 簡單的BP網絡識別液晶字符
簡單的BP網絡識別液晶字符
這學期的人工神經網絡課程已經進行完了第三章內容,關于經典網絡重要的BP(誤差反向傳播網絡)是所有學習人工神經網絡最先接觸到的一個實用網絡。它的原理相對比較簡單,在很多平臺中都非常容易實現。
學習神經網絡的基本原理之后,更重要的是能夠通過一些應用場合來應用它,使他能夠幫助自己解決一些實際的工程問題。
近期購買到的 LC100-A[1] 電感電容測量模塊,用于測量一些實驗中實驗對象的電感、電容值隨著其他一些物理變量(工作電壓、距離、溫度等)所產生變化規律。為了便于實驗,需要能夠將LC100-A測量數值自動記錄。


《《《 左右滑動見更多 》》》
在開始的方式就是直接使用攝像頭獲取液晶顯示數據,然后使用字符識別軟件來完成其中數字的識別。
測試一下CNOCR識別效果。它對于屏幕截圖中的文字識別效果還不錯:

▲ 屏幕截取的一段文字
識別時間:1.98。* 識別結果:
[[‘●’, ‘更’, ‘新’, ‘了’, ‘訓’, ‘練’, ‘代’, ‘碼’, ‘,’, ‘使’, ‘用’, ‘m’, ‘x’, ‘n’, ‘e’, ‘t’, ‘的’, ‘r’, ‘e’, ‘c’, ‘o’, ‘r’, ‘d’, ‘i’, ‘o’, ‘首’, ‘先’, ‘把’, ‘數’, ‘據’, ‘轉’, ‘換’, ‘成’, ‘二’, ‘進’, ‘制’, ‘格’, ‘式’, ‘,’, ‘提’, ‘升’, ‘后’, ‘續’, ‘的’], [‘訓’, ‘練’, ‘效’, ‘率’, ‘。’, ‘訓’, ‘練’, ‘時’, ‘支’, ‘持’, ‘對’, ‘圖’, ‘片’, ‘做’, ‘實’, ‘時’, ‘數’, ‘據’, ‘增’, ‘強’, ‘。’, ‘也’, ‘加’, ‘入’, ‘了’, ‘更’, ‘多’, ‘可’, ‘傳’, ‘入’, ‘的’, ‘參’, ‘數’, ‘。’], [‘●’, ‘允’, ‘許’, ‘訓’, ‘練’, ‘集’, ‘中’, ‘的’, ‘文’, ‘字’, ‘數’, ‘量’, ‘不’, ‘同’, ‘,’, ‘目’, ‘前’, ‘是’, ‘中’, ‘文’, ‘1’, ‘0’, ‘個’, ‘字’, ‘,’, ‘英’, ‘文’, ‘2’, ‘0’, ‘個’, ‘字’, ‘母’, ‘。’], [‘。’, ‘提’, ‘供’, ‘了’, ‘更’, ‘多’, ‘的’, ‘模’, ‘型’, ‘選’, ‘擇’, ‘,’, ‘允’, ‘許’, ‘大’, ‘家’, ‘按’, ‘需’, ‘訓’, ‘練’, ‘多’, ‘種’, ‘不’, ‘同’, ‘大’, ‘小’, ‘的’, ‘識’, ‘別’, ‘模’, ‘型’, ‘。’], [‘●’, ‘ ’, ‘內’, ‘置’, ‘了’, ‘各’, ‘種’, ‘訓’, ‘練’, ‘好’, ‘的’, ‘模’, ‘型’, ‘,’, ‘最’, ‘小’, ‘的’, ‘模’, ‘型’, ‘只’, ‘有’, ‘之’, ‘前’, ‘模’, ‘型’, ‘的’, ‘1’, ‘/’, ‘5’, ‘大’, ‘小’, ‘。’, ‘所’, ‘有’, ‘模’, ‘型’, ‘都’, ‘可’, ‘免’, ‘費’], [‘使’, ‘用’, ‘。’]]
那么對于前面液晶屏幕識別效果呢:

▲ 只是數字部分
識別結果:[[‘。’, ‘。’, ‘與’, ‘F’, ‘早’, ‘H’]]
好像驢唇不對馬嘴。
這主要原因還是原來網絡沒有針對上述液晶實現數字進行訓練過。由于液晶顯示圖片質量非常好,實際上只需要最簡單的BP網絡就可以達到很好的效果。
下面給出在MATLAB中構建網絡并進行實驗的過程。
使用神經網絡解決問題,一個重要的環節就是進行訓練數據的準備。通過對采集到的一些圖片中的數字進行提取并手工標注,來完成對網絡的訓練。
1.數字分割
下面是桌面攝像頭捕捉到的測量圖片,通過簡單的圖片灰度投影,比較方便將顯示數字所在圖片中的位置定出。為了簡單起見,也可以固定攝像頭與LCD相對位置,這樣手工定標出結果字符位置也可以適用于后面測量結果。

▲ 液晶數字顯示以及數字部分
這個問題簡單之處在于所有字符都是等寬,而且對比度非常好,簡單的分離就可以將所有的字符單獨分離出來。由于攝像頭位置固定,所以簡單分割之后的字符之后少量的上下左右平移,沒有旋轉。對于圖片位置、尺寸就不再進行歸一化。這些差異最后有神經網絡來彌補。

▲ 分割出的數字
液晶顯示字符的圖片對比度很好。但就是有一個問題,在攝像頭拍攝的時候,經常會遇到字符變化過程,這就會使得圖片中字符呈現兩個字符疊加的情況。下面是一些示例:

▲ 數字變化過程的圖片
這些過程,說實在的,即使人工識別也會無法分辨。
后面通過人工輸入標注了2000多個樣本。
2.圖片二值化
對于分割的圖片進行二值化,可以消除環境光對于圖片亮度的影響。在一定程度上,也可以消除液晶字符在變化時所引起的模糊。



上面所有的字符的尺寸是23乘以38點陣。

1.構建網絡和訓練
簡單的實驗,就用簡單的方法。對于前面所得到的字符,不再人工定義它們的特征。僅僅將原來的彩色圖片變換成灰度圖像,然后排列成23×38=874維向量。然后增加一層中間隱層便組成了最簡單的分類網絡。
net = patternnet(11)
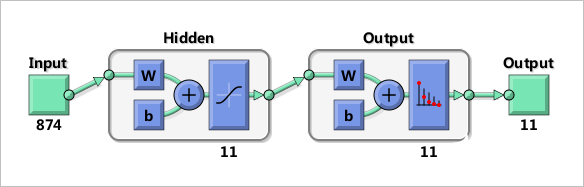
▲ 構造一個單隱層神經網絡
將前面人工標注的樣本一半用于訓練,全部樣本用于測試。下面給出了測試的結果。
plotconfusion(xx, net(yy))
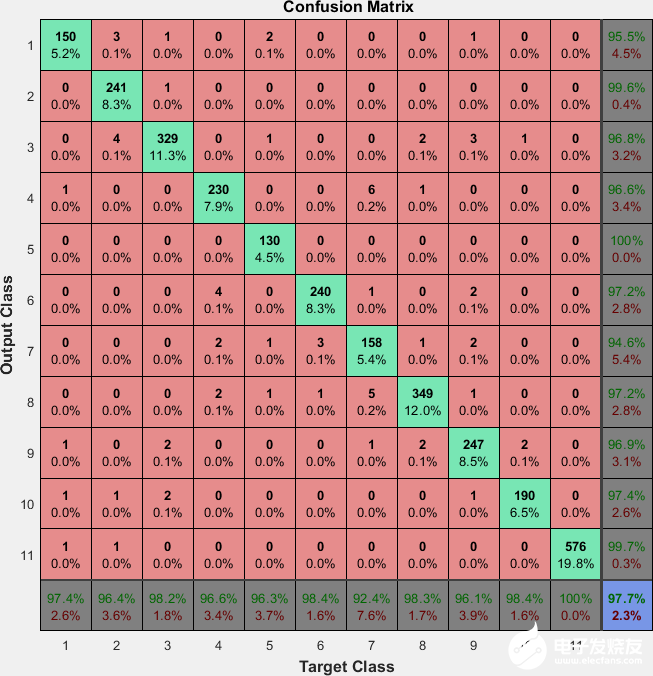
▲ 訓練結果
2.訓練結果與分析
整體的錯誤率大約為:ERR= 2.99%。
下面是識別正確的字符。
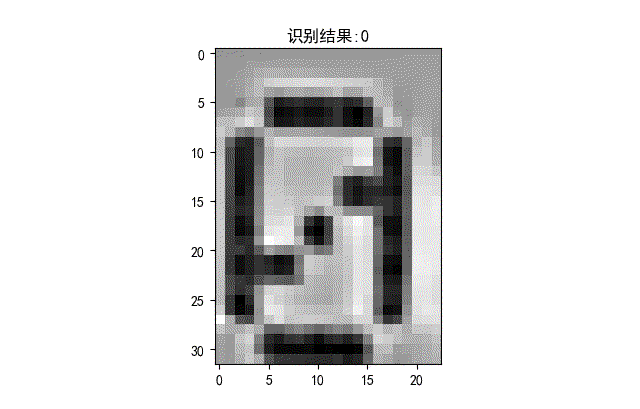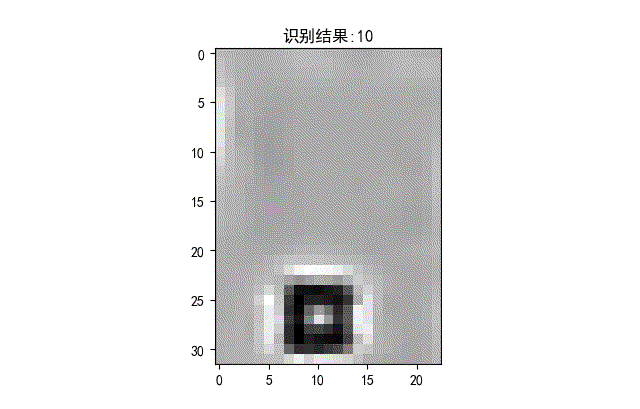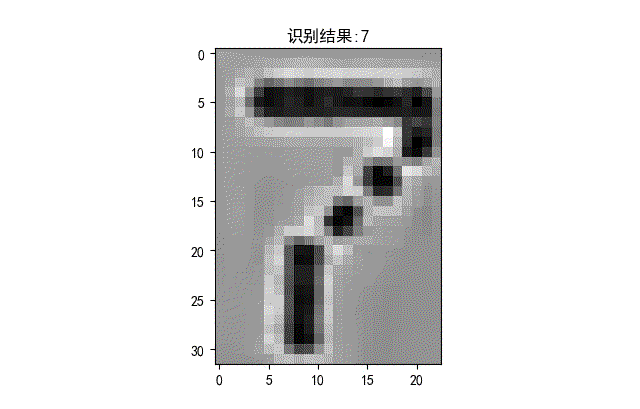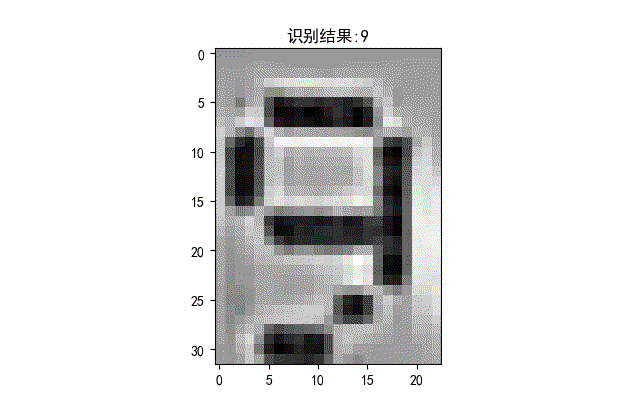
▲ 識別正確的字符
下面給出了部分識別錯誤字符的情況。基本上都是一些拍攝到液晶字符在變化過程中的重疊字符情況。這些情況本身在人工標注的時候就存在模糊。

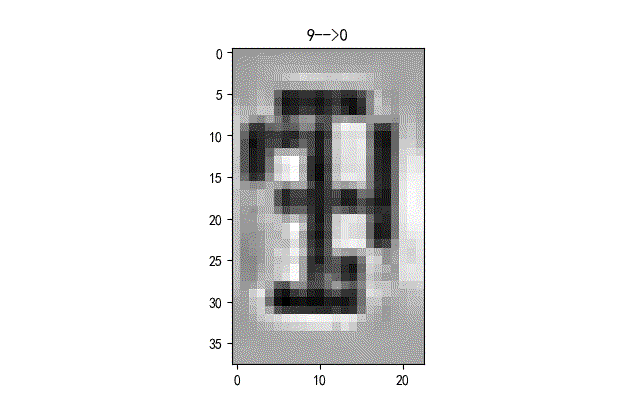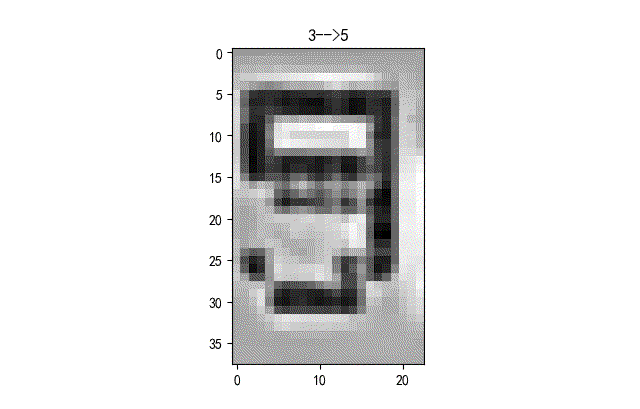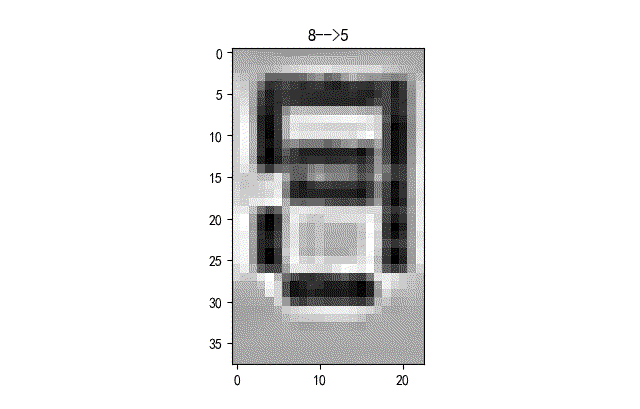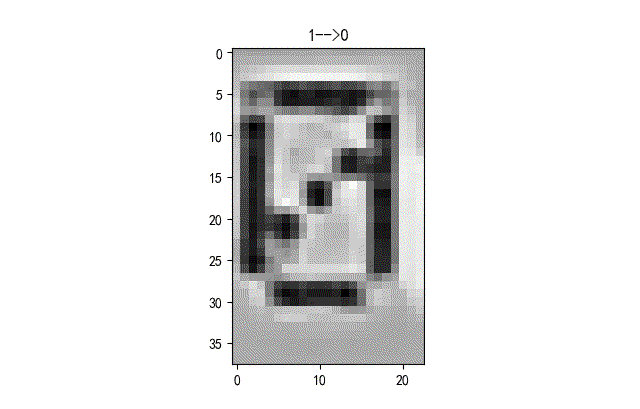
《《《 左右滑動見更多 》》》
3.網絡結構與錯誤率
下面給出了網絡的隱層節點個數與識別錯誤樣本個數之間的關系。可以看到當中間隱層節點大于5之后,識別性能就不再有明顯的變化了。
隱層節點個數234567891011
錯誤數量181065621677696665725868
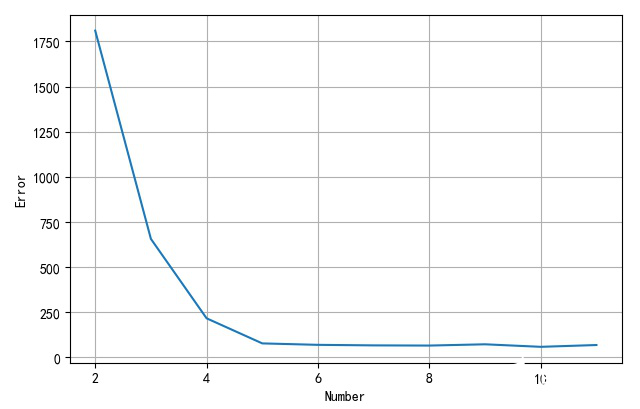
▲ 隱層節點個數與錯誤率
使用神經網絡解決問題,不是尋找最強大的網絡,而是需要最合適的網絡。
通過上面的測試結果來看,簡單的單隱層網絡便可以很好的滿足液晶顯示數字識別。那么對于那些由于數字跳動所引起的錯誤該怎么處理呢?
這個問題如果僅僅依靠增加訓練樣本和改進網絡結構是很難進行徹底解決,規避這個錯誤可以通過對連續識別結果進行比對來解決。對顯示數字進行連續快速采集5幀圖像,其中液晶跳動往往只發生在其中一幀,或者兩幀。那么對于五個圖像識別出的數字進行對比,找到相同次數最多的數字作為輸出結果。
責任編輯:haq
-
電容
+關注
關注
99文章
5995瀏覽量
149995 -
神經網絡
+關注
關注
42文章
4762瀏覽量
100535 -
BP神經網絡
+關注
關注
2文章
115瀏覽量
30533
發布評論請先 登錄
相關推薦
BP網絡的基本概念和訓練原理
BP神經網絡樣本的獲取方法
BP神經網絡最少要多少份樣本
BP神經網絡的學習機制
BP神經網絡在語言特征信號分類中的應用
BP神經網絡和人工神經網絡的區別
BP神經網絡的基本結構和訓練過程





 工商網監
工商網監
評論