") 對高速信號8B/10B編碼的初步認識
對高速信號8B/10B編碼的初步認識
在高速鏈路中導致接收端眼圖閉合的原因,很大部分并不是由于高頻的損耗太大了,而是由于高低頻的損耗差異過大,導致碼間干擾嚴重,因此不能張開眼睛。針對這種情況,前面有講過可以通過CTLE和FFE(包括DFE)均衡進行解決,原理無非就是衰減低頻幅度或者抬高高頻幅度,從而達到在接收端高低頻均衡的效果。
隔了一段時間,不知道大家還記得我們這個約定嗎?不管你們記不記得,本人肯定沒有忘記哈。現(xiàn)在就把這個關子拿出來講講,也就是今天要說的編碼方式。說到針對于NRZ數據的編碼方式,本人聽過的有4B/5B,8B/10B,64B/66B,64/67B,128B/130B,128B/132B編碼(可能各位還有其他吧),不同的編碼方式針對于不同的信號協(xié)議,當然效率也是不一樣的。
什么叫效率?在數據包傳送的術語叫開銷,意思就是除了實際需要的數據之外的一些數據bit,例如冗余校驗等。那大家看上面的編碼的數值比就知道了,例如8B/10B,要把8bit的實際數據擴展為10B,那開銷就是20%,效率就只有80%了,更通俗來說就是增加了20%的非實際數據的傳輸 。所以一個好的編碼方式,除了看它本身的算法優(yōu)化情況外,還要注重效率高不高。
本人將用兩期的篇章主要介紹下8B/10B和64/66B編碼方式,其他的主要都是由他們擴展開來的。那介紹完前面總體的情況后,進入本期的主題,8B/10B編碼。
首先,為什么要編碼?原來的碼型有什么不好的地方嗎?其中最主要的原因用下面這個圖來進行解釋:
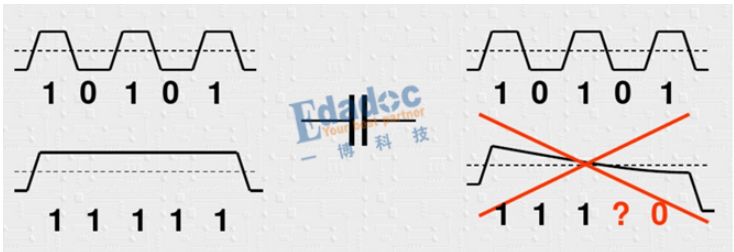
大家看明白了吧,由于我們的串行鏈路中會有交流耦合電容,我們知道理想電容的阻抗公式是Zc=1/2πf*C,因此信號頻率越高,阻抗越低,反之頻率越低,阻抗越高。因此上面的情況,當碼型是高頻的時候,基本上可以不損耗的傳輸過去,但是當碼型為連續(xù)“0”或者“1”的情況時,電容的損耗就很大,導致幅度不斷降低,帶來的嚴重后果是無法識別到底是“1”還是“0”。因此編碼就是為了盡量把低頻的碼型優(yōu)化成較高頻的碼型,從而保證低損耗的傳輸過去。
上面解釋了原因,下面就介紹下這種8B/10B的編碼方式的算法。
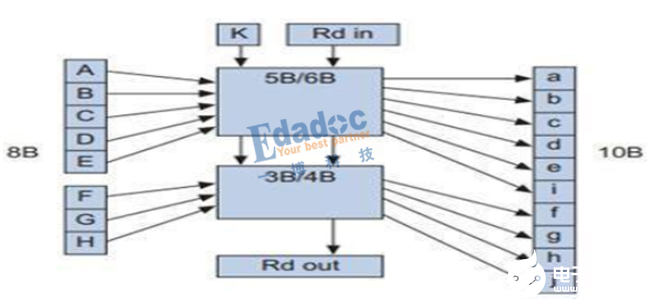
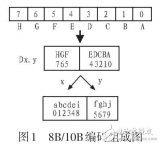
如上圖,關于8B/10B編碼算法有下面幾點需要理解:
1, 低5位(ABCDE)中間加一位,進行5B/6B編碼,高三位(FGH)中間加一位,進行3B/4B編碼;
2, 編碼后的bit僅會出現(xiàn)這三種情況:5個“0”與5個“1”、4個“0”與6個“1”、6個“0”與4個“1”;
3, 有兩個術語要知道:不均等性(disparity)和極性偏差(running disparity,RD)。
不均等性是指編碼后的碼型數據是“1”多還是“0”多,如果是“1”多,則極性偏差RD為-RD,如果是“0”多則為+RD。那定義+-RD有什么意義呢?+-RD代表著同一個碼型的兩種編碼方式。我們本身就是編碼的目標就是為了緩解長“0”或長“1”的影響,因此在編碼后如果“1”多的話,我們下一次的編碼就要把這種碼型做一個修正,因此從-RD碼型變成+RD碼型。如果是“0”和“1”一樣多,極性則不用變,如下圖:

4, 我們怎么知道編碼后映射成什么碼型呢?因此會有一個專門的編碼表,我們只需要在上面找到我們的原始碼型,然后就一目了然了。編碼表如下所示(部分截圖):
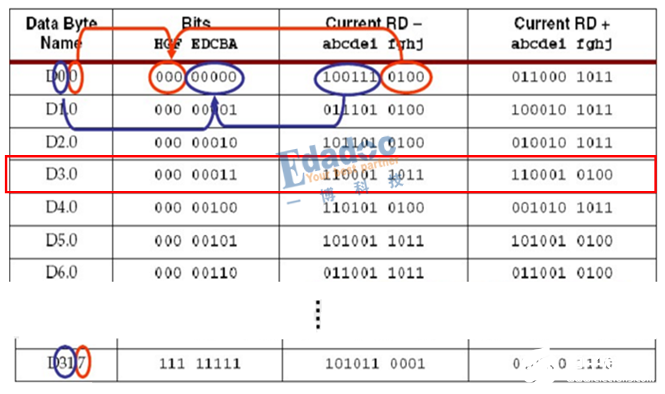
說了那么多,還不如舉個例子更直觀。
我們以上面的D3.0碼型進行仿真驗證:
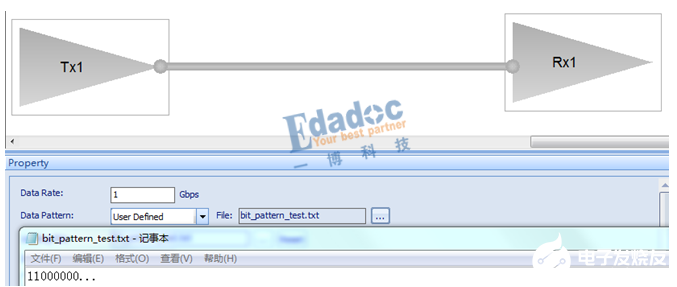
原始的碼型如下:
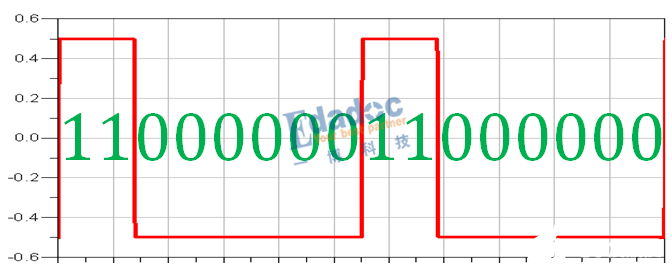
仿真得到8B/10B編碼后的碼型如下:

對照上面的編碼表,結果完全相同,從RD-的模型出發(fā),編碼后RD-的碼型“1”比較多,因此極性變成RD+的編碼碼型,接著RD+的編碼碼型“0”比較多,極性又變回RD-,因此碼型就是RD-和RD+之間循環(huán)下去。
通過上面的介紹,大家對8B/10B編碼有一個初步的認識了吧。
-
阻抗
+關注
關注
17文章
941瀏覽量
45834 -
編碼
+關注
關注
6文章
935瀏覽量
54771 -
高速信號
+關注
關注
1文章
223瀏覽量
17677 -
耦合電容
+關注
關注
2文章
154瀏覽量
19796
發(fā)布評論請先 登錄
相關推薦
8b10b編碼verilog實現(xiàn)
Aurora 8b/10b IP核問題
收發(fā)器向導中啟用8b/10b編碼器的方法是什么?
如何使用Aurora 8B / 10B建立僅傳輸?
怎么禁用Aurora IP Core 8B / 10B中的時鐘補償功能?
基于FPGA的8B/10B編解碼設計
基于PRBS的8B/10B編碼器誤碼率為0設計
基于Virtex-6 的Aurora 8B/10B,PCIe2.0,SRIO 2.0三種串行通信協(xié)議分析
淺談高速信號的64B/66B編碼方式
高速串行通信常用的編碼方式-8b/10b編碼/解碼解析





 工商網監(jiān)
工商網監(jiān)
評論