") 在情感分析中使用知識的一些代表性工作
在情感分析中使用知識的一些代表性工作
1.引文
情感分析 知識
當training數(shù)據(jù)不足以覆蓋inference階段遇到的特征時,是標注更多的數(shù)據(jù)還是利用現(xiàn)有外部知識充當監(jiān)督信號?
基于機器學習、深度學習的情感分析方法,經常會遇到有標注數(shù)據(jù)不足,在實際應用過程中泛化能力差的局面。為了彌補這一缺點,學者們嘗試引入外部情感知識為模型提供監(jiān)督信號,提高模型分析性能。本文從常見的外部情感知識類型出發(fā),簡要介紹在情感分析中使用知識的一些代表性工作。
2.正文
我們?yōu)槭裁匆粩鄧L試在情感分析中融入知識呢?筆者以為有如下幾點原因:
1)一般的文本分類任務只提供句子或文檔級別的情感標簽,引入情感詞典等先驗情感知識可以給情感文本引入更細粒度監(jiān)督信號,使得模型能學到更適合情感分析任務的特征表示。
2)底層的詞性、句法等分析任務能給下游的情感分類、抽取任務提供參考信息,如評價表達通常是形容詞或形容詞短語,而評價對象通常是名詞;不同情感分析任務本身存在相互促進作用,如評價對象和評價詞在句子中出現(xiàn)的距離通常比較近,聯(lián)合抽取能同時提高兩者的性能表現(xiàn)。
3)短文本評論通常略去了大量的背景常識知識,從文本本身通常難以推斷真實情感傾向性。例如一條有關大選的推文內容是“I am so grateful for Joe Biden. Vote for #JoeBiden!!”,文本中并未涉及任何有關Trump的描述,要判斷它關于Trump的立場傾向性時,需要了解的背景知識是,二者是這次大選的競爭對手,支持一個人就意味著反對另一個人。
那情感分析常用的知識又有哪些呢?
2.1 知識的類型及情感分析常用知識庫
依據(jù)對知識獲取途徑的劃分方式[1],我們簡單總結了情感分析中常用的知識類型:
顯性知識
一般情感詞典(如MPQA,Bing Liu詞典等),情感表情符;否定詞(Negation)、強化詞(Intensification)、連接詞(Conjunction)等規(guī)則
SentiWordNet
ConceptNet,SenticNet
數(shù)據(jù)
數(shù)據(jù) (Twitter、微博表情符弱標注數(shù)據(jù))
領域數(shù)據(jù)集 (例如某一類別商品評論數(shù)據(jù))
學習算法
詞法、句法、語義依存等模型
多任務學習算法
預訓練語言模型、詞向量學習算法
其中,以情感詞典最為常用。情感分析數(shù)據(jù)通常結合語言模型算法,產生情感向量表示作為下游任務輸入;詞法、句法分析模型一般直接為下游情感分析任務提供特征輸入或者以多任務學習的方式參與到下游情感分析任務的訓練過程中;結構化的外部知識庫通常需要借助圖算法進行特征挖掘,為文本提供更豐富的常識、情感上下文信息。
2.2 知識的引入方式及在情感分析部分任務上的應用
下表展示了幾種常見的知識類型及其特點,我們將根據(jù)知識的獲取途徑及引入方式,結合具體論文闡述其使用方式。
| 知識類型 | 優(yōu)點 | 缺點 |
|---|---|---|
| 人工情感詞典 | 質量高 | 規(guī)模小,靜態(tài),覆蓋低 |
| 自動情感詞典 | 規(guī)模大 | 靜態(tài)、質量低 |
| 語言學規(guī)則 | 適用范圍廣 | 不夠準確 |
| 預訓練語言模型 | 上下文建模能力強 | 參數(shù)量大,訓練時間長,運行速度慢 |
| 常識知識庫 | 規(guī)模大、質量高、覆蓋全 | 利用困難 |
目前,相關的情感分析工作可以大致分為以下幾類:
引入情感詞典知識
要說情感知識,大部分人首先會想到的就是人工編纂的情感詞典,它簡明直觀、質量高、極性明確,使用方便,廣泛應用在情感分類、情感元素抽取、情感原因發(fā)現(xiàn)、情感文本風格遷移等多種情感分析任務上。情感詞區(qū)別于非情感詞的地方在于,它們一般表征一定的情感/情緒狀態(tài),通常情感詞典中還會給出其強度打分。類似的,現(xiàn)在網(wǎng)絡上流行的部分表情符 (emoj,如:) 、:( 、、)也能表征某些情感/情緒狀態(tài)。
圖1 人工編纂的情感詞典
我們在這里介紹一個同時使用情感詞典中詞的極性和打分的工作,看看前人們是如何在神經網(wǎng)絡中把情感詞的情感信息融入文本的情感表示中的。
給定一段評論文本,Teng等人[2]首先找出其中的情感相關詞匯(如情感詞、轉折詞、否定詞),并計算其對文本整體情感極性的貢獻程度,然后將每個詞的貢獻值乘上其情感得分作為局部的情感極性值,最終加上全局的情感極性預測值作為整個文本的情感得分。
圖2 同時使用情感詞典中詞的極性和打分
雖然上述工作在計算情感得分時,考慮了not、very等否定詞、強化詞的得分信息,但是沒有顯式把這些詞對周圍詞的情感語義表示的影響刻畫出來,Qian等人[3]考慮到情感詞、否定詞、強化詞在情感語義組合過程中起到的不同作用,對文本建模過程中對不同位置詞的情感分布加以約束。例如,若一個詞的上文是not等否定詞,會帶來not處文本情感語義的翻轉。
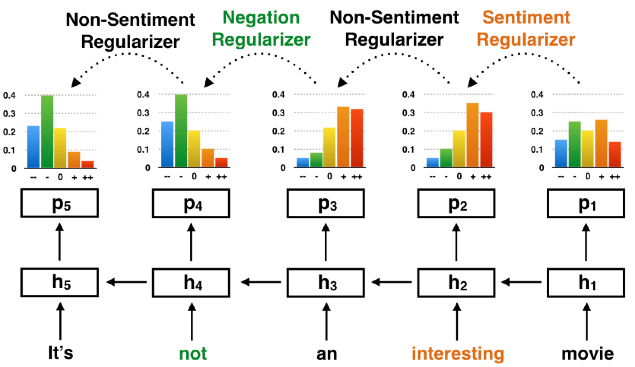
圖3 對不同位置詞的情感分布加以約束
總體來看,情感詞典作為一種易于獲取、極性準確的情感知識,能夠在標注語料之外,為情感分析提供額外的監(jiān)督信號,既可以提升有監(jiān)督模型的泛化能力,也能夠為半監(jiān)督、無監(jiān)督模型提供一定的指導。
引入大規(guī)模無標注語料
語言建模作為一個典型的自監(jiān)督學習任務,其語言模型產生的詞表示作為下游任務網(wǎng)絡模型的輸入,表現(xiàn)出優(yōu)越的性能,因而得到廣泛的應用。如果能將情感知識融入到語言模型中,其產生的詞表示必然對情感分析各子任務帶來性能提升。
我們接著介紹一個在詞向量中融入顯式情感詞典知識(實際使用的是表情符)的方法。
Tang等人[4]觀察到,一般的詞向量對于“good”和“bad”這種上下文相近但極性相反的詞,給出的向量表示沒有很強的區(qū)分性,不利于下游的各情感分析任務。Twitter和微博中有海量包含表情符的文本,利用這些情感極性明確的表情符可以過濾得到大量弱標注的情感文本。Tang等人使用這些語料,他們在普通的C&W模型基礎上,引入情感得分相關的損失,將這些弱標注的情感信息融入詞向量表示中,使“good”和“bad”這種上下文相近但情感不同的詞的向量表示有明顯的差異。在情感分類任務上,他們驗證了融入情感表情符知識的有效性。在此基礎上,他們還進一步自動構建大規(guī)模情感詞典,該詞典被[2]應用到Twitter情感分類任務上。
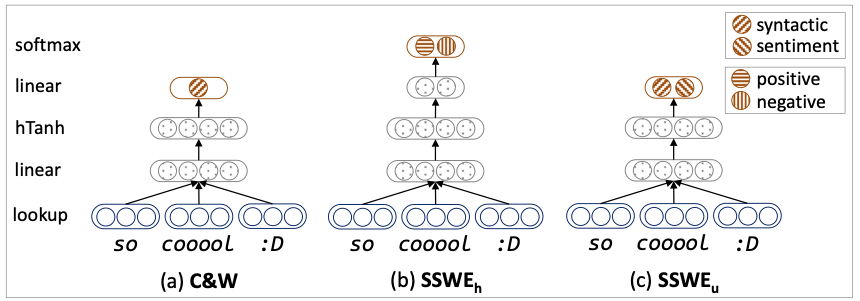
圖4 將基于表情符過濾的弱標注情感信息融入詞向量表示中
引入外部特征提取算法
除了準確的情感詞知識,詞法、句法、語義依存信息、評價詞和評價表達等情感信息在文本的情感語義建模過程中也發(fā)揮了重要作用,這些知識不是顯性存在于大規(guī)模的知識圖譜中,而是存在于對應的人工標注數(shù)據(jù)中。一般利用學習算法從這些數(shù)據(jù)中訓練用于提取特征的模型。
Tian等人[5]在近期的預訓練BERT語言模型基礎上,將文本中的評價對象(屬性)、情感詞等情感元素引入Mask Language Model預訓練任務,進一步提高了BERT類模型在多個情感分類數(shù)據(jù)集上的性能。

圖5 將多種情感元素引入Mask Language Model預訓練任務 同[3]類似,Ke等人[6]在預訓練語言模型中引入詞級別的情感、詞性知識。他們先給每個詞預測詞性信息,然后依據(jù)詞性信息從SentiWordNet中推斷其情感極性。基于獲得的詞性和情感信息,他們在一般的Masked Language Model基礎上同時預測這些語言學標簽,實現(xiàn)在預訓練語言模型中注入情感知識。該模型在主流的情感分類、細粒度情感分析數(shù)據(jù)集上取得了目前最好的結果,證明引入詞性和情感極性知識在預訓練任務中的有效性。
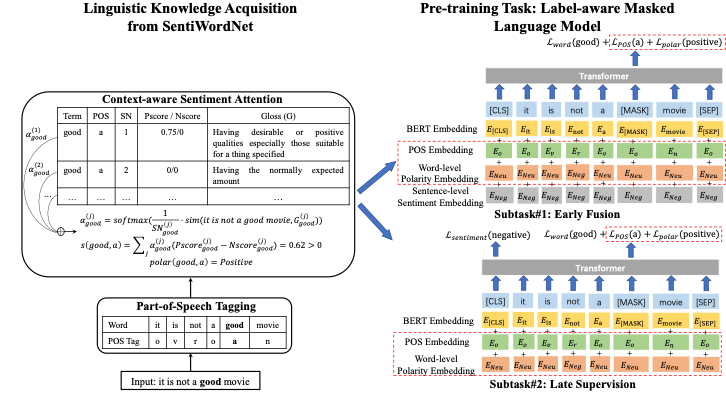
圖6在預訓練語言模型中引入詞級別的情感、詞性知識
Sun等人[7]提出在面向屬性的情感分類(ABSA)任務上,引入Stanford parser解析得到的依存樹信息輔助識別評價對象相關的評價詞。他們將GCN在依存樹上學習得到的表示與BLSTM學習到的特征結合,判斷句子針對評價對象的情感極性。
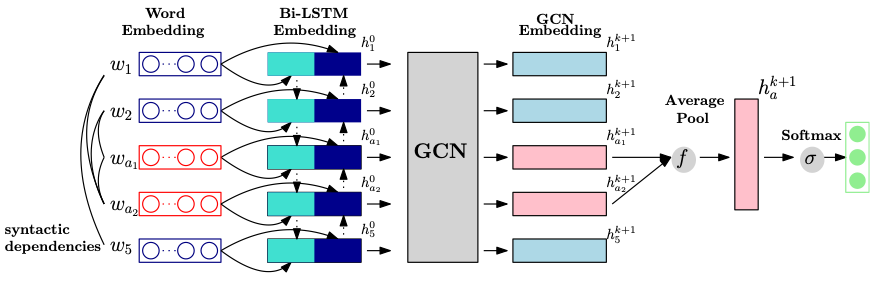
圖7將GCN在依存樹上學習得到的表示與BLSTM學習到的特征結合
在外部特征引入方式上,目前方法以兩種方法為主:(1)直接作為特征輸入模型(2)以多任務學習的方式,作為輔助任務與主任務一同訓練。這些方法的區(qū)別主要在引入特征類別或者輔助任務的任務設計。
引入常識知識
除了情感詞典、情感詞向量、情感預訓練語言模型、文本特征抽取器外,結構化的外部知識也是很常見的一種情感知識來源。它的特點是規(guī)模大,覆蓋面廣,蘊含豐富的實體、事件或者常識概念間相關關系知識。結構化知識中具備高質量的關系類型,因而適用于需要推理、泛化的情感分析任務。
一個典型的需要泛化的任務是跨領域文本情感分類任務。源端和目標端的評價對象、評價詞等情感相關特征差異較大,訓練時模型依賴的源端分類特征未必會在目標端文本中出現(xiàn),如何將這些情感特征進行對齊是一個重要且富有挑戰(zhàn)性的問題。一類方法是使用通用情感詞典作為pivot信息,建立源端、目標端共享特征的對齊,但這類方法只考慮共享的情感詞信息,且通過文本本身學習到的情感表達對齊也不充分、準確,同時無法捕獲到不同領域之間評價對象之間鏈接關系。
而結構化外部知識正好彌補了這些缺點,它蘊含情感詞到非情感詞、不同領域評價對象之間的關聯(lián)關系。近年由于圖表示算法的進步,學者們能夠更高效的對這些結構化外部知識加以利用。
在跨領域情感文檔情感分類任務上,Ghosal等人[8]在ACL2020上提出KinGDOM算法, 利用ConceptNet為所有領域構建一個小規(guī)模知識圖譜,然后找出每個文檔中獨有的名詞、形容詞、副詞集合,再依據(jù)從中抽取出一個文檔相關的子圖,進而提供一個由知識庫知識提取而來的特征表示,與文檔本身的情感表示一起做最后的情感分類。
圖8KinGDOM算法
類似地,在跨目標立場分類任務上,Zhang等人[9]利用SenticNet和EmoLex構建學習帶情緒關系連接的語義-情緒圖譜(SE-graph),并使用圖卷積神經網(wǎng)絡(GCN)學習節(jié)點表示。給定一段文本,他們使用SE-graph為每個詞學習構建一個子圖并學習其表示,得到的外部特征表示送入修改后的BLSTM隱層,與當前上下文特征進行融合。
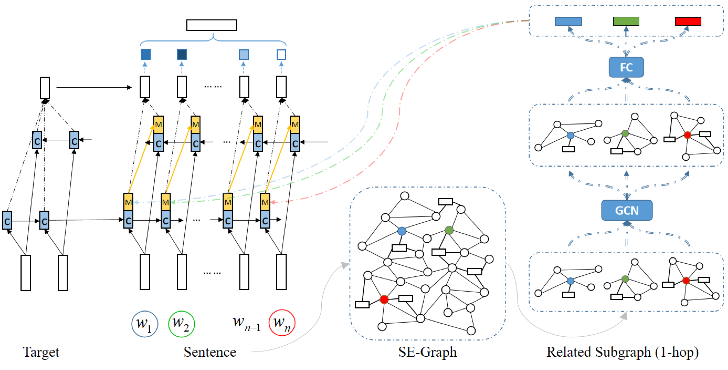
圖9基于SE-graph 使用GCN學習節(jié)點表示
這兩個工作都使用外部結構知識,擴展了輸入特征空間,利用知識庫中的連接將源端和目標端的評價詞、評價對象等特征進行對齊,極大地豐富了情感上下文信息。
3.總結
本文介紹了情感分析中引入外部知識的部分工作,簡要介紹了現(xiàn)階段情感分析常用的外部知識,從最常見的情感詞典入手,逐步介紹基于情感詞典的情感詞向量、預訓練語言模型,展示了使用多任務學習融合詞性、依存句法等文本底層特征抽取器的工作,最后介紹了近期熱門的使用結構化外部知識的文本情感遷移學習工作。我們可以看出,情感詞典雖然最為簡單,卻是情感知識引入多種引入方式的基石,在情感分析算法中地位無出其右。
對于未來工作,一方面,由于目前的情感分析中知識引入的應用場景仍局限在情感分類任務中,有待擴展到情感抽取、情感(多樣性)生成等各個情感分析任務上;另一方面,在情感分析專用預訓練語言模型中融合結構化外部知識,增強預訓練語言模型對情感分析相關世界知識的理解仍有待探索。
[1]
劉挺,車萬翔. 自然語言處理中的知識獲取問題.
[2]
Teng et al. Context-Sensitive Lexicon Features for Neural Sentiment Analysis.
[3]
Qian et al. Linguistically Regularized LSTM for Sentiment Classi?cation.
[4]
Tang et al. Learning Sentiment-Speci?c Word Embedding for Twitter Sentiment Classi?cation.
[5]
Tian et al.SKEP: Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis.
[6]
Xu et al.SentiLARE: Sentiment-Aware Language Representation Learning with Linguistic Knowledge.
[7]
Sun et al.Aspect-Level Sentiment Analysis Via Convolution over Dependency Tree.
[8]
Ghosal et al.KinGDOM: Knowledge-Guided DOMain Adaptation for Sentiment Analysis.
[9]
Zhang et al.Enhancing Cross-target Stance Detection with Transferable Semantic-Emotion Knowledge.
責任編輯:xj
原文標題:基于知識引入的情感分析
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
-
機器學習
+關注
關注
66文章
8381瀏覽量
132431 -
深度學習
+關注
關注
73文章
5493瀏覽量
120992 -
情感分析
+關注
關注
0文章
14瀏覽量
5234
原文標題:基于知識引入的情感分析
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
一些半導體的基礎知識

一些常見的動態(tài)電路

基于LSTM神經網(wǎng)絡的情感分析方法
分享一些常見的電路
在設計中使用MOSFET安全工作區(qū)曲線

為什么在一些路由器中使用ESP32的Active mode無法接收服務器的TCP數(shù)據(jù)呢?
細談SolidWorks教育版的一些基礎知識
淺談ADI推動汽車行業(yè)發(fā)展的一些應用場景

對于大模型RAG技術的一些思考





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論