 計算機視覺應用中3大瓶頸問題及解決方案
計算機視覺應用中3大瓶頸問題及解決方案
本文摘自于:雷林建, 孫勝利, 向玉開, 張悅, 劉會凱. 2020. 智能制造中的計算機視覺應用瓶頸問題. 中國圖象圖形學報, 25(7): 1330-1343.) [DOI: 10.11834/jig.190446
計算機視覺在智能制造工業檢測中發揮著檢測識別和定位分析的重要作用,為提高工業檢測的檢測速率和準確率以及智能自動化程度做出了巨大的貢獻。然而計算機視覺在應用過程中一直存在技術應用難點,其中3大瓶頸問題是:
計算機視覺應用易受光照影響
樣本數據難以支持深度學習
先驗知識難以加入演化算法
本文針對計算機視覺應用存在的3大瓶頸問題總結分析了問題現狀和已有解決方法。經過深入分析發現:
針對受光照影響大的問題,可以通過算法和圖像采集兩個環節解決;
針對樣本數據難以支持深度學習的問題,可以通過小樣本數據處理算法和樣本數量分布平衡方法解決;
針對先驗知識難以加入演化算法的問題,可以通過機器學習和強化學習解決。
【正文部分】
1 智能制造中的計算機視覺發展現狀及需求
1.1 智能制造中的計算機視覺發展現狀
計算機視覺的發展主要經歷了4個階段,第1階段稱為計算視覺,第2階段是主動和目的視覺,第3階段是分層3維重建理論,第4階段是基于學習的視覺,如圖 1所示。
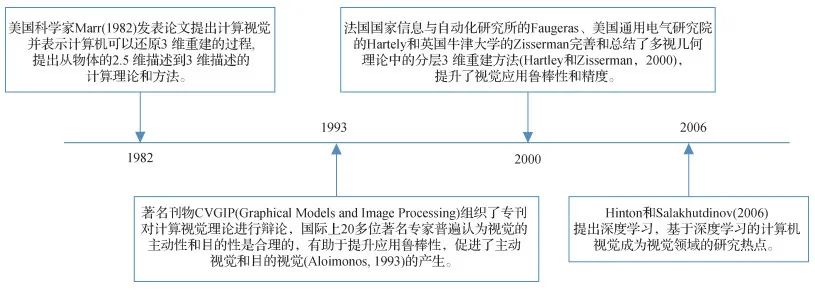
計算機視覺發展的4個階段 具體到智能制造業的應用,工業檢測是計算機視覺應用的主要方向。由于生產中不可避免會產生缺陷和誤差,導致部件或者產品出現殘次品。因此,在流水線后端需要檢測環節。目前大多采用人工檢測方法或是自動化程度不高的機器方法,這導致原本效率提高的流水線因為檢測環節再次緩慢下來。
因此計算機視覺檢測技術在智能制造工業檢測領域的應用至關重要。目前各類相關研究非常廣泛,大到汽車制造業中的汽車車身視覺檢測,小到軸承表面缺陷檢測。表 1給出了基于圖像的軸承故障診斷的計算機視覺方法。 表 1軸承故障診斷的計算機視覺方法對比
Table 2Comparison of computer visual methods for fault diagnosis of bearing
| 方法 | 平均故障識別率/% | 特點 |
| 基于加權FCM(fuzzy C-means)算法(隋文濤,2011) | 97.50 | 故障識別率無法提高,但魯棒性高。 |
| 基于學習的深度信念網絡分類識別算法(李巍華等,2016) | 97.58 | 40%可以達到99.0%識別率,易出現效果極差的情況。 |
1.2 智能制造對計算機視覺技術的發展需求
智能制造業中涉及大量檢測環節,如缺陷檢測、形變檢測、紋理檢測、尺寸檢測等。 計算機視覺技術作為檢測領域目前最有效的方法之一,必然會在工業檢測的應用中掀起一場革命性的制造模式大轉變。它能再一次解放勞動力,大幅度提高制造業的生產效率,降低生產成本,減少生產環節,促使生產線全自動化的形成。 但目前計算機視覺在智能制造工業檢測領域的實際應用存在諸多瓶頸問題尚未解決,其中3個關鍵的瓶頸問題值得研究討論。 1) 實際智能制造業環境復雜、光源簡單,容易造成光照不均勻,難以解決圖像質量受光照影響大的問題。在檢測領域的實際應用中,由于工業場地環境變化的不確定性,會使計算機視覺的圖像采集環節受到影響。在工業檢測中,檢測的通常都是流水線上一致性很高的產品,需要檢測的缺陷通常也是相對微小的,因此對圖像的要求較高。除了保證相機的各參數一致以外,還需要控制環境因素的影響,這是工業檢測中特有的控制因素之一。由于環境變化隨機性大,使得控制光照成為智能制造檢測領域的計算機視覺關鍵瓶頸問題。 2)實際智能制造業中獲取萬級以上的平衡樣本數據代價較大,難以解決樣本數據不是以支持基于深度學習的計算機視覺檢測任務的問題。在所有學習方法中,樣本數據是最重要的因素之一。尤其是深度學習,往往需要非常大量的樣本才能達到比較優異的檢測效果。在一定數量級(欠學習)之內,樣本和檢測效果甚至成正比關系。而在智能制造業,樣本數據的采集卻是一大問題。因為企業追求利益,無法像做研究一樣順利進行樣本數據采集,甚至有些產品的總產量都達不到深度學習所需的樣本數據規模。 3)智能制造業中,計算機判定難以達到專業判定的水準,如何在算法中加入先驗知識以提高演化算法的效果是一大難題。如何有效利用先驗知識,降低深度學習對大規模標注數據的依賴,成為目前業內的主攻方向之一。由于先驗知識的形式多變,如何與深度學習有效結合是一大難點。具體到工業檢測領域,問題更加嚴峻,在需要解決上述問題的同時,還需要考慮如下難點:如何將比普通先驗知識更復雜的工業檢測專業知識轉化為知識圖譜等形式融入算法;如何建立工業檢測先驗知識的規范化、標準化和統一化;如何通過已有產品的先驗知識推測知識庫未收錄的其他類似產品的先驗知識。
2 智能制造中計算機視覺應用易受光照影響的問題
2.1 受光照影響大的問題概述
工業檢測不同于其他檢測領域,不同工業產品的檢測通常也在不一樣的環境中進行。一般來說,工業產品的生產過程在開放式的車間或者倉庫環境中進行,自然采光差、光來源復雜、光照設備不專業是普遍存在的問題,加之智能制造領域對于檢測的正確率和速率有著更為嚴苛的要求,光照控制作為提升識別率的重要途徑需要更好的技術加持。 對于大型智能制造工業現場,開放式的復雜工作環境容易造成拍攝圖像的過程中光照強度的大范圍變化。相比之下,小型工業現場的自然光照等其他干擾較小,但小型產品的檢測精細度更高,對于光照穩定性的要求也隨之提高,控制光照的難度反而更高。實驗室穩定光照條件下獲得的樣本數據集訓練出的模型并不能在工業現場取得很好的檢測效果。不僅光照條件的苛刻性使得智能制造中的計算機視覺應用難度增加,而且智能制造領域對準確率的要求也更為嚴苛。因此,如何控制光照均勻性是目前一大瓶頸問題。
2.2 受光照影響大的解決方法
目前智能制造工業檢測領域計算機視覺中的光照問題研究大多從算法上入手。如基于Retinex的X光非均勻鋼絲繩芯輸送帶圖像校正和增強算法提出了一種基于機器視覺的非均勻光照輸送帶圖像校正和故障檢測算法。基于統計特性的光照歸一化方法充分考慮了圖像的光照局部性,通過對圖像局部的均值和方差進行調節,引入線性插值方法,將對數變換與本文方法結合調整圖像的光照,可以很好地進行光照的歸一化。工業檢測的光照特性變化隨機,而此法可根據圖像的特性動態調整,具有可用性。 智能制造工業檢測領域中需要相機拍攝圖像以進一步通過計算機視覺技術完成處理分析,因此在圖像采集環節對光照加以控制是另一種常用方法。它的特點是可以避免復雜的算法實現,但會增加硬件成本和復雜度。在針對某物體的圖像采集過程中,相機、鏡頭的配置會直接影響成像的效果,通過調試可確定最優的相機、鏡頭配置。同時,外加光源可以有效地減弱環境光對圖像采集的干擾,保證一系列圖像的穩定性,也能調整得到適合工業檢測的特定光照。 視覺獲取的最優情形以及以光源和相機為主體的光照協調技術把相機和光源作為一個整體加以協調,利用交替法優化配置最優光照和相機位置,使得在當前環境下的圖像具有較高的平均亮度和對比度。此方法能提高樣本圖像數據的質量,使光照的會聚指數上升約0.15 %,但也使得采集圖像的復雜度上升。數字攝像機參數自適應調整算法用以提高機器視覺系統對光照變化的魯棒性,它能根據外界環境的光照條件,在線調整數字攝像機的參數和設置,以采集像素灰度在預設值范圍內的圖像,有效減弱了光照變化對圖像灰度的影響,缺點在于實時調整對相機和調整算法的要求都很高,很難保證長時間精準實現,易丟失實時性。
3 智能制造中計算機視覺應用的樣本數據難以支持深度學習的問題
3.1 樣本數據難以支持深度學習的問題概述
智能制造工業檢測中,除傳統的模板匹配方法,目前更主流的是基于深度學習的方法。因工業檢測的高準確率需求,有監督的深度學習能滿足要求。有監督的深度學習的一大特點是需要已知類別標簽的訓練圖像數據集,這個訓練集理論上包含的數據量越大,檢測的效果越好。但結合工業檢測的實際場景,難以采集這么大的樣本數據量。另外,制造行業中缺陷品的數量遠遠少于合格品,隨機獲取的訓練集樣本將存在樣本分布不平衡的問題。即使在大樣本數據二分類問題中,樣本分布也應該盡量做到每類占比50 %。
在智能制造領域,獲取樣本圖像數據的方法有兩種,一種是在流水線作業時在線采集,另一種是樣本擺拍的離線采集。 在流水線作業時在線采集的優勢在于不影響工業生產即可完成樣本圖像數據的采集,圖像數據來自于工業現場,并且可采集最大等同于生產數量的樣本圖像數據集。但問題在于樣本類別按合格率分布,缺陷品的樣本圖像將遠遠小于合格品,樣本分布不平衡。其次工業現場的拍攝環境無法保證,容易造成樣本圖像的質量不一,影響訓練效果。 相對地,樣本擺拍的離線采集模式的優點是可控的樣本分布,人工控制各類別的樣本數量分布一致;可控的實驗室拍攝環境,可以保證得到高質量的樣本圖像。缺點也很明顯,收集樣本需花費大量時間,拍攝耗時耗力,訓練模型不一定能適用于工業現場檢測,短時間內無法得到大樣本圖像數據集。因此,樣本數據由于量小、不平衡難以支持深度學習,成為目前的一大瓶頸問題。
3.2 樣本數據難以支持深度學習的解決方法
智能制造檢測領域的樣本數據存在難以獲取大量有效樣本數據的問題, 以及難以獲取各類樣本數量分布平衡的樣本數據集的問題。難以獲取大量有效樣本數據的問題可以轉化為針對小樣本數據如何取得良好檢測分類效果的問題,主要方法如表2所示。 表 2利用小樣本數據檢測分類的方法
Table 3Methods for detection classification using small sample data
| 方法 | 基本思想 | 特點 |
| 基于微調(fine tune)的方法 | 基于一個已經被訓練過的基礎網絡,根據現有的小樣本數據對這個網絡進行微調,使其在特定數據域上效果更好。 | 需要利用原先大樣本數據訓練好的模型并結合特定小樣本進行參數微調,速度較快,能提升此特定領域預測效果。 |
| 基于度量(metric)的方法 | 對樣本間的距離分布進行建模,使同類樣本聚合,異類分離。 | 本質是基于小樣本的分類器,通過距離或其他參數進行分類,學習快速,泛化能力強,收斂能力較弱。 |
| 基于元學習(meta learning)的方法 | 從之前的學習學會如何學習,對于新的任務不必從零開始,而是根據一定的元數據,自動學習如何解決新的任務。 | 靈活性強,泛化能力強,利用少量樣本即可解決新的學習任務,需要更大的時間成本訓練出學習模型。 |
| 基于圖神經網絡(graph neural network, GNN) (Garcia和Bruna,2018)的方法 | 用圖的形式構建了神經網絡,把樣本看做節點,通過節點彼此間的連接做到信息擴散,可以把有標簽的樣本信息擴散到與之最相似的需要預測的樣本上。 | 本質上是基于度量的方法,mini-ImageNet上5分類準確率大約在95%左右,小樣本表現不穩定,應用有待深入。 |
針對難以獲取各類別樣本數量分布平衡的樣本數據集有如表 3的解決方法。
表3樣本分布不平衡的解決方法
Table 5Solution to sample distribution imbalance
| 方法 | 基本思想 | 特點 |
| 數據增廣方法 | 對原圖進行多種方法處理,形成稍有差異的圖像數據,以補充數據過少或者數據單一的問題。 | 常用方法:色彩抖動、主成分分析(principal components analysis, PCA)抖動、尺度變換、裁剪縮放、平移翻轉、旋轉仿射、高斯噪聲。能擴張數據集的數量,但質量不如原始數據集,并可能產生實際不存在的樣本圖像,預測效果會下降。 |
| 重采樣方法 | 對樣本數量大的樣本進行欠采樣,即刪除部分樣本;對樣本數量小的樣本進行過采樣,即添加樣本的副本。 | 在一定程度緩解了不同類樣本數量差距懸殊的問題,但降低了數據集質量,增加了訓練的誤差,訓練的效果不理想。 |
| SMOTE(synthetic minority over-sampling technique)(Chawla等,2002) | 本質上是過采樣,構造新的小類樣本,新樣本不是原始樣本的副本或增廣,而是從小類樣本中的兩個或多個相似樣本選擇一個樣本,從鄰近的其他樣本中選擇一個屬性添加到這個樣本上形成。 | 屬性一般是某種特征,產生的樣本質量比樣本副本和增廣質量高很多,但非常容易產生實際不存在的樣本,不具有很強的應用性,無法保證屬性之間的線性關系。 |
研究結果表明,目前樣本數據難以支撐深度學習的問題主要包括樣本數據量小和樣本數據不均衡,對于這兩個問題的方法已有如上所述的研究體系和方法。此類樣本數據處理算法都是針對樣本的數量而不是樣本的內容,因此在智能制造的工業檢測領域,使用上述方法調整樣本數據是完全可行的。
4 智能制造中計算機視覺應用的先驗知識難以加入演化算法的問題
4.1 先驗知識難以加入演化算法的問題概述
計算機視覺在智能制造中的應用本質上是一種基于數據的方法,但在工業檢測領域難以獲取大量均勻的樣本數據,因此研究者們提出將先驗知識加入計算機視覺算法中以期獲得更好的檢測效果。應用基于先驗知識的方法,在訓練階段可以配合樣本進行訓練,提高模型參數的準確性,降低學習難度,利于訓練過程的收斂,從而提高預測的準確度。在預測階段,能通過先驗知識對判定結果的校正,提高準確率,也能提升檢測速度,避免偶然誤差的產生。
目前先驗知識難以加入演化算法,更難以指導機器學習和深度學習等算法,并且也有很多需要解決的瓶頸問題。例如,如何將知識圖譜這種主要知識表示形式用于指導深度神經網絡;如何用自然語言指導強化學習中的智能體快速準確地理解學習;如何將遷移學習作為知識結合進強化學習;如何通過領域知識將強化學習方法應用到工業檢測中等。
4.2 先驗知識無法支持演化算法的解決方法
針對如何將先驗知識應用到學習中以及以何種形式應用的問題,目前有如下的研究和方法。一種是將樣本的緊密度信息作為先驗知識應用到支持向量機的構造中。通過對緊密度的置信度進行建模,通過模糊連接度可以將支持向量與含噪聲樣本進行區分。此方法能夠得到具有更好抗噪性能及分類能力的支持向量機,通過將樣本的緊密度信息作為先驗知識,不僅考慮到樣本類間中心距離,還考慮了樣本與類內其他樣本的關系,通過模糊支持向量機加以區分。在工業檢測領域,缺陷樣本和正常樣本本身差距就不大,若能將樣本的緊密度信息加入訓練,將有助于提升訓練效果,能夠更加準確地分離小缺陷、弱缺陷樣本。 宣冬梅等給出了兩種將先驗知識與深度學習模型融合的方法。第1種實質上將深度學習得到的輸出作為給定樣本的條件概率,即加先驗知識的隨機深度學習分類器(random deep learning classifier with prior knowledge, RPK)。第2種加入一個參數用以調整先驗知識的稀疏性,即加先驗知識的確定型深度學習分類器(deterministic deep learning classifier with prior knowledge, DPK)。這兩種方法得到的分類器都能更好地預測結果。但這兩種方法在多分類任務的識別率上不夠高,只能精確地進行二分類任務。兩者都是在深度學習模型框架之內加入了以矩陣形式存在的先驗知識,這些先驗知識可以是任何可矩陣化形式的內容。在智能制造工業檢測領域,諸如用于檢測軸承缺陷的神經網絡參數可作為用于檢測圓形注塑件的先驗知識矩陣。 另外,基于知識的強化學習在先驗知識應用中有著較大的優勢。此類方法在分析預測方向有較好的表現,因此在工業檢測領域有巨大的發展前景。表4給出了4種典型方法。 表4基于知識的強化學習方法
Table 6Knowledge-based reinforcement learning method
| 方法 | 特點 | 典型實例 |
| 專家指導 | 將專家引入到強化學習的智能體學習回路中,為智能體提供強化信號,而后通過監督學習對該信號進行建模。 | Knox和Stone(2009)提出的TAMER框架通過專家做的決策動作預測長遠的收益,填補了智能體自主學習無法預測深層利益的弊端。 |
| 回報函數指導 | 將先驗知識或過程經驗用以指導設計回報函數的方法,使回報函數更加科學和有助于收斂,如何準確地指導設計是其中的關鍵(Mataric,1994)。 | Randl?v和Alstr?m(1998)教會系統學習騎自行車,證明了此方法的有效性;Ng等人(1999)利用回報勢函數衡量回報函數偏差,以衡量指導設計是否有效,使得80%的搜索具有目的性,僅20%是隨機的,在缺乏領域知識的情況下,仍然無法保證回報函數是否設計合理。 |
| 搜索策略指導 | 在搜索策略中引入知識以提高探索能力,根據領域知識對Simhash函數輸入的特征進行篩選,對權重進行修改可提高學習能力(Tang等,2017)。 | Bianchi等人(2008)提出了定量的啟發式信息選擇動作函數,使千量級的搜索過程降低到100步之內,但未給出函數權重值的取值依據和方法。 |
| 模仿學習 | 通過模仿一批人類專家的決策軌跡數據解決強化學習任務中多步決策搜索空間巨大的問題。 | Guo等人(2014)提出了蒙特卡羅樹搜索加神經網絡的方法,進行模仿學習策略,此方法能通過分類或回歸學習符合人類專家決策軌跡的策略模型,但卻因為通過拖慢節奏比實時慢幾個數量級而帶來較大的時間開銷。 |
上述研究結果表明,在先驗知識和深度學習結合的過程中,形成了基于知識的強化學習理論,它的誕生也進一步驗證了先驗知識在演化算法中應用的有效性,這為通過先驗知識提高智能制造工業檢測效果提供了一個重要方向。
5 結語
隨著計算機視覺在智能制造領域的深入,它涉及的應用將更多更廣,發揮的作用也越來越大。從理論到應用的這一過程中遇到了很多瓶頸問題,如何克服這些難點以及探索更實用的解決方案將是下一階段需要著重開展的研究工作。 目前針對3個瓶頸問題的研究方法眾多,可從如下思路進一步研究:
1) 針對計算機視覺應用易受光照影響的問題,可設計黑箱式封裝的圖像采集設備,排除外界光照干擾,安裝在工業生產線上,從而達到實驗室級別的檢測環境,從根本上解決光照影響問題。
2) 針對計算機視覺應用中樣本數據難以支持深度學習的問題,可通過小樣本和不平衡樣本處理方法在不降低樣本數據質量的同時增大樣本數據量,并且結合傳統方法如模板匹配和相似度檢測來輔助增加檢測準確率。
3) 針對計算機視覺應用中先驗知識難以加入演化算法的問題,除了從訓練和預測階段入手,在決策的判斷上也可做基于先驗知識的判定。如在合格率較高的零件檢測中,一些不常見的錯誤判定可以根據先驗知識修改為正確判定,從而提高準確率。
聲明:部分內容來源于網絡,僅供讀者學術交流之目的。文章版權歸原作者所有。如有不妥,請聯系刪除。
責任編輯:PSY
原文標題:智能制造中的計算機視覺應用瓶頸問題
文章出處:【微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
-
計算機
+關注
關注
19文章
7421瀏覽量
87718 -
計算機視覺
+關注
關注
8文章
1696瀏覽量
45927 -
智能制造
+關注
關注
48文章
5481瀏覽量
76261
原文標題:智能制造中的計算機視覺應用瓶頸問題
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
計算機視覺有哪些優缺點
計算機視覺技術的AI算法模型
計算機視覺的五大技術
計算機視覺的工作原理和應用
計算機視覺與人工智能的關系是什么
計算機視覺與智能感知是干嘛的
深度學習在計算機視覺領域的應用
機器視覺與計算機視覺的區別
計算機視覺的主要研究方向
計算機視覺的十大算法







 工商網監
工商網監
評論