 圖神經網絡在處理基于圖數據問題方面取得了巨大的成功
圖神經網絡在處理基于圖數據問題方面取得了巨大的成功
1 引言 圖神經網絡在處理基于圖數據問題方面取得了巨大的成功,受到了廣泛的關注和應用。GNNs通常是基于消息傳遞的方式設計的,本質思想即迭代地聚合鄰居信息,而經過次的迭代后, 層GNNs能夠捕獲節點的局部結構,學習來自跳鄰居的信息。因此更深層的GNN就能夠訪問更多的鄰居信息,學習與建模遠距離的節點關系,從而獲得更好的表達能力與性能。而在實際在做深層GNN操作時,往往會面臨著兩類問題:1. 隨著層數的增加,GNNs的性能會大幅下降;2. 隨著層數的增加,利用GNNs進行訓練與推斷時需要的計算量會指數上升。對于第一個問題來說,現有的很多工作分析出深層GNNs性能下降的原因是受到了過平滑問題的影響,并提出了緩解過平滑的解決方案;而對于第二個問題來說,設計方案模擬深層GNNs的表現能力并減少GNNs的計算消耗也成了亟待解決的需求,比如用于實時系統的推斷。針對這兩個問題,本文將分別介紹兩個在KDD 2020上的關于深度GNNs的最新工作。 第一個工作是Research Track的《Towards Deeper Graph Neural Networks》。該工作從另一個角度去解讀深度圖神經網絡隨著層數增加性能下降的問題,認為影響性能下降的主要原因是Transformation和Propagation兩個過程的糾纏影響作用,并且基于分析結果設計了深度自適應圖神經網絡(Deep Adaptive Graph Neural Networks) 模型,能夠有效地緩解深層模型的性能快速下降問題。 第二個工作是Research Track的《TinyGNN: Learning E?icient Graph Neural Networks》。該工作嘗試訓練small GNN(淺層)去模擬Deep GNN(深層)的表達能力和表現效果,致力于應用在實時系統推斷等對推斷速度有較高要求的場景。 2 Towards Deeper Graph Neural Networks 2.1 引言 1層的GCN只考慮了1跳鄰居的信息,而當使用多層的圖卷積操作擴大GCN的接受域之后,性能也會大幅下降。已有的一些工作[1,2]將這個性能大幅下降的原因歸根于圖神經網絡的過平滑問題(over-smoothing)。然而這篇文章保持一個不同的觀點,并且從另一個角度去解讀深度圖神經網絡性能下降的問題。這篇文章認為影響其性能快速下降的主要因素是表示變換(Transformation)和傳播(propagation)的糾纏作用,過平滑問題只有在使用了非常大的接受域,也就是疊加非常多層的時候才會影響圖神經網絡的表現效果。在進行了理論和實驗分析的基礎上,該文章提出了深度自適應圖形神經網絡的設計方案。代碼鏈接: https://github.com/mengliu1998/DeeperGNN 2.2實驗與理論分析 2.2.1 圖卷積操作 通常圖卷積操作遵循一種鄰居聚合(或消息傳遞)的方式,通過傳播其鄰域的表示并在此之后進行變化以學習節點表示。第層的操作一般可以描述為:
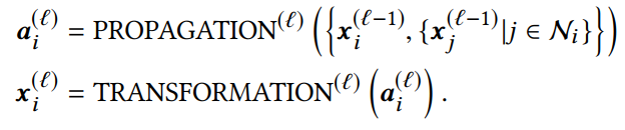
2.2.2 平滑度的定量度量 平滑度是反映節點表示相似程度的度量標準。通常兩個節點的歐氏距離值越小,兩個節點表示的相似性越高。本文作者提出了一種計算整張圖平滑度的指標:
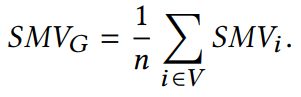
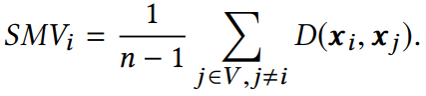
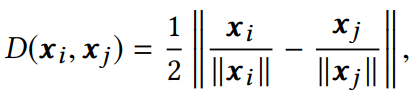
它與圖中節點表示的整體平滑度呈負相關,即越小,圖的平滑度越大。 2.2.3 深度GNN性能下降的原因 在評價指標的基礎上,作者對GCN在cora數據集上進行節點分類實驗的準確率、可視化以及指標數值的變化情況進行了統計,結果如下:

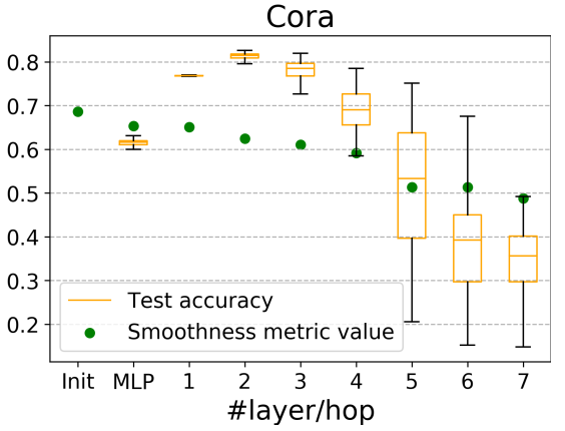
并給出質疑over-smoothing的兩點原因:(1) 過平滑問題僅會發生在節點表示傳播很多層之后,而實驗中cora的分類結果在10層之內就大幅下降。(2)評價指標的值與初始相比只有輕微下降,證明平滑程度只有一定的上升,而不足以導致過平滑。 而作者進一步指出,是轉換(Transformation)和傳播(propagation)的糾纏作用嚴重損害了深度圖神經網絡的性能。并且為了驗證該假設,作者將兩個過程分解出來,設計了如下的一個簡單模型:
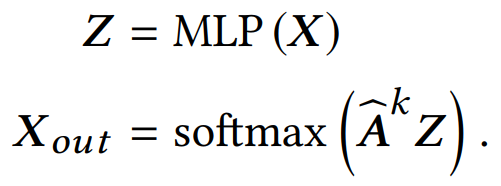
并同樣給出在cora上的實驗結果:
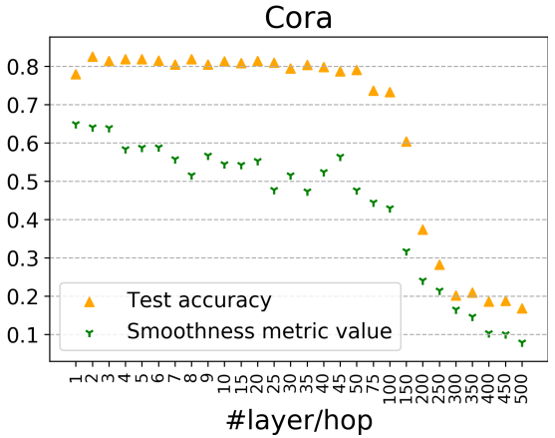

當兩個過程分解后,50層內的GCN準確率基本能夠在80%左右,當層數達到100+后才會陸續下降,對應的值也在300層以后變得很低,說明此時網絡受到過平滑的影響。以上兩個實驗說明了在GNN受過平滑影響之前,轉換(Transformation)和傳播(propagation)的糾纏作用確實會損害深度圖神經網絡的性能,導致性能大幅下降。也證實了解耦轉換和傳播可以幫助構建更深層次的模型,從而利用更大的可接受域來學習更多的信息。 2.2.4 理論證明 經過變換與傳播的解耦,作者的理論分析可以更嚴格且溫和地描述過平滑問題。在本節中,作者嚴格描述兩種典型傳播機制的過度平滑問題,并推導出當層數趨近于無窮時,兩種(, 的收斂情況。并證明該種傳播模式是線性不可分的,利用它們作為傳播機制將產生難以區分表征,從而導致over-smoothing問題。 2.3 模型
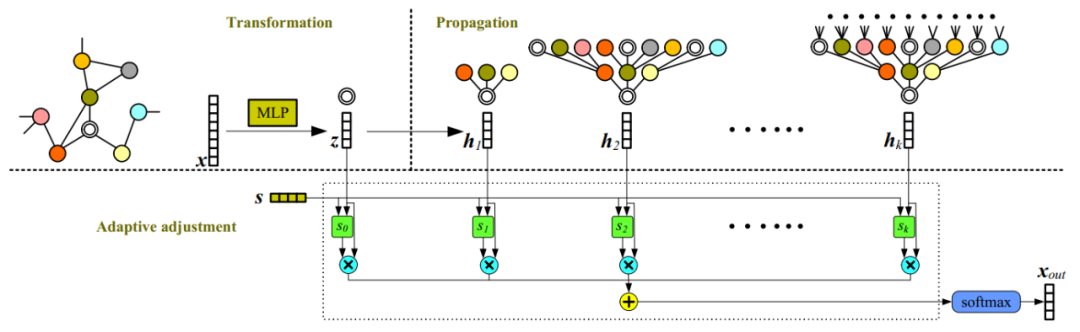
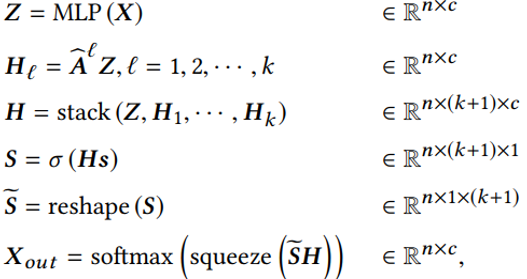
主要思想是將節點表示的變換與傳播過程解耦,并同時進行至層傳播,最后利用學得的融合權重向量做一個自適應調整融合。 2.4 實驗
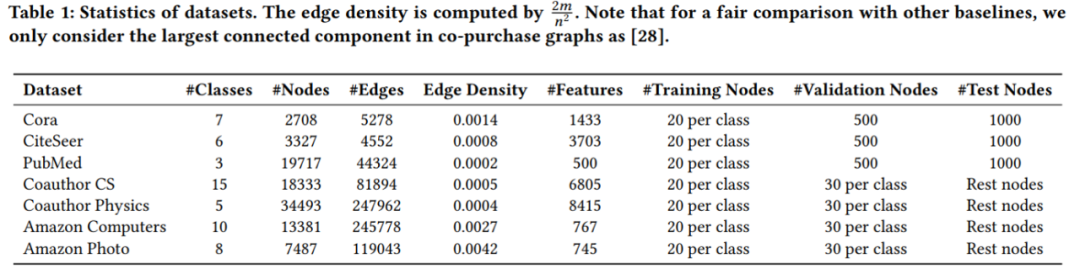
實驗數據集
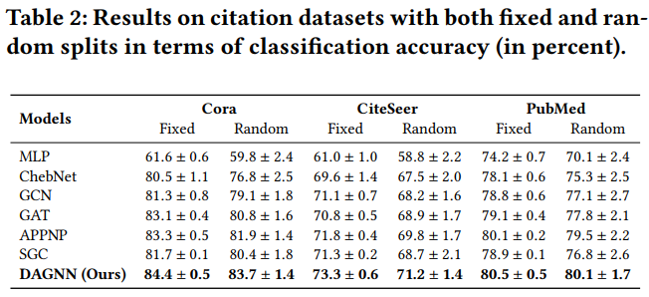
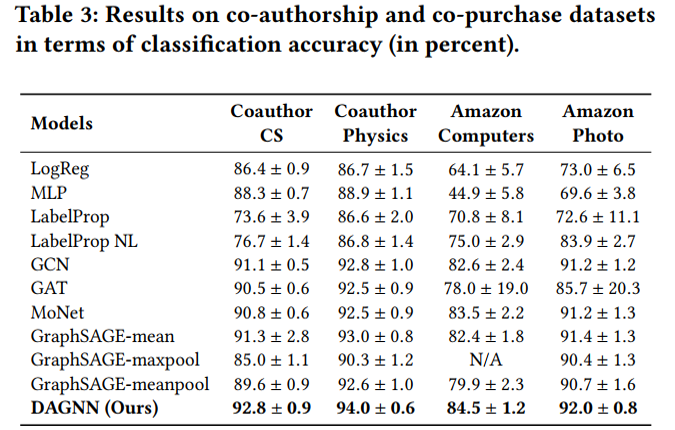
節點分類實驗結果
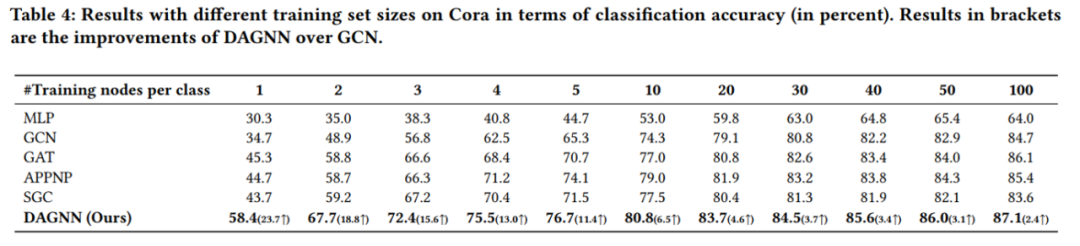
cora數據集上不同訓練集比例的分類準確率 值得分析的有以下兩點: (1)為什么低label rate的DAGNN表現要好?這些比較可觀的改進主要歸功于DAGNN的優勢: 通過消除表示轉換和傳播的糾纏,同時擴展接受域的范圍,使得利用信息更豐富。 (2)和APPNP SGC的區別是什么?APPNP和SGC實際上都解耦了轉換和傳播,并且APPNP也擴展了k階接受域。DAGNN比APPNP好,是因為設計了自適應調整每個節點來自不同接收域的信息權重。
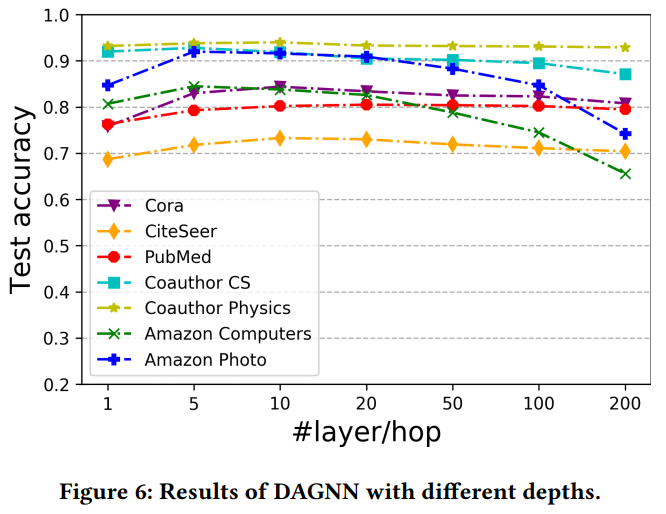
DAGNN在不同數據集上隨層數變化的表現 3 TinyGNN: Learning E?icient Graph Neural Networks 3.1 引言 經過k次迭代后,k層GNN可以捕獲來自k-hop節點結構信息。通過這種方式,一個更深層的GNN就有獲取更多鄰居信息的能力,從而取得更好的性能。舉例來說,下圖隨著GAT層數的增加,兩個數據集的分類準確率都有大幅提升。
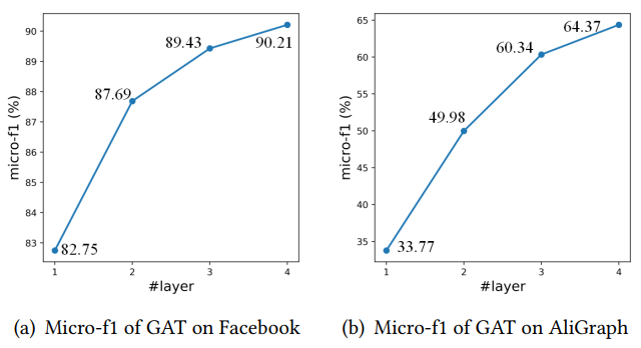
而相對應的,當GNN進一步擴展層數時,鄰域的指數擴增會導致GNNs模型需要大量的訓練和推理計算消耗。這使得許多應用程序(如實時系統)無法使用更深層的GNN作為解決方案。舉例來說,同樣的兩個數據,4層GAT的計算時間以指數級增長,導致計算消耗十分巨大。
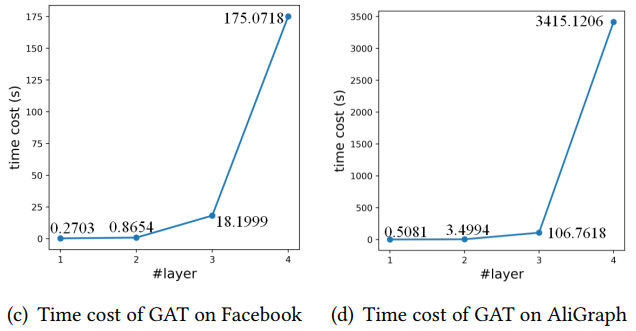
因此這里就存在著一個困境,即采用深層的GNN就越容易取得高性能,但是從效率的角度又往往傾向于開發一個小而推斷迅速的GNN。但是較小的GNN與較深的GNN之間存在較大的鄰域信息差距,這也是需要考慮的。因此這篇文章旨在訓練一個較小的GNN,既能很好地刻畫了局部結構信息,與較深的GNN相比可以獲得相似性能,同時也能夠進行快速的推斷。總結來說,貢獻如下: (1)提出了一種小型、高效的TinyGNN,能夠在短時間內實現推斷出高性能的節點表示。 (2)利用對等感知模塊(PAM)和鄰居蒸餾策略(NDS),以顯式和隱式兩種方式對局部結構建模,并解決小GNN和較深GNN之間的鄰居信息差距。 (3)大量的實驗結果表明,TinyGNN可以實現與更深層次的GNN相似甚至更好的性能,并且在實驗數據集上,推理過程能夠有7.73到126.59倍的提速。 3.2 模型 3.2.1 對等感知模塊 對等節點(peer nodes)指的是同一層GNN從同一個點源點采樣出的所有鄰居集合,在下圖(b)用相同的顏色表示。對等節點之間沒有通信,所有對等節點都能夠通過上層節點在兩跳內相連。大量的對等節點是鄰居,來自底層的鄰居信息可以被對等節點直接配置。
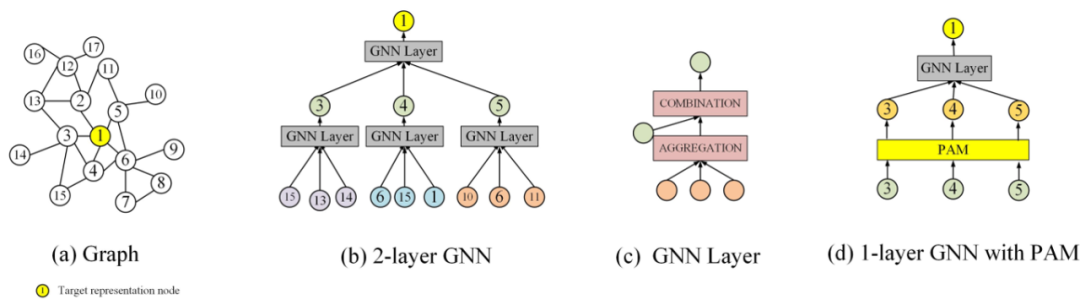
PAM建模對等節點的方式如下,以兩個節點隱層表示的相似度作為融合權重。PAM能夠幫助探索同一層中的節點之間的新關系,并幫助建模較小的GNN從而避免由較低層的鄰居迭代聚集而導致的大量計算。
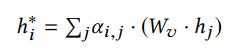
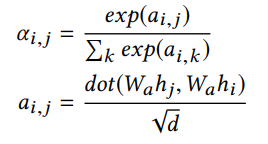
PAM可以被用于任何圖網絡結構中,作為一個基礎的模塊,1層GNN+1層PAM的計算量要小于兩層GNN。 3.2.2 鄰居蒸餾策略 作者利用知識蒸餾設計了鄰居信息蒸餾方案,teacher GNN是深層模型,能夠建模更廣泛的鄰域。而student GNN采用淺層模型,能夠有更快的推斷速度。并且利用teacher GNN 教student GNN隱式地捕捉全局深層結構信息,使得student GNN有深層GNN的表現效果。
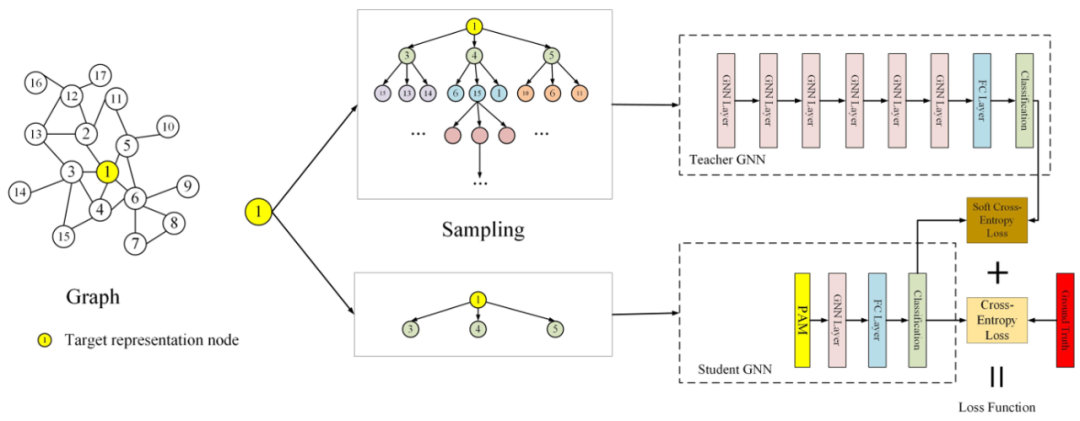
teacher GNN的損失函數:
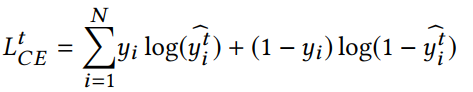
student GNN的損失函數,同時利用來自teacher網絡的軟標簽和真實標簽進行學習,T表示蒸餾溫度。
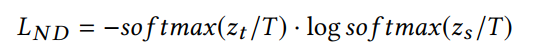
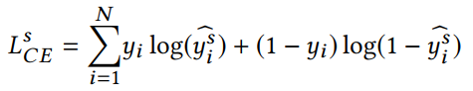
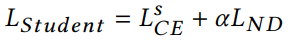
3.3 實驗
實驗數據集
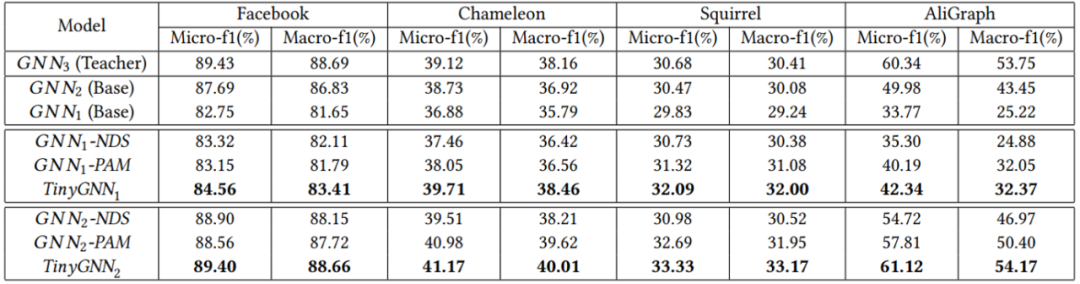
節點分類實驗結果
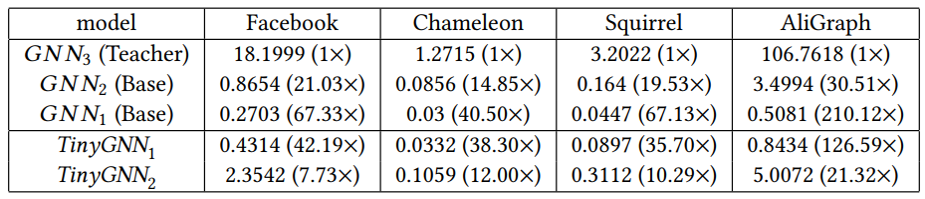
速度提升情況
-
神經網絡
+關注
關注
42文章
4762瀏覽量
100539 -
數據集
+關注
關注
4文章
1205瀏覽量
24644 -
GNN
+關注
關注
1文章
31瀏覽量
6328
原文標題:【KDD20】深度圖神經網絡專題
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論