 騰訊優圖實驗室在人體2D姿態估計中獲得了創新技術突破
騰訊優圖實驗室在人體2D姿態估計中獲得了創新技術突破
近日,騰訊優圖實驗室在人體2D姿態估計任務中獲得創新性技術突破,其提出的基于語義對抗的數據增強算法Adversarial Semantic Data Augmentation (ASDA),刷新了人體姿態估計國際權威榜單。相關論文(Adversarial Semantic Data Augmentation for Human Pose Estimation)已被計算機視覺頂級會議EUROPEAN CONFERENCE ON COMPUTER VISION (ECCV2020)收錄。
作為計算機視覺領域的基礎技術之一,人體姿態可以理解為對“人體”的姿態(關鍵點,比如頭、左手、右腳等)的位置估計,其中2D人體姿態估計在多種視覺應用中發揮著重要作用。不過盡管該技術研究的時間歷程較長,相關創新方法也層出不窮,但在很多場景下,其效果依然不盡人意。
如圖1所示,對于對稱性較強的人體、遮擋比較嚴重的場合以及多人場景,2D姿態估計的表現普遍比較差。解決上述問題的一種有效的方法是對數據集進行數據增強,然而現有的數據增強算法比如圖片的翻轉、旋轉或者圖片色度的改變,都是全局尺度上的數據增強,無法解決圖中所示的挑戰性案例。

圖1. 二維人體姿態估計的挑戰性案例
為解決上述提及的難點,優圖提出了基于語義對抗的數據增強算法Adversarial Semantic Data Augmentation (ASDA)。該算法的整體pipeline如圖2所示,輸入圖片經過生成網絡,進行語義粒度上的數據增強;增強后的圖片作為姿態估計網絡的輸入,進行姿態估計,得到二維人體姿態。生成網絡生成增強樣本,提升姿態估計網絡的預測難度,姿態估計網絡則試圖預測增強后圖片。
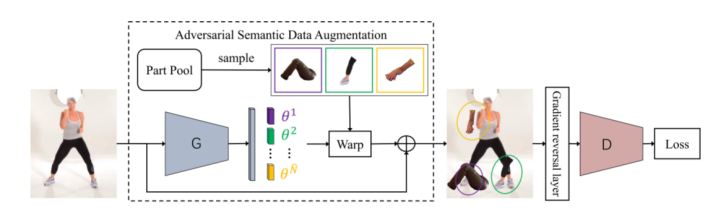
圖2. ASDA算法流程圖
與其他算法相比,騰訊優圖的算法有三點創新。創新之一,提出了一種基于局部變換的數據增強方式,有效填補了全局數據增強的缺陷。創新之二設計了一種基于人體語義部件的數據增強算法(SDA, Semantic Data Augmentation),通過語義粒度上的圖像替換以及變換來有效模擬之前網絡無法處理的挑戰案例。
第三點創新便是提出了ASDA算法,該算法在MPII、COCO、LSP等主流二維人體姿態估計Benchmark上均超過了state-of-the-art方法,達到第一名水平,將人體2D姿態估計的準確度推進到全新高度。ASDA作為一種通用的數據增強方法,可以便捷地用在二維人體姿態估計的不同數據集以及不同網絡結構上。
實踐結果表明,優圖的算法在COCO、MPII、LSP三個姿態估計的benchmark達到了最高的水平,圖4-7展示了在以上三個權威數據集上優圖的方法與其他SOTA算法在準確度上的差距。為了方便展示ASDA算法的效果,在COCO測試集進行可視化得到圖3,可以看到優圖的算法能夠有效的解決圖1中的挑戰性案例。
作為騰訊旗下頂級的人工智能實驗室之一,優圖聚焦計算機視覺,專注人臉識別、圖像識別、OCR、機器學習、數據挖掘等領域開展技術研發和行業落地,在推動產業數字化升級過程中,始終堅持基礎研究、產業落地兩條腿走路的發展戰略,與騰訊云與智慧產業深度融合,挖掘客戶痛點,切實為行業降本增效。
在未來,騰訊優圖也將繼續深耕于人體2D姿態估計技術,并將持續探索更多的應用場景和應用空間,讓更多的用戶享受到科技帶來的紅利。
fqj
-
騰訊
+關注
關注
7文章
1644瀏覽量
49400 -
智能算法
+關注
關注
0文章
77瀏覽量
11928
發布評論請先 登錄
相關推薦
LIMS系統在芯片實驗室中的應用
TüV萊茵授予聯想合作實驗室資質
優刻得與聯想AI實驗室攜手共建高效AI資源池
廣和通獲得UL Solutions WTDP目擊實驗室資質

廣和通獲得UL Solutions WTDP目擊實驗室資質
華南檢測中心:實驗室能力驗證平臺

DEKRA德凱廣州新能源實驗室獲得CBTL新認可資質
盛景微獲得CNAS實驗室認可證書
TCL華星與聯想共建創新顯示聯合實驗室
三星在硅谷建立3D DRAM研發實驗室
北匯信息獲得一汽研發總院頒發的外部實驗室認可證書

【愛芯派 Pro 開發板試用體驗】人體姿態估計模型部署前期準備
半導體制冷技術在實驗室儀器中的應用簡介

淺析RFID技術在學校實驗室管理中的應用





 工商網監
工商網監
評論