") 使用Softmax的信息來教學(xué) —— 知識(shí)蒸餾
使用Softmax的信息來教學(xué) —— 知識(shí)蒸餾
導(dǎo)讀
從各個(gè)層次給大家講解模型的知識(shí)蒸餾的相關(guān)內(nèi)容,并通過實(shí)際的代碼給大家進(jìn)行演示。
公眾號(hào)后臺(tái)回復(fù)“模型蒸餾”,下載已打包好的代碼。
本報(bào)告討論了非常厲害模型優(yōu)化技術(shù) —— 知識(shí)蒸餾,并給大家過了一遍相關(guān)的TensorFlow的代碼。
“模型集成是一個(gè)相當(dāng)有保證的方法,可以獲得2%的準(zhǔn)確性。“ —— Andrej Karpathy
我絕對(duì)同意!然而,部署重量級(jí)模型的集成在許多情況下并不總是可行的。有時(shí),你的單個(gè)模型可能太大(例如GPT-3),以至于通常不可能將其部署到資源受限的環(huán)境中。這就是為什么我們一直在研究一些模型優(yōu)化方法 ——量化和剪枝。在這個(gè)報(bào)告中,我們將討論一個(gè)非常厲害的模型優(yōu)化技術(shù) —— 知識(shí)蒸餾。
Softmax告訴了我們什么?
當(dāng)處理一個(gè)分類問題時(shí),使用softmax作為神經(jīng)網(wǎng)絡(luò)的最后一個(gè)激活單元是非常典型的用法。這是為什么呢?因?yàn)閟oftmax函數(shù)接受一組logit為輸入并輸出離散類別上的概率分布。比如,手寫數(shù)字識(shí)別中,神經(jīng)網(wǎng)絡(luò)可能有較高的置信度認(rèn)為圖像為1。不過,也有輕微的可能性認(rèn)為圖像為7。如果我們只處理像[1,0]這樣的獨(dú)熱編碼標(biāo)簽(其中1和0分別是圖像為1和7的概率),那么這些信息就無法獲得。
人類已經(jīng)很好地利用了這種相對(duì)關(guān)系。更多的例子包括,長得很像貓的狗,棕紅色的,貓一樣的老虎等等。正如Hinton等人所認(rèn)為的
一輛寶馬被誤認(rèn)為是一輛垃圾車的可能性很小,但被誤認(rèn)為是一個(gè)胡蘿卜的可能性仍然要高很多倍。
這些知識(shí)可以幫助我們?cè)诟鞣N情況下進(jìn)行極好的概括。這個(gè)思考過程幫助我們更深入地了解我們的模型對(duì)輸入數(shù)據(jù)的想法。它應(yīng)該與我們考慮輸入數(shù)據(jù)的方式一致。
所以,現(xiàn)在該做什么?一個(gè)迫在眉睫的問題可能會(huì)突然出現(xiàn)在我們的腦海中 —— 我們?cè)谏窠?jīng)網(wǎng)絡(luò)中使用這些知識(shí)的最佳方式是什么?讓我們?cè)谙乱还?jié)中找出答案。
使用Softmax的信息來教學(xué) —— 知識(shí)蒸餾
softmax信息比獨(dú)熱編碼標(biāo)簽更有用。在這個(gè)階段,我們可以得到:
訓(xùn)練數(shù)據(jù)
訓(xùn)練好的神經(jīng)網(wǎng)絡(luò)在測(cè)試數(shù)據(jù)上表現(xiàn)良好
我們現(xiàn)在感興趣的是使用我們訓(xùn)練過的網(wǎng)絡(luò)產(chǎn)生的輸出概率。
考慮教人去認(rèn)識(shí)MNIST數(shù)據(jù)集的英文數(shù)字。你的學(xué)生可能會(huì)問 —— 那個(gè)看起來像7嗎?如果是這樣的話,這絕對(duì)是個(gè)好消息,因?yàn)槟愕膶W(xué)生,肯定知道1和7是什么樣子。作為一名教師,你能夠把你的數(shù)字知識(shí)傳授給你的學(xué)生。這種想法也有可能擴(kuò)展到神經(jīng)網(wǎng)絡(luò)。
知識(shí)蒸餾的高層機(jī)制
所以,這是一個(gè)高層次的方法:
訓(xùn)練一個(gè)在數(shù)據(jù)集上表現(xiàn)良好神經(jīng)網(wǎng)絡(luò)。這個(gè)網(wǎng)絡(luò)就是“教師”模型。
使用教師模型在相同的數(shù)據(jù)集上訓(xùn)練一個(gè)學(xué)生模型。這里的問題是,學(xué)生模型的大小應(yīng)該比老師的小得多。
本工作流程簡(jiǎn)要闡述了知識(shí)蒸餾的思想。
為什么要小?這不是我們想要的嗎?將一個(gè)輕量級(jí)模型部署到生產(chǎn)環(huán)境中,從而達(dá)到足夠的性能。
用圖像分類的例子來學(xué)習(xí)
對(duì)于一個(gè)圖像分類的例子,我們可以擴(kuò)展前面的高層思想:
訓(xùn)練一個(gè)在圖像數(shù)據(jù)集上表現(xiàn)良好的教師模型。在這里,交叉熵?fù)p失將根據(jù)數(shù)據(jù)集中的真實(shí)標(biāo)簽計(jì)算。
在相同的數(shù)據(jù)集上訓(xùn)練一個(gè)較小的學(xué)生模型,但是使用來自教師模型(softmax輸出)的預(yù)測(cè)作為ground-truth標(biāo)簽。這些softmax輸出稱為軟標(biāo)簽。稍后會(huì)有更詳細(xì)的介紹。
我們?yōu)槭裁匆密洏?biāo)簽來訓(xùn)練學(xué)生模型?
請(qǐng)記住,在容量方面,我們的學(xué)生模型比教師模型要小。因此,如果你的數(shù)據(jù)集足夠復(fù)雜,那么較小的student模型可能不太適合捕捉訓(xùn)練目標(biāo)所需的隱藏表示。我們?cè)谲洏?biāo)簽上訓(xùn)練學(xué)生模型來彌補(bǔ)這一點(diǎn),它提供了比獨(dú)熱編碼標(biāo)簽更有意義的信息。在某種意義上,我們通過暴露一些訓(xùn)練數(shù)據(jù)集來訓(xùn)練學(xué)生模型來模仿教師模型的輸出。
希望這能讓你們對(duì)知識(shí)蒸餾有一個(gè)直觀的理解。在下一節(jié)中,我們將更詳細(xì)地了解學(xué)生模型的訓(xùn)練機(jī)制。
知識(shí)蒸餾中的損失函數(shù)
為了訓(xùn)練學(xué)生模型,我們?nèi)匀豢梢允褂媒處熌P偷能洏?biāo)簽以及學(xué)生模型的預(yù)測(cè)來計(jì)算常規(guī)交叉熵?fù)p失。學(xué)生模型很有可能對(duì)許多輸入數(shù)據(jù)點(diǎn)都有信心,并且它會(huì)預(yù)測(cè)出像下面這樣的概率分布:
高置信度的預(yù)測(cè)
擴(kuò)展Softmax
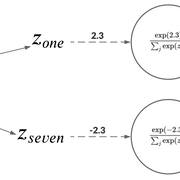
這些弱概率的問題是,它們沒有捕捉到學(xué)生模型有效學(xué)習(xí)所需的信息。例如,如果概率分布像[0.99, 0.01],幾乎不可能傳遞圖像具有數(shù)字7的特征的知識(shí)。
Hinton等人解決這個(gè)問題的方法是,在將原始logits傳遞給softmax之前,將教師模型的原始logits按一定的溫度進(jìn)行縮放。這樣,就會(huì)在可用的類標(biāo)簽中得到更廣泛的分布。然后用同樣的溫度用于訓(xùn)練學(xué)生模型。
我們可以把學(xué)生模型的修正損失函數(shù)寫成這個(gè)方程的形式:
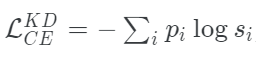
其中,pi是教師模型得到軟概率分布,si的表達(dá)式為: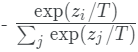
defget_kd_loss(student_logits,teacher_logits, true_labels,temperature, alpha,beta): teacher_probs=tf.nn.softmax(teacher_logits/temperature) kd_loss=tf.keras.losses.categorical_crossentropy( teacher_probs,student_logits/temperature, from_logits=True) returnkd_loss
使用擴(kuò)展Softmax來合并硬標(biāo)簽
Hinton等人還探索了在真實(shí)標(biāo)簽(通常是獨(dú)熱編碼)和學(xué)生模型的預(yù)測(cè)之間使用傳統(tǒng)交叉熵?fù)p失的想法。當(dāng)訓(xùn)練數(shù)據(jù)集很小,并且軟標(biāo)簽沒有足夠的信號(hào)供學(xué)生模型采集時(shí),這一點(diǎn)尤其有用。
當(dāng)它與擴(kuò)展的softmax相結(jié)合時(shí),這種方法的工作效果明顯更好,而整體損失函數(shù)成為兩者之間的加權(quán)平均。
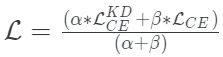
defget_kd_loss(student_logits,teacher_logits, true_labels,temperature, alpha,beta): teacher_probs=tf.nn.softmax(teacher_logits/temperature) kd_loss=tf.keras.losses.categorical_crossentropy( teacher_probs,student_logits/temperature, from_logits=True) ce_loss=tf.keras.losses.sparse_categorical_crossentropy( true_labels,student_logits,from_logits=True) total_loss=(alpha*kd_loss)+(beta*ce_loss) returntotal_loss/(alpha+beta)
建議β的權(quán)重小于α。
在原始Logits上進(jìn)行操作
Caruana等人操作原始logits,而不是softmax值。這個(gè)工作流程如下:
這部分保持相同 —— 訓(xùn)練一個(gè)教師模型。這里交叉熵?fù)p失將根據(jù)數(shù)據(jù)集中的真實(shí)標(biāo)簽計(jì)算。
現(xiàn)在,為了訓(xùn)練學(xué)生模型,訓(xùn)練目標(biāo)變成分別最小化來自教師和學(xué)生模型的原始對(duì)數(shù)之間的平均平方誤差。

mse=tf.keras.losses.MeanSquaredError() defmse_kd_loss(teacher_logits,student_logits): returnmse(teacher_logits,student_logits)
使用這個(gè)損失函數(shù)的一個(gè)潛在缺點(diǎn)是它是無界的。原始logits可以捕獲噪聲,而一個(gè)小模型可能無法很好的擬合。這就是為什么為了使這個(gè)損失函數(shù)很好地適合蒸餾狀態(tài),學(xué)生模型需要更大一點(diǎn)。
Tang等人探索了在兩個(gè)損失之間插值的想法:擴(kuò)展softmax和MSE損失。數(shù)學(xué)上,它看起來是這樣的:
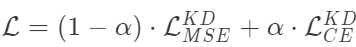
根據(jù)經(jīng)驗(yàn),他們發(fā)現(xiàn)當(dāng)α = 0時(shí),(在NLP任務(wù)上)可以獲得最佳的性能。
如果你在這一點(diǎn)上感到有點(diǎn)不知怎么辦,不要擔(dān)心。希望通過代碼,事情會(huì)變得清楚。
一些訓(xùn)練方法
在本節(jié)中,我將向你提供一些在使用知識(shí)蒸餾時(shí)可以考慮的訓(xùn)練方法。
使用數(shù)據(jù)增強(qiáng)
他們?cè)贜LP數(shù)據(jù)集上展示了這個(gè)想法,但這也適用于其他領(lǐng)域。為了更好地指導(dǎo)學(xué)生模型訓(xùn)練,使用數(shù)據(jù)增強(qiáng)會(huì)有幫助,特別是當(dāng)你處理的數(shù)據(jù)較少的時(shí)候。因?yàn)槲覀兺ǔ13謱W(xué)生模型比教師模型小得多,所以我們希望學(xué)生模型能夠獲得更多不同的數(shù)據(jù),從而更好地捕捉領(lǐng)域知識(shí)。
使用標(biāo)記的和未標(biāo)記的數(shù)據(jù)訓(xùn)練學(xué)生模型
在像Noisy Student Training和SimCLRV2這樣的文章中,作者在訓(xùn)練學(xué)生模型時(shí)使用了額外的未標(biāo)記數(shù)據(jù)。因此,你將使用你的teacher模型來生成未標(biāo)記數(shù)據(jù)集上的ground-truth分布。這在很大程度上有助于提高模型的可泛化性。這種方法只有在你所處理的數(shù)據(jù)集中有未標(biāo)記數(shù)據(jù)可用時(shí)才可行。有時(shí),情況可能并非如此(例如,醫(yī)療保健)。Xie等人探索了數(shù)據(jù)平衡和數(shù)據(jù)過濾等技術(shù),以緩解在訓(xùn)練學(xué)生模型時(shí)合并未標(biāo)記數(shù)據(jù)可能出現(xiàn)的問題。
在訓(xùn)練教師模型時(shí)不要使用標(biāo)簽平滑
標(biāo)簽平滑是一種技術(shù),用來放松由模型產(chǎn)生的高可信度預(yù)測(cè)。它有助于減少過擬合,但不建議在訓(xùn)練教師模型時(shí)使用標(biāo)簽平滑,因?yàn)闊o論如何,它的logits是按一定的溫度縮放的。因此,一般不推薦在知識(shí)蒸餾的情況下使用標(biāo)簽平滑。
使用更高的溫度值
Hinton等人建議使用更高的溫度值來soften教師模型預(yù)測(cè)的分布,這樣軟標(biāo)簽可以為學(xué)生模型提供更多的信息。這在處理小型數(shù)據(jù)集時(shí)特別有用。對(duì)于更大的數(shù)據(jù)集,信息可以通過訓(xùn)練樣本的數(shù)量來獲得。
實(shí)驗(yàn)結(jié)果
讓我們先回顧一下實(shí)驗(yàn)設(shè)置。我在實(shí)驗(yàn)中使用了Flowers數(shù)據(jù)集。除非另外指定,我使用以下配置:
我使用MobileNetV2作為基本模型進(jìn)行微調(diào),學(xué)習(xí)速度設(shè)置為1e-5,Adam作為優(yōu)化器。
我們將τ設(shè)置為5。
α = 0.9,β = 0.1。
對(duì)于學(xué)生模型,使用下面這個(gè)簡(jiǎn)單的結(jié)構(gòu):
Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 222, 222, 64) 1792 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 55, 55, 64) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 53, 53, 128) 73856 _________________________________________________________________ global_average_pooling2d_3 ( (None, 128) 0 _________________________________________________________________ dense_3 (Dense) (None, 512) 66048 _________________________________________________________________ dense_4 (Dense) (None, 5) 2565 =================================================================
在訓(xùn)練學(xué)生模型時(shí),我使用Adam作為優(yōu)化器,學(xué)習(xí)速度為1e-2。
在使用數(shù)據(jù)增強(qiáng)訓(xùn)練student模型的過程中,我使用了與上面提到的相同的默認(rèn)超參數(shù)的加權(quán)平均損失。
學(xué)生模型基線
為了使性能比較公平,我們還從頭開始訓(xùn)練淺的CNN并觀察它的性能。注意,在本例中,我使用Adam作為優(yōu)化器,學(xué)習(xí)速率為1e-3。
訓(xùn)練循環(huán)
在看到結(jié)果之前,我想說明一下訓(xùn)練循環(huán),以及如何在經(jīng)典的model.fit()調(diào)用中包裝它。這就是訓(xùn)練循環(huán)的樣子:
deftrain_step(self,data): images,labels=data teacher_logits=self.trained_teacher(images) withtf.GradientTape()astape: student_logits=self.student(images) loss=get_kd_loss(teacher_logits,student_logits) gradients=tape.gradient(loss,self.student.trainable_variables) self.optimizer.apply_gradients(zip(gradients,self.student.trainable_variables)) train_loss.update_state(loss) train_acc.update_state(labels,tf.nn.softmax(student_logits)) t_loss,t_acc=train_loss.result(),train_acc.result() train_loss.reset_states(),train_acc.reset_states() return{"loss":t_loss,"accuracy":t_acc}
如果你已經(jīng)熟悉了如何在TensorFlow 2中定制一個(gè)訓(xùn)練循環(huán),那么train_step()函數(shù)應(yīng)該是一個(gè)容易閱讀的函數(shù)。注意get_kd_loss() 函數(shù)。這可以是我們之前討論過的任何損失函數(shù)。我們?cè)谶@里使用的是一個(gè)訓(xùn)練過的教師模型,這個(gè)模型我們?cè)谇懊孢M(jìn)行了微調(diào)。通過這個(gè)訓(xùn)練循環(huán),我們可以創(chuàng)建一個(gè)可以通過.fit()調(diào)用進(jìn)行訓(xùn)練完整模型。
首先,創(chuàng)建一個(gè)擴(kuò)展tf.keras.Model的類。
classStudent(tf.keras.Model): def__init__(self,trained_teacher,student): super(Student,self).__init__() self.trained_teacher=trained_teacher self.student=student
當(dāng)你擴(kuò)展tf.keras.Model 類的時(shí)候,可以將自定義的訓(xùn)練邏輯放到train_step()函數(shù)中(由類提供)。所以,從整體上看,Student類應(yīng)該是這樣的:
classStudent(tf.keras.Model): def__init__(self,trained_teacher,student): super(Student,self).__init__() self.trained_teacher=trained_teacher self.student=student deftrain_step(self,data): images,labels=data teacher_logits=self.trained_teacher(images) withtf.GradientTape()astape: student_logits=self.student(images) loss=get_kd_loss(teacher_logits,student_logits) gradients=tape.gradient(loss,self.student.trainable_variables) self.optimizer.apply_gradients(zip(gradients,self.student.trainable_variables)) train_loss.update_state(loss) train_acc.update_state(labels,tf.nn.softmax(student_logits)) t_loss,t_acc=train_loss.result(),train_acc.result() train_loss.reset_states(),train_acc.reset_states() return{"train_loss":t_loss,"train_accuracy":t_acc}
你甚至可以編寫一個(gè)test_step來自定義模型的評(píng)估行為。我們的模型現(xiàn)在可以用以下方式訓(xùn)練:
student=Student(teacher_model,get_student_model()) optimizer=tf.keras.optimizers.Adam(learning_rate=0.01) student.compile(optimizer) student.fit(train_ds, validation_data=validation_ds, epochs=10)
這種方法的一個(gè)潛在優(yōu)勢(shì)是可以很容易地合并其他功能,比如分布式訓(xùn)練、自定義回調(diào)、混合精度等等。
使用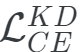 訓(xùn)練學(xué)生模型
訓(xùn)練學(xué)生模型
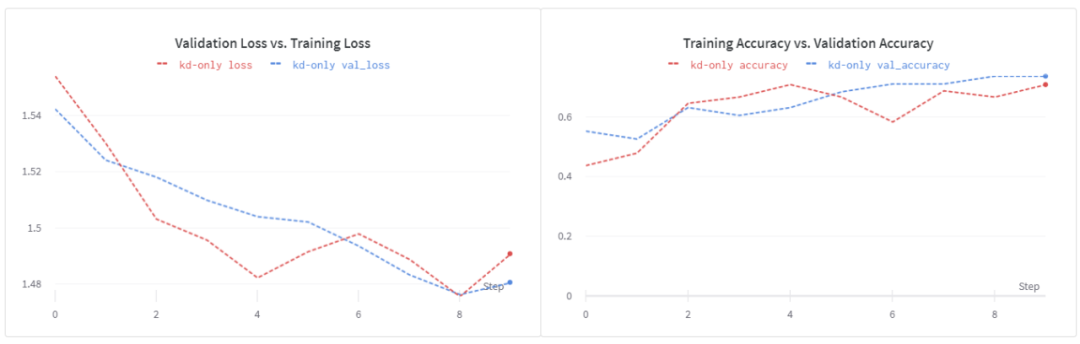
用這個(gè)損失函數(shù)訓(xùn)練我們的淺層學(xué)生模型,我們得到~74%的驗(yàn)證精度。我們看到,在epochs 8之后,損失開始增加。這表明,加強(qiáng)正則化可能會(huì)有所幫助。另外,請(qǐng)注意,超參數(shù)調(diào)優(yōu)過程在這里有重大影響。在我的實(shí)驗(yàn)中,我沒有做嚴(yán)格的超參數(shù)調(diào)優(yōu)。為了更快地進(jìn)行實(shí)驗(yàn),我縮短了訓(xùn)練時(shí)間。
使用
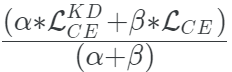
訓(xùn)練學(xué)生模型
現(xiàn)在讓我們看看在蒸餾訓(xùn)練目標(biāo)中加入ground truth標(biāo)簽是否有幫助。在β = 0.1和α = 0.1的情況下,我們得到了大約71%的驗(yàn)證準(zhǔn)確性。再次表明,更強(qiáng)的正則化和更長的訓(xùn)練時(shí)間會(huì)有所幫助。
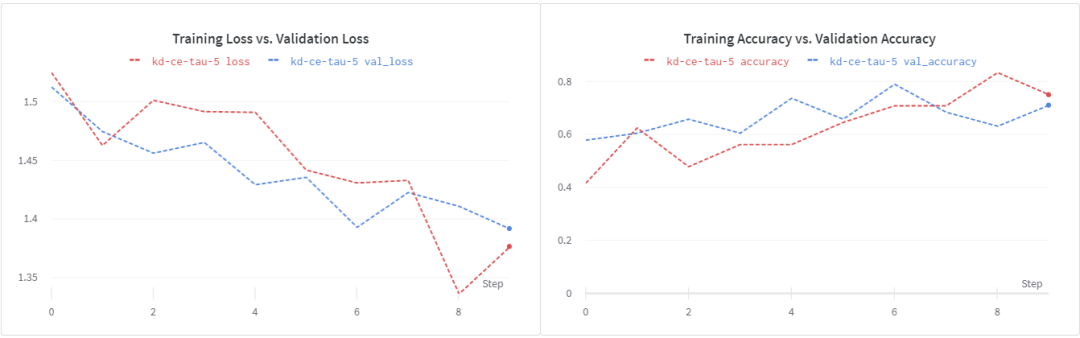
使用 訓(xùn)練學(xué)生模型
訓(xùn)練學(xué)生模型
使用了MSE的損失,我們可以看到驗(yàn)證精度大幅下降到~56%。同樣的損失也出現(xiàn)了類似的情況,這表明需要進(jìn)行正則化。
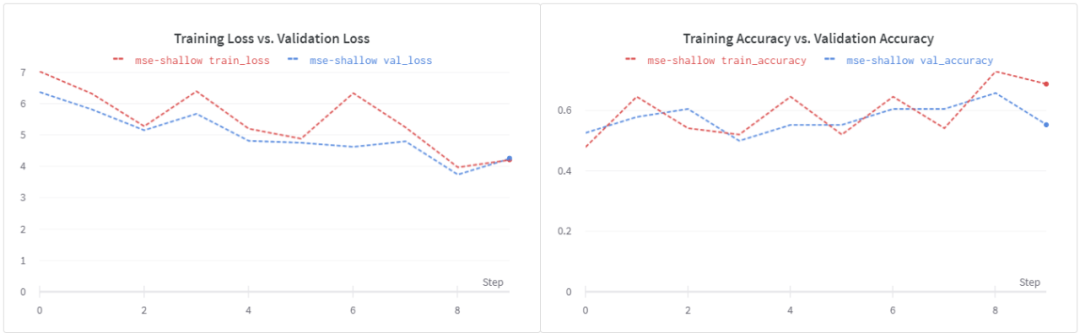
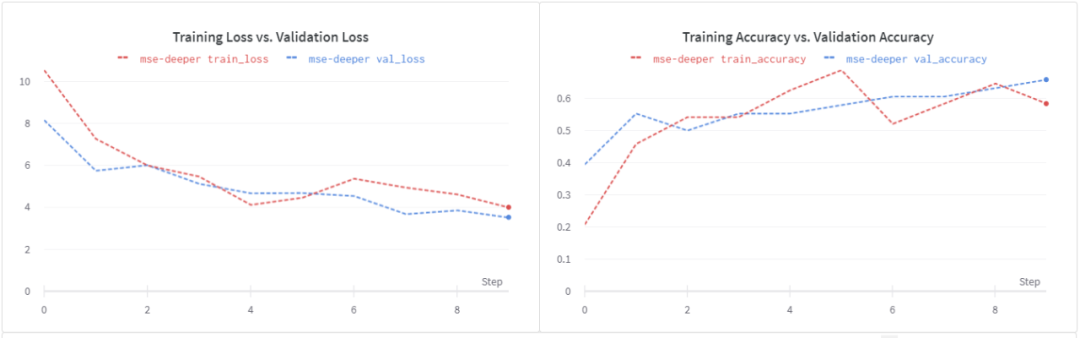
請(qǐng)注意,這個(gè)損失函數(shù)是無界的,我們的淺學(xué)生模型可能無法處理隨之而來的噪音。讓我們嘗試一個(gè)更深入的學(xué)生模型。
在訓(xùn)練學(xué)生模型的時(shí)候使用數(shù)據(jù)增強(qiáng)
如前所述,學(xué)生模式比教師模式的容量更小。在處理較少的數(shù)據(jù)時(shí),數(shù)據(jù)增強(qiáng)可以幫助訓(xùn)練學(xué)生模型。我們驗(yàn)證一下。
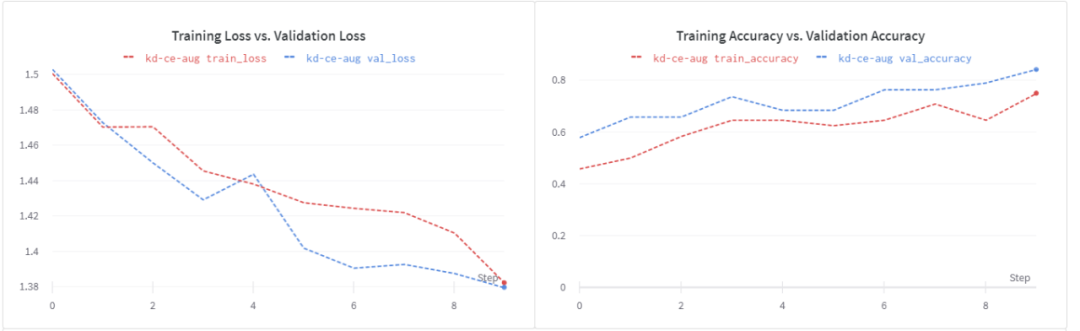
數(shù)據(jù)增加的好處是非常明顯的:
我們有一個(gè)更好的損失曲線。
驗(yàn)證精度提高到84%。
溫度(τ)的影響
在這個(gè)實(shí)驗(yàn)中,我們研究溫度對(duì)學(xué)生模型的影響。在這個(gè)設(shè)置中,我使用了相同的淺層CNN。
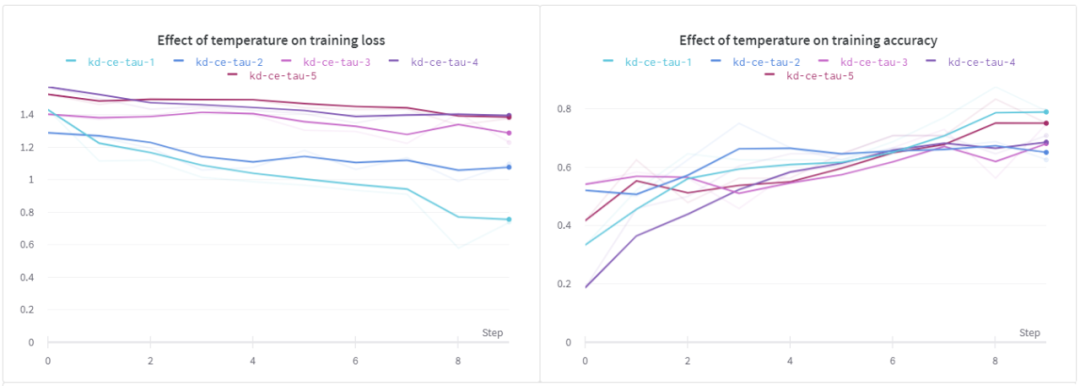
從上面的結(jié)果可以看出,當(dāng)τ為1時(shí),訓(xùn)練損失和訓(xùn)練精度均優(yōu)于其它方法。對(duì)于驗(yàn)證損失,我們可以看到類似的行為,但是在所有不同的溫度下,驗(yàn)證的準(zhǔn)確性似乎幾乎是相同的。
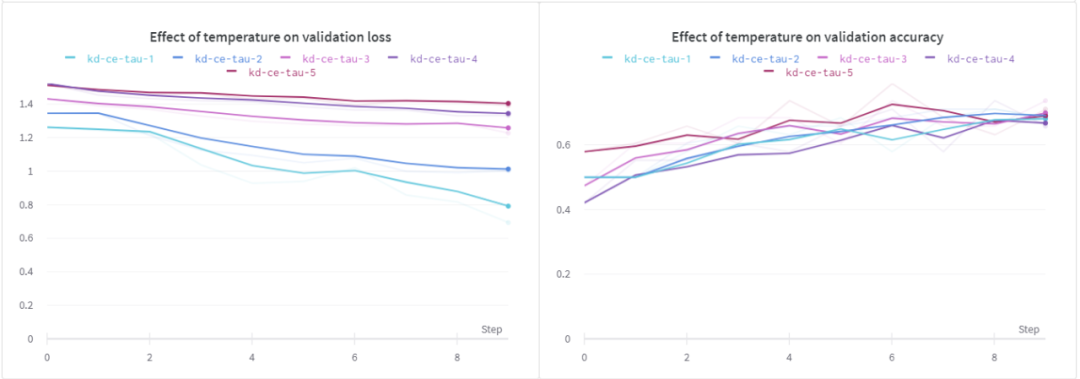
最后,我想研究下微調(diào)基線模是否對(duì)學(xué)生模型有顯著影響。
基線模型調(diào)優(yōu)的效果
在這次實(shí)驗(yàn)中,我選擇了 EfficientNet B0作為基礎(chǔ)模型。讓我們先來看看我用它得到的微調(diào)結(jié)果。注意,如前所述,所有其他超參數(shù)都保持其默認(rèn)值。
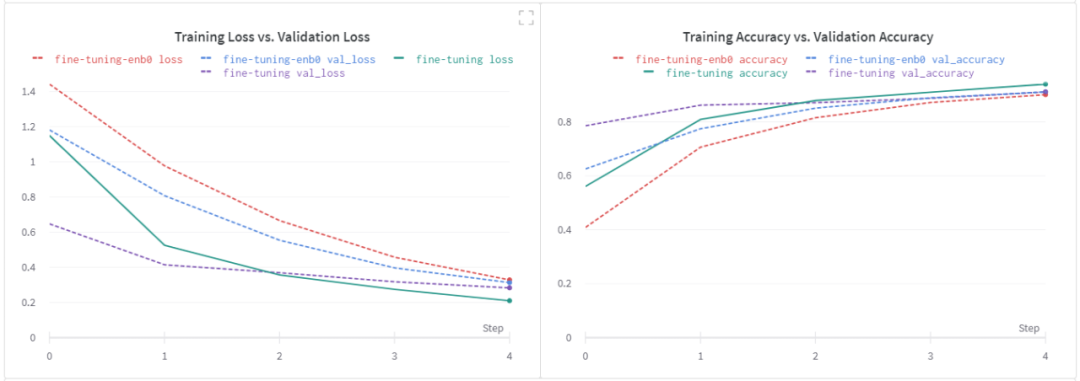
我們?cè)谖⒄{(diào)步驟中沒有看到任何顯著的改進(jìn)。我想再次強(qiáng)調(diào),我沒有進(jìn)行嚴(yán)格的超參數(shù)調(diào)優(yōu)實(shí)驗(yàn)。基于我從EfficientNet B0得到的邊際改進(jìn),我決定在以后的某個(gè)時(shí)間點(diǎn)進(jìn)行進(jìn)一步的實(shí)驗(yàn)。
第一行對(duì)應(yīng)的是用加權(quán)平均損失訓(xùn)練的默認(rèn)student model,其他行分別對(duì)應(yīng)EfficientNet B0和MobileNetV2。注意,我沒有包括在訓(xùn)練student模型時(shí)通過使用數(shù)據(jù)增強(qiáng)而得到的結(jié)果。
知識(shí)蒸餾的一個(gè)好處是,它與其他模型優(yōu)化技術(shù)(如量化和修剪)無縫集成。所以,作為一個(gè)有趣的實(shí)驗(yàn),我鼓勵(lì)你們自己嘗試一下。
總結(jié)
知識(shí)蒸餾是一種非常有前途的技術(shù),特別適合于用于部署的目的。它的一個(gè)優(yōu)點(diǎn)是,它可以與量化和剪枝非常無縫地結(jié)合在一起,從而在不影響精度的前提下進(jìn)一步減小生產(chǎn)模型的尺寸。
責(zé)任編輯:lq
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4762瀏覽量
100540 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1205瀏覽量
24644 -
Softmax
+關(guān)注
關(guān)注
0文章
9瀏覽量
2500
原文標(biāo)題:神經(jīng)網(wǎng)絡(luò)中的蒸餾技術(shù),從Softmax開始說起
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
2024全國高校電子信息類專業(yè)課程實(shí)驗(yàn)教學(xué)案例設(shè)計(jì)競(jìng)賽圓滿結(jié)束
武漢傳媒學(xué)院聯(lián)合創(chuàng)龍教儀建設(shè)DSP教學(xué)實(shí)驗(yàn)箱,基于DSP C6000平臺(tái)搭建
荊州學(xué)院聯(lián)合創(chuàng)龍教儀建設(shè)DSP教學(xué)實(shí)驗(yàn)箱案例分享
訊維AI教學(xué)分析系統(tǒng)的應(yīng)用提升整體教學(xué)質(zhì)量
SolidWorks教育版:豐富的教學(xué)資源
逆變器電池用蒸餾水理由,金屬觸點(diǎn)完全浸沒

高校嵌入式教學(xué)實(shí)驗(yàn)箱,開啟智慧教學(xué)新篇章

搭配100教學(xué)實(shí)驗(yàn)案例,輕松解決老師備課難題!
MR混合現(xiàn)實(shí)情景實(shí)訓(xùn)教學(xué)系統(tǒng)開發(fā)
普源精電支持的RIGOL杯全國高校電子信息類專業(yè)課程實(shí)驗(yàn)教學(xué)案例設(shè)計(jì)競(jìng)賽上榜!
學(xué)校教學(xué)選擇SOLIDWORKS教育版的原因
MR混合現(xiàn)實(shí)情景實(shí)訓(xùn)教學(xué)系統(tǒng)在軍事專業(yè)課堂上的應(yīng)用
帕克西AR實(shí)訓(xùn)教學(xué)解決方案:AR技術(shù)在工業(yè)領(lǐng)域的廣闊應(yīng)用前景
OneFlow Softmax算子源碼解讀之BlockSoftmax
OneFlow Softmax算子源碼解讀之WarpSoftmax





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論