smmu硬件通過中斷的方式讓smmu驅動從隊列buffer中取消息,我們一一介紹:
第一個eventq中斷,smmu的一個隊列叫event隊列,這個隊列是給掛在smmu上的platform設備用的,當platform設備使用smmu翻譯dma 的iova的時候,如果發生了一場smmu會首先將異常的消息填到event隊列中,隨后上報一個eventq的中斷給 smmu 驅動,smmu驅動接到這個中斷后,開始執行中斷處理程序,從event隊列中將異常的消息讀出來,顯示異常;
另外一個priq中斷時給pri隊列用的,這個隊列是專門給掛在smmu上的pcie類型的設備用的,具體的流程其實是和event隊列是一樣的,這里不多解釋了;
最后一個是gerror中斷,如果smmu 在執行過程中,發生了不可恢復的嚴重錯誤,smmu會報告一個gerror中斷給smmu驅動,就不需要隊列了,因為本身嚴重錯誤了,直接中斷上來處理了;
完成了3個中斷初始化后(具體的中斷初始化映射流程,不在這里介紹,改天單獨寫個中斷章節介紹),smmu 驅動此時已經完成了smmu管理結構的分配,以及smmu配置的讀取,smmu的寄存器的映射,以及smmu中斷的初始化,這些都搞完后,smmu驅動開始讀取提前寫死在 smmu 寄存器中的各種配置,將配置bit位讀取出來放到struct arm_smm_device的數據結構中,函數arm_smmu_device_hw_probe函數就負責讀smmu的硬件寄存器;
當我們寄存器配置讀取完畢后,這時候我們知道了哪些信息呢?會有這個smmu支持二級ste還是一級的ste,二級的cd還有1級的cd,這個smmu支持的物理也大小,iova和pa的地址位數等等;這些頭填在arm_smmu_device的features的字段里面;
基本信息讀出來后,我們是不是可開始初始化數據結構了?答案是肯定的啦,看看函數arm_smmu_init_structures;

從上面的數據結構初始化的函數可以看出來,smmu驅動主要負責初始化兩種數據結構,一個strtab(stream table的簡寫),另外一個種是隊列的內存分配和初始化;我們首先來看看隊列的:

從上面可以看出來,smmu驅動主要初始化3個隊列:cmdq,evtq,priq;這里不再進一步解釋了,避免陷入函數細節分析;
最后我們來看看smmu 的strtab的初始化:

從上圖可以看出來,首先判斷我們需要初始化一級的還是二級的stream table,這里依據就是上面的硬件寄存器中讀取出來的;
我們首先看看函數arm_smmu_init_strtab_linear 函數:

對于線性的stream table表來說smmu 驅動會將調用dma alloc接口將stream table 需要的所有空間都一把分配完畢了,并且將所有的ste entry項都給預先的初始化成bypass的模式,具體的就不深入看了,比較簡單,設置bit;
隨后我們來看看函數:
arm_smmu_init_strtab_2lvl;
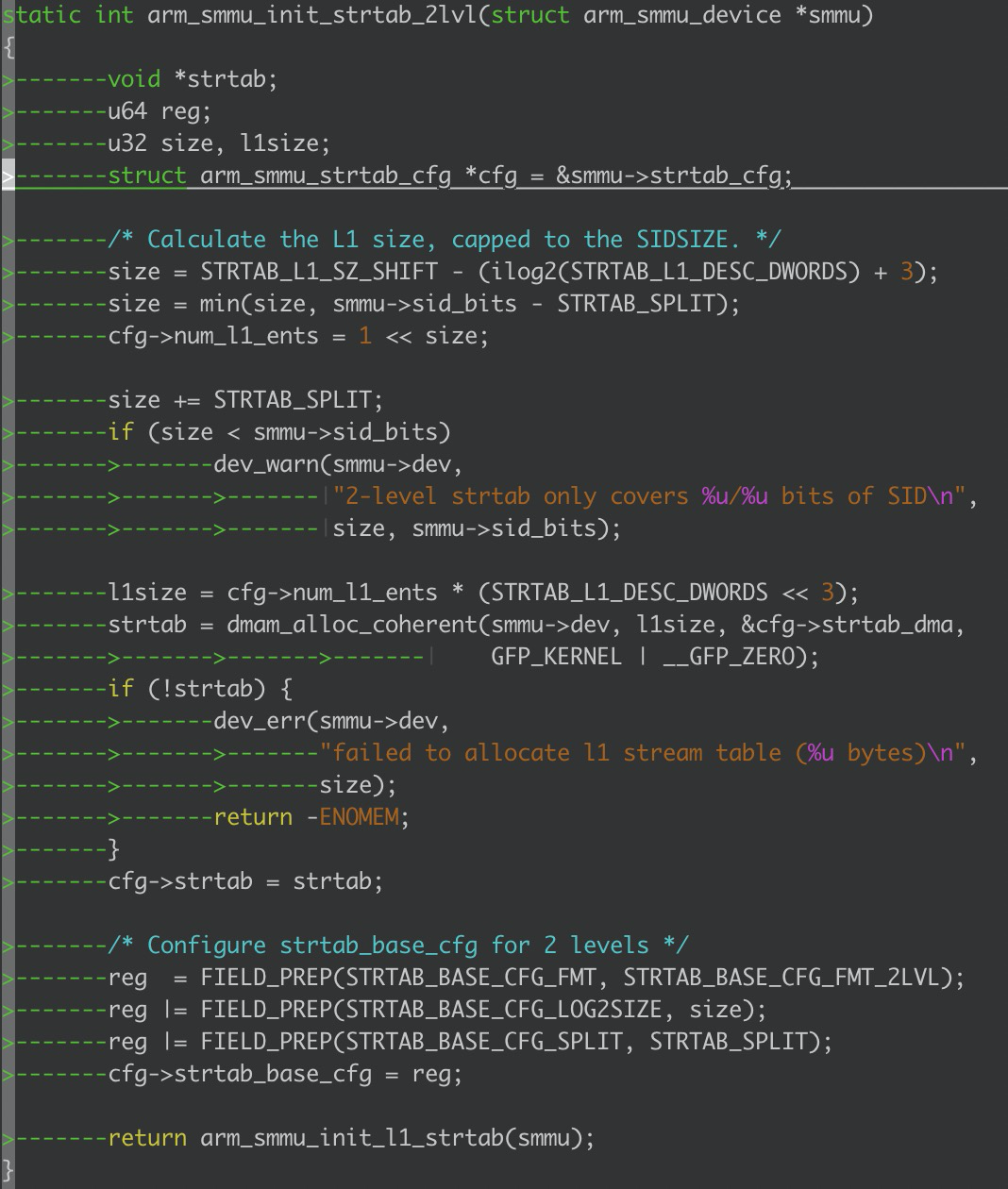
我們可以思考一個問題:我們真的需要將所有的ste entry都個創造出來嗎?很顯然,不是的,smmu驅動的初始化正是基于這種原理,僅僅只會初始化第一級的ste目錄項,其實這里就是類似頁表的初始化了也只是先初始化了目錄項;函數中dma alloc coherent就是負責分配第一級的目錄項的,分配的大小是多大呢?我們可以看一下有一個關鍵的宏STRTAB_SPLIT,這個宏目前在smmu驅動中是8位,也就是預先會分配2^8個目錄項,每個目錄項的大小是固定的;
我們可以看到里面還調用了一個函數arm_smmu_init_l1_strtab函數,這里就是我們空間分配完了,總該給這些目錄項給初始化一下吧,這里就不深入進去看了;
到此為止,我們已經將基本的數據結構初始化給簡要的講完了;我們接著看smmu驅動初始化的剩下的,見下圖:

上圖是smmu 驅動初始化的剩下的部分,我們可以看出來里面第一個函數是arm_smmu_device_reset,這個函數是干嘛的呢,我們前面是不是已經給這個smmu在內存中分配了幾個隊列和stream table的目錄項?那這些數據結構的基地址總該讓smmu知道吧?這個函數就是將這些基地址給放到smmu的控制寄存器中的;當前我們需要的東西給初始化完后,smmu驅動接下來就是將smmu的基本數據結構注冊到上層的iommu抽象框架里,讓iommu結構能夠調用到smmu,這個在后面再說。
2.2 smmu 與 iommu關系
2.2.1 兩者的結構關系
smmu 和 iommu 是何種關系呢?在我們的硬件體系中,能夠有能力完成設備iova 到 pa轉換的有很多,例如有intel iommu, amd的iommu ,arm的smmu等等,不一一枚舉了;那這些不同的硬件架構不會都作為一個獨立的子系統,所以,在linux 內核中 抽象了一層 iommu 層,由iommu層給各個外部設備驅動提供結構,隱藏底層的不同的架構;如圖所示:
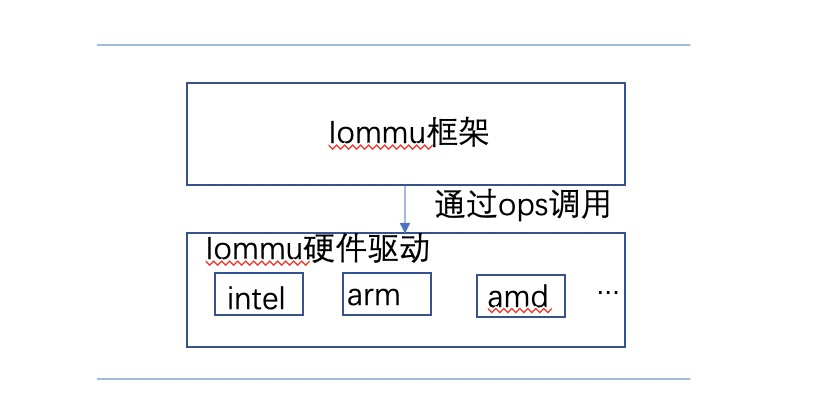
由上圖可以很明顯的看出來,各個架構的smmu驅動是如何使如何和iommu框架對接的,iommu框架通過不同架構的ops來調用到底層真正的驅動接口;
我們可以問自己一個問題:底層的驅動是如何對接到上層的?
接下來我們來看看進入內核代碼來幫我們解開疑惑;

如上圖是smmu 驅動初始化的最后一部分,對于底層的每一個smmu結構在iommu框架層中都一有一個唯一的一個結構體表示:struct iommu_device,上圖中函數iommu_device_register所完成的任務就是將我們所初始化好的iommu結構體給注冊到iommu層的鏈表中,統一管理起來;最后我們根據smmu所掛載的是pcie外設,還是platform外設,將和個smmu綁定到不同的總線類型上;
2.2.2 iommu的重要結構與ops
iommu 層通過ops來調用底層硬件驅動,我們來看看smmu v3硬件驅動提供了哪些ops call:

上圖就是smmu v3 硬件驅動提供的所有的調用函數;
既然到了iommu層,那我們也會涉及到兩種概念的管理,一種是設備如何管理,另外一種是smmu 提供的io page table如何管理;
為了分別管理,這兩種概念,iommu 框架提供了兩種結構體,一個是 struct iommu_domain 這個結構抽象出了一個domain的結構,用來代表底層的arm_smmu_domain,其實最核心的是管理這個domian所擁有的io page table。另外一個是sruct iommu_group這個結構是用來管理設備的,多個設備可以在一個iommu group中,以此來共享一個iopage table; 我們看一個網絡上的圖即可很明白的表明其中的關系:
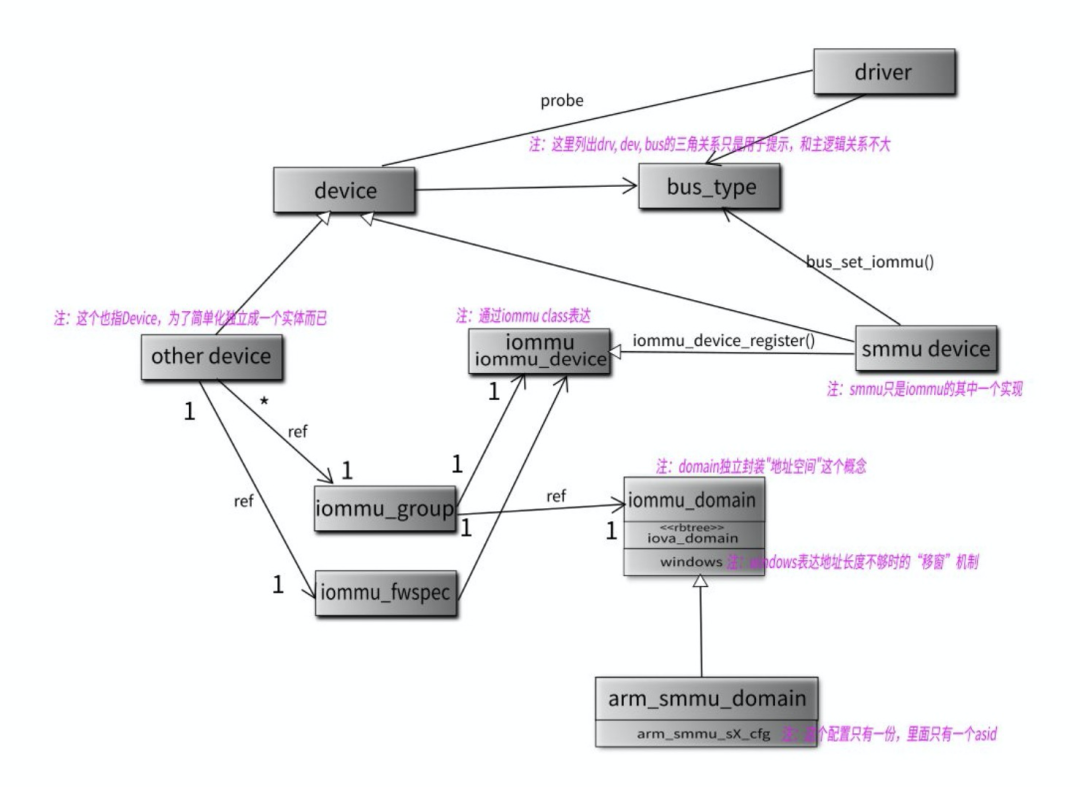
這張圖中很明顯的寫出來smmu domian和 iommu的domain的關系,以及iommu group的作用;不再過多解釋。
2.3 dma iova 與iommu
dma 和 iommu 息息相關,iommu的產生其實很大的原因就是避免dma的時候直接使用物理地址而導致的不安全性,所以就產生了iova, 我們在調用dma alloc的時候,首先在io 的地址空間中分配你一個iova, 然后在iommu所管理的頁表中做好iova 和dma alloc時候產生的物理地址進行映射;外設在進行dma的時候,只需要使用iova即可完成dma動作;
那我們如何完成dma alloc的時候iova到pa的映射的呢?
dma_alloc ->__iommu_alloc_attrs

在__iommu_alloc_attrs函數中調用iommu_dma_alloc函數來完成iova和pa的分配與映射;
iommu_dma_alloc->__iommu_dma_alloc_pages,
首先會調用者個函數來完成物理頁面的分配:

函數__iommu_dma_alloc_pages中完成的任務是頁面分配,iommu_dma_alloc_iova完成的就是iova的分配,最后iommu_map_sg即可完成iova到pa的映射;
linux 采用rb tree來管理每一段的iova區間,這其實和我們的虛擬內存的分配是類似的,我們的vma的管理也是這樣的;
我們接下來在來看看iova的釋放過程,這個釋放的過程,我們是可以看到看到strict 個 non-strict模式的最核心的區別的:

老規矩,直接擼代碼,我們看到dma的釋放流程也是很簡單的,首先將iova和pa進行解映射處理,然后將iova結構給釋放掉;
看圖中解映射的部分就是在iommu_unmap_fast流程中處理的就是調用iommu的unmap然后通過ops 調用到arm smmu v3驅動的 unmap函數:__iommu_dma_unmap->iommu_unmap_fast->(ops->unmap: arm_smmu_unmap)->arm_lpae_unmap;
我們進入函數arm_lpae_unmap中看看是干啥的,見下圖:

這個函數采用遞歸的方式來查找io page table的最后一項,當找到的時候,我們可注意看代碼行613~622行,其中613~620行是當我們的iommu采用默認的non strict模式的時候,我們是不用立馬對tlb進行無效化的;但是當我們采用strict模式的時候,我們還是會將tlb給刷新一下,調用函數io_pgtable_tlb_add_flush給smmu寫入一個tlb無效化的指令;
那我們采用non-strict模式的時候是如何刷新tlb的呢?秘密就在函數iommu_dma_free_iova函數中見下圖:
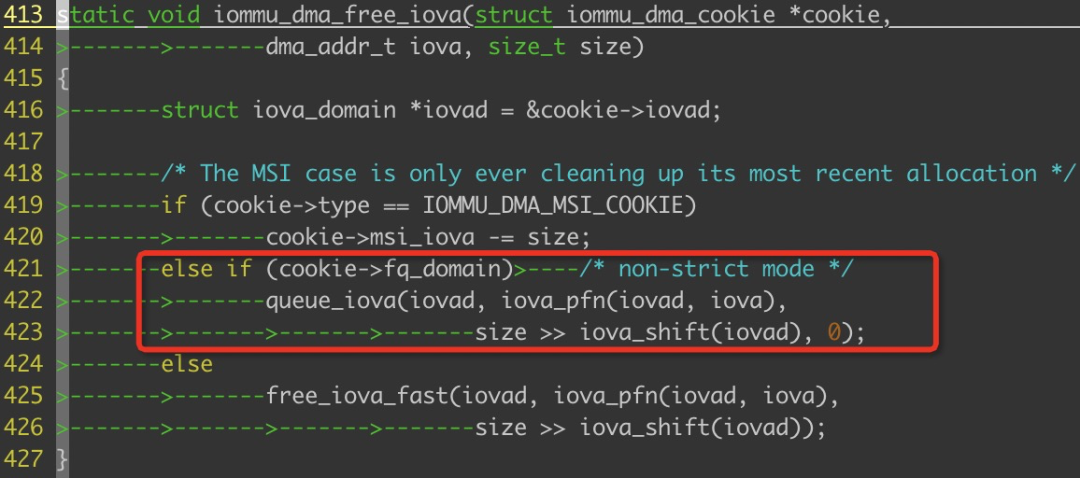
我們可以看到,如果采用non-strict的模式的時候,我們是放到一個隊列中的,當我們的隊列滿的時候,會調用函數iovad->flush_cb,
這個函數指針,最終會調用到函數:iommu_dma_flush_iotlb_all,來進行全局的tlb的刷新,smmu無需執行太多的指令了;
2.4 smmu和iommu的bypass
方式一:將iommu 給徹底給bypass掉,linux 提供了iommu.passthrough command line的選項,這個選項配置上后,dma 默認不會走iommu,而是走傳統的swiotlb方式的dma;
方式二:smmu v3的驅動默認支持驅動參數配置,disable_bypass,在系統中是默認關閉bypass的,我們可以通過這個來將某個smmu給bypass掉;
方式三:acpi 或者dts中不配置相應的smmu節點,比較粗暴的辦法。
3.smmu 的PMCG
ARM的SMMU提供了性能相關的統計寄存器(Performance Monitor Counter Groups - PMCG),首先要確定使用的系統里有arm_smmuv3_pmu這個模塊,或者它已經被編譯進內核。
這個模塊的代碼在內核目錄kernel/drivers/perf/arm_smmuv3_pmu.c,內核配置是: CONFIG_ARM_SMMU_V3_PMU;
原文標題:ARM SMMU的原理與IOMMU
文章出處:【微信公眾號:Linuxer】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
ARM
+關注
關注
134文章
9057瀏覽量
366882
發布評論請先 登錄
相關推薦
Arm成功將Arm KleidiAI軟件庫集成到騰訊自研的Angel 機器學習框架
Arm全面設計助力Arm架構生態發展
Arm如何賦能無處不在的AI
ARM 主板:計算的未來

Arm推出AI優化的Arm終端CSS以及新的Arm Kleidi軟件

Arm新Arm Neoverse計算子系統(CSS):Arm Neoverse CSS V3和Arm Neoverse CSS N3

Arm Helium技術誕生的由來 為何不直接采用Neon?
Arm v9芯片新架構揭秘






 工商網監
工商網監
評論