 微軟團隊發布生物醫學領域NLP基準
微軟團隊發布生物醫學領域NLP基準
來自:HyperAI超神經
微軟的研究團隊近日在 arxiv.org 發布了論文:《Domain-Specific Language Model Pretraining for BiomedicalNatural Language Processing生物醫學特定領域的語言模型預訓練》,介紹并開源了一個能夠用于生物醫學領域 NLP 基準,并命名為 BLURB。
BiomedicalLanguageUnderstanding andReasoningBenchmark 的首字母縮寫,即為 BLURB 的命名規則,翻譯為生物醫學語言理解和推理基準。
醫學 NLP 基準,BLURB 身負重任
BLURB 包括 13 個公開可用的數據集,涉及 6 個不同的任務。
為了避免偏重多可用數據集的任務,如命名實體識別(NER),BLURB 的報告和排名,將所有任務的宏觀平均數作為主要得分。
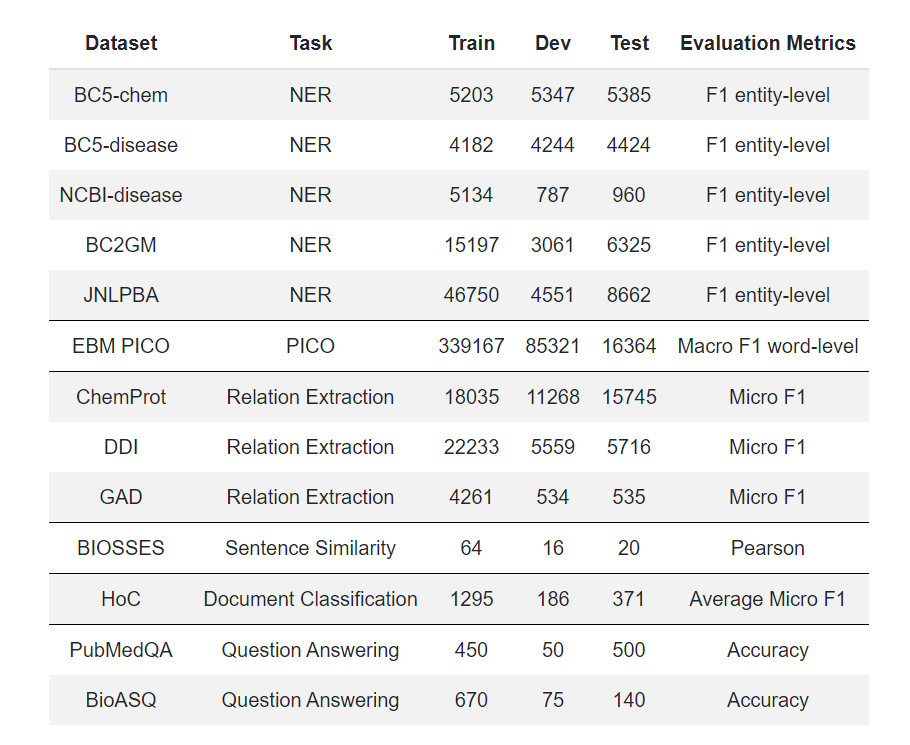
圖為 BLURB 中使用的數據集、以及
團隊列出的訓練、開發和測試中的實例數量
BLURB 排行榜是不分模型的。任何能夠使用相同的訓練和開發數據產生測試預測的系統都可以參與。
團隊表示 BLURB 的主要目標是:降低生物醫學NLP的準入門檻,幫助加快該領域的進展,能對社會和人類產生積極影響。
生物醫學 NLP :必須使用域內文本
研究已經表明生物醫學 NLP 可以在醫學領域提高數據集的準確性。但是在跨學科的數據集中,準確性又會大大降低。而由于不同醫學領域之間(Domain)跨度較大,所以對于 NLP 的預訓練會花費非常多的時間。
微軟研究人員為了提升 NLP 的訓練速度,通過對預訓練和特定任務的微調,對生物醫學 NLP 應用的影響進行了建模比較,從而評估最適合的預訓練方法。
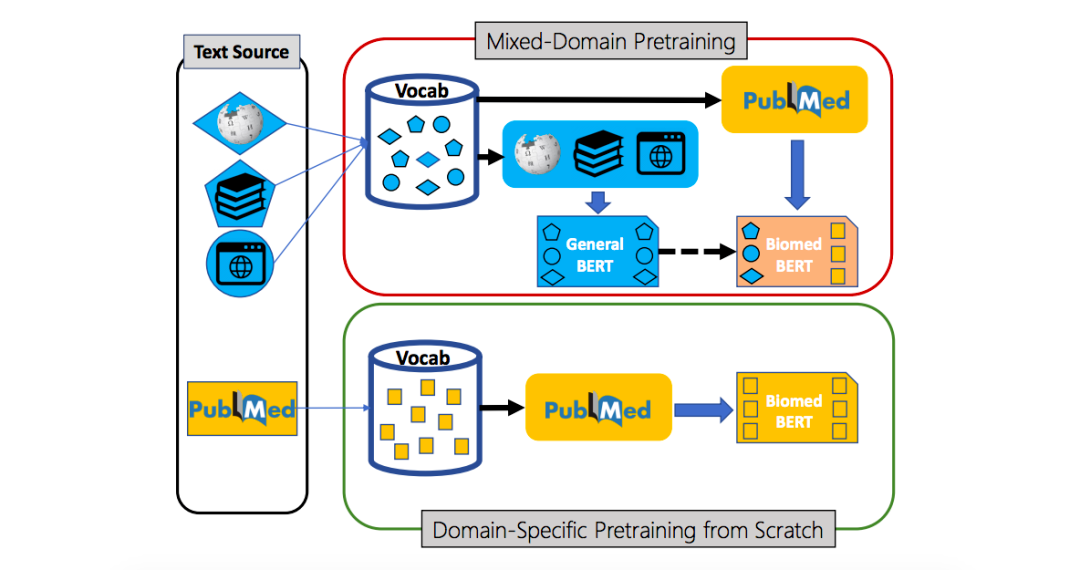
團隊對域內文本與混合域外文本進行的對照
首先,團隊創建了一個名為「生物醫學語言理解與推理基準」(BLURB)的基準,該基準側重于 PubMed 提供的出版物,涵蓋了相似問題解答和文本提取之類的任務。
實驗證明,這種對比的方法能夠將 NLP 訓練的速度提升數倍。
同時,為了鼓勵對生物醫學 NLP 的研究,研究人員創建了以 BLURB 基準為基準的排行榜,還開源了預訓練模型。以求快速生物醫學 NLP 能夠早日投入使用。
原文標題:醫學AI又一突破,微軟開源生物醫學NLP基準:BLURB
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
微軟
+關注
關注
4文章
6516瀏覽量
103616 -
AI
+關注
關注
87文章
28883瀏覽量
266258 -
生物醫學
+關注
關注
0文章
45瀏覽量
11137
原文標題:醫學AI又一突破,微軟開源生物醫學NLP基準:BLURB
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NLP技術在人工智能領域的重要性
生物醫學領域的傳感器有哪些?
Aigtek安泰電子第一屆全國等離子體生物醫學學術會議圓滿結束!

天府錦城實驗室在生物傳感與蛋白質測序領域取得重要進展

3月15-17日 與Aigtek相約第一屆全國等離子體生物醫學學術會議!
優可測推動微流控技術革新,精準助力生物醫學等行業的發展

類比半導體與深圳大學生物醫學工程學院共建醫療聯合實驗室
新型超聲波墨水分散及細胞接種技術實現生物醫學胚胎培養新突破
前置微小信號放大器在生物醫學中有哪些應用
生成式人工智能在生物醫學工程的應用
功率放大器在生物醫療測試領域研究中的應用
數字微流控技術在生物醫學領域的應用研究進展
DLP光學引擎在生物3D打印方面應用

一種基于橫向位移檢測機制的MXene增強SPR生物傳感技術
功率放大器在生物醫學領域測試研究中的應用





 工商網監
工商網監
評論