 通過遷移學習解決計算機視覺問題
通過遷移學習解決計算機視覺問題
來源:公眾號AI公園
作者:OrhanG. Yal??n
編譯:ronghuaiyang
導讀
使用SOTA的預訓練模型來通過遷移學習解決現實的計算機視覺問題。
如果你試過構建高精度的機器學習模型,但還沒有試過遷移學習,這篇文章將改變你的生活。至少,對我來說是的。
我們大多數人已經嘗試過,通過幾個機器學習教程來掌握神經網絡的基礎知識。這些教程非常有助于了解人工神經網絡的基本知識,如循環神經網絡,卷積神經網絡,GANs和自編碼器。但是這些教程的主要功能是為你在現實場景中實現做準備。
現在,如果你計劃建立一個利用深度學習的人工智能系統,你要么(i)有一個非常大的預算用于培訓優秀的人工智能研究人員,或者(ii)可以從遷移學習中受益。
什么是遷移學習?
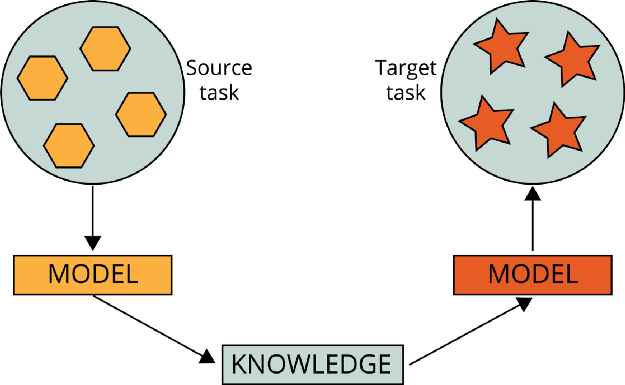
遷移學習是機器學習和人工智能的一個分支,其目的是將從一個任務(源任務)中獲得的知識應用到一個不同但相似的任務(目標任務)中。
例如,在學習對維基百科文本進行分類時獲得的知識可以用于解決法律文本分類問題。另一個例子是利用在學習對汽車進行分類時獲得的知識來識別天空中的鳥類。這些樣本之間存在關聯。我們沒有在鳥類檢測上使用文本分類模型。
遷移學習是指從相關的已經學習過的任務中遷移知識,從而對新的任務中的學習進行改進
總而言之,遷移學習是一個讓你不必重復發明輪子的領域,并幫助你在很短的時間內構建AI應用。
遷移學習的歷史
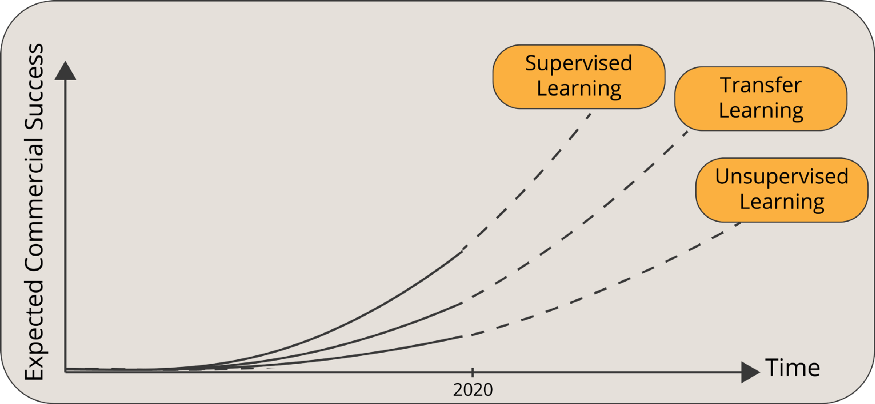
為了展示遷移學習的力量,我們可以引用Andrew Ng的話:
遷移學習將是繼監督學習之后機器學習商業成功的下一個驅動因素
遷移學習的歷史可以追溯到1993年。Lorien Pratt的論文“Discriminability-Based Transfer between Neural Networks”打開了潘多拉的盒子,向世界介紹了遷移學習的潛力。1997年7月,“Machine Learning”雜志發表了一篇遷移學習論文專刊。隨著該領域的深入,諸如多任務學習等相鄰主題也被納入遷移學習領域。“Learning to Learn”是這一領域的先驅書籍之一。如今,遷移學習是科技企業家構建新的人工智能解決方案、研究人員推動機器學習前沿的強大源泉。
遷移學習是如何工作的?
實現遷移學習有三個要求:
由第三方開發開源預訓練模型
重用模型
對問題進行微調
開發開源預訓練模型
預訓練的模型是由其他人創建和訓練來解決與我們類似的問題的模型。在實踐中,幾乎總是有人是科技巨頭或一群明星研究人員。他們通常選擇一個非常大的數據集作為他們的基礎數據集,比如ImageNet或Wikipedia Corpus。然后,他們創建一個大型神經網絡(例如,VGG19有143,667,240個參數)來解決一個特定的問題(例如,這個問題用VGG19做圖像分類。)當然,這個預先訓練過的模型必須公開,這樣我們就可以利用這些模型并重新使用它們。
重用模型
在我們掌握了這些預先訓練好的模型之后,我們重新定位學習到的知識,包括層、特征、權重和偏差。有幾種方法可以將預先訓練好的模型加載到我們的環境中。最后,它只是一個包含相關信息的文件/文件夾。然而,深度學習庫已經托管了許多這些預先訓練過的模型,這使得它們更容易訪問:
TensorFlow Hub
Keras Applications
PyTorch Hub
你可以使用上面的一個源來加載經過訓練的模型。它通常會有所有的層和權重,你可以根據你的意愿調整網絡。
對問題進行微調
現在的模型也許能解決我們的問題。對預先訓練好的模型進行微調通常更好,原因有兩個:
這樣我們可以達到更高的精度。
我們的微調模型可以產生正確的格式的輸出。
一般來說,在神經網絡中,底層和中層通常代表一般的特征,而頂層則代表特定問題的特征。由于我們的新問題與原來的問題不同,我們傾向于刪除頂層。通過為我們的問題添加特定的層,我們可以達到更高的精度。
在刪除頂層之后,我們需要放置自己的層,這樣我們就可以得到我們想要的輸出。例如,使用ImageNet訓練的模型可以分類多達1000個對象。如果我們試圖對手寫數字進行分類(例如,MNIST classification),那么最后得到一個只有10個神經元的層可能會更好。
在我們將自定義層添加到預先訓練好的模型之后,我們可以用特殊的損失函數和優化器來配置它,并通過額外的訓練進行微調。
計算機視覺中的4個預訓練模型
這里有四個預先訓練好的網絡,可以用于計算機視覺任務,如圖像生成、神經風格轉換、圖像分類、圖像描述、異常檢測等:
VGG19
Inceptionv3 (GoogLeNet)
ResNet50
EfficientNet
讓我們一個一個地深入研究。
VGG-19
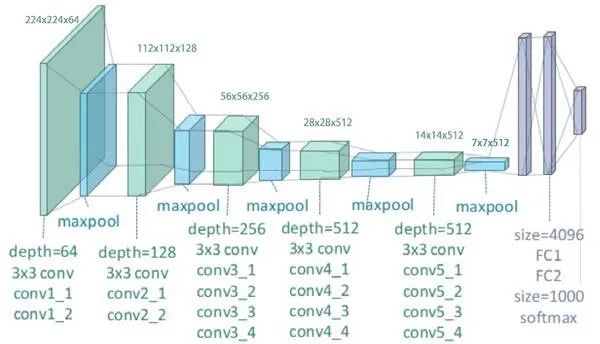
VGG是一種卷積神經網絡,深度為19層。它是由牛津大學的Karen Simonyan和Andrew Zisserman在2014年構建和訓練的,論文為:Very Deep Convolutional Networks for large Image Recognition。VGG-19網絡還使用ImageNet數據庫中的100多萬張圖像進行訓練。當然,你可以使用ImageNet訓練過的權重導入模型。這個預先訓練過的網絡可以分類多達1000個物體。對224x224像素的彩色圖像進行網絡訓練。以下是關于其大小和性能的簡要信息:
大小:549 MB
Top-1 準確率:71.3%
Top-5 準確率:90.0%
參數個數:143,667,240
深度:26
Inceptionv3 (GoogLeNet)
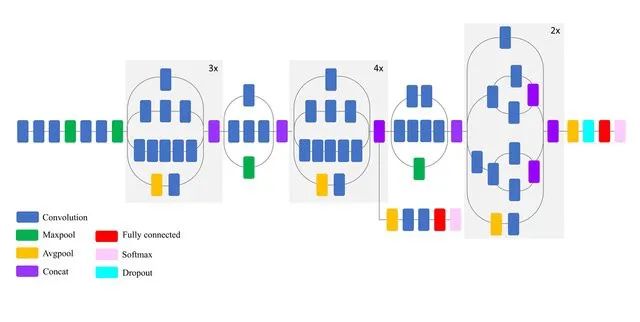
Inceptionv3是一個深度為50層的卷積神經網絡。它是由谷歌構建和訓練的,你可以查看這篇論文:“Going deep with convolutions”。預訓練好的帶有ImageNet權重的Inceptionv3可以分類多達1000個對象。該網絡的圖像輸入大小為299x299像素,大于VGG19網絡。VGG19是2014年ImageNet競賽的亞軍,而Inception是冠軍。以下是對Inceptionv3特性的簡要總結:
尺寸:92 MB
Top-1 準確率:77.9%
Top-5 準確率:93.7%
參數數量:23,851,784
深度:159
ResNet50 (Residual Network)
ResNet50是一個卷積神經網絡,深度為50層。它是由微軟于2015年建立和訓練的,論文:[Deep Residual Learning for Image Recognition](http://deep Residual Learning for Image Recognition /)。該模型對ImageNet數據庫中的100多萬張圖像進行了訓練。與VGG-19一樣,它可以分類多達1000個對象,網絡訓練的是224x224像素的彩色圖像。以下是關于其大小和性能的簡要信息:
尺寸:98 MB
Top-1 準確率:74.9%
Top-5 準確率:92.1%
參數數量:25,636,712
如果你比較ResNet50和VGG19,你會發現ResNet50實際上比VGG19性能更好,盡管它的復雜性更低。你也可以使用更新的版本,如ResNet101,ResNet152,ResNet50V2,ResNet101V2,ResNet152V2。
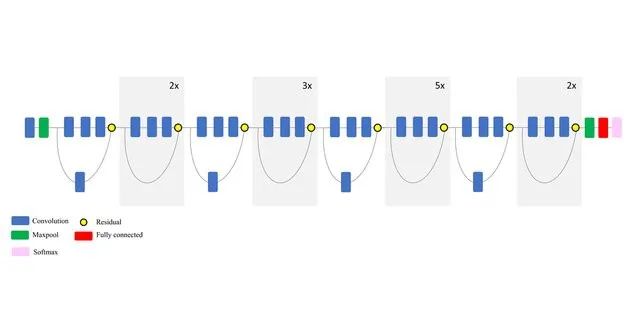
EfficientNet
EfficientNet是一種最先進的卷積神經網絡,由谷歌在2019年的論文“efficient entnet: Rethinking Model Scaling for convolutional neural Networks”中訓練并發布。EfficientNet有8種可選實現(B0到B7),甚至最簡單的EfficientNet B0也是非常出色的。通過530萬個參數,實現了77.1%的最高精度性能。
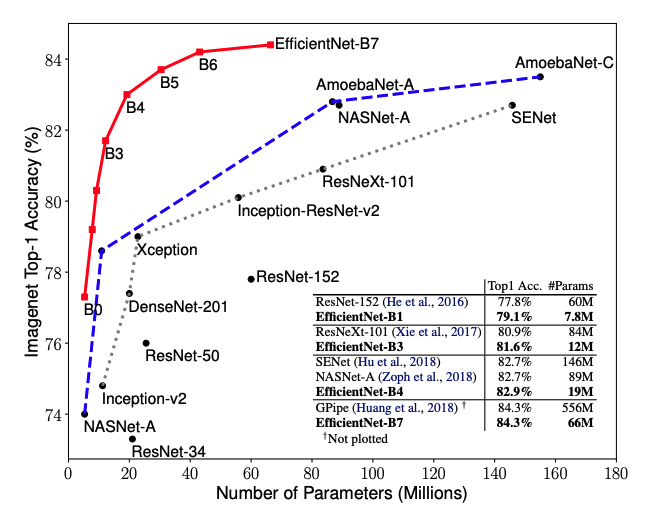
EfficientNetB0的特性簡要介紹如下:
尺寸:29 MB
Top-1 準確率:77.1%
Top-5 準確率:93.3%
參數數量:~5,300,000
深度:159
其他的計算機視覺問題的預訓練模型
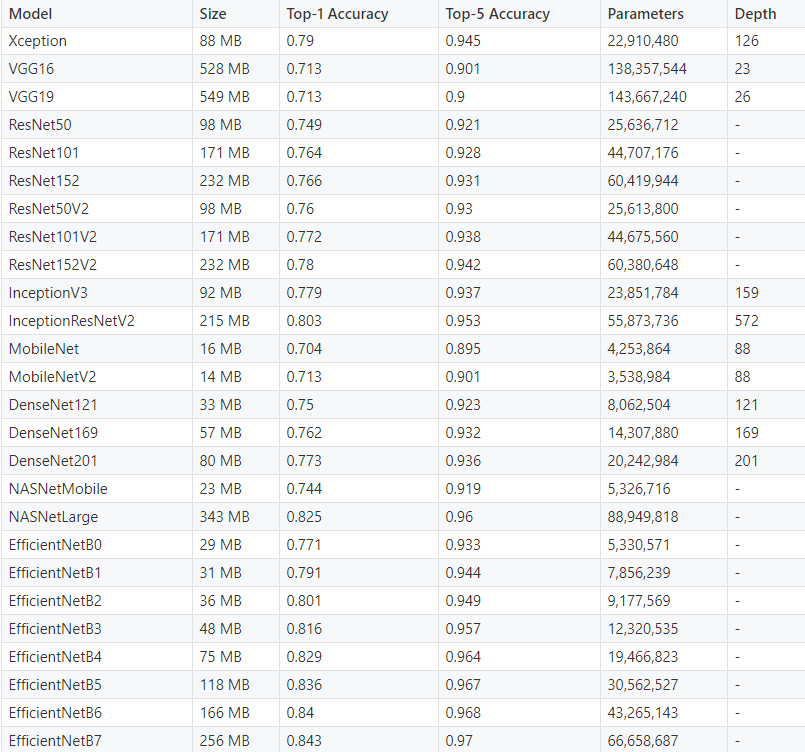
我們列出了四種最先進的獲獎卷積神經網絡模型。然而,還有幾十種其他模型可供遷移學習使用。下面是對這些模型的基準分析,這些模型都可以在Keras Applications中獲得。
總結
在一個我們可以很容易地獲得最先進的神經網絡模型的世界里,試圖用有限的資源建立你自己的模型就像是在重復發明輪子,是毫無意義的。
相反,嘗試使用這些訓練模型,在上面添加一些新的層,考慮你的特殊計算機視覺任務,然后訓練。其結果將比你從頭構建的模型更成功。
原文標題:4個計算機視覺領域常用遷移學習模型
文章出處:【微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
神經網絡
+關注
關注
42文章
4762瀏覽量
100541 -
機器視覺
+關注
關注
161文章
4345瀏覽量
120111 -
機器學習
+關注
關注
66文章
8377瀏覽量
132410
原文標題:4個計算機視覺領域常用遷移學習模型
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
計算機視覺有哪些優缺點
計算機視覺的五大技術
計算機視覺的工作原理和應用
計算機視覺與人工智能的關系是什么
計算機視覺與智能感知是干嘛的
計算機視覺在人工智能領域有哪些主要應用?
機器視覺與計算機視覺的區別
計算機視覺的主要研究方向
計算機視覺的十大算法

最適合 AI 應用的計算機視覺類型是什么?





 工商網監
工商網監
評論