 如何在BERT中引入知識圖譜中信息
如何在BERT中引入知識圖譜中信息
引言
隨著BERT等預訓練模型橫空出世,NLP方向迎來了一波革命,預訓練模型在各類任務上均取得了驚人的成績。隨著各類預訓練任務層出不窮,也有部分研究者考慮如何在BERT這一類模型中引入或者強化知識圖譜中包含的信息,進而增強BERT對背景知識或常識信息的編碼能力。本文主要關注于如何在BERT中引入知識圖譜中信息,并survey了目前已公布的若干種方法,歡迎大家批評和交流。
ERNIE: Enhanced Language Representation with Informative Entities
論文鏈接:https://www.aclweb.org/anthology/P19-1139.pdf
這篇論文來自于清華劉知遠老師和華為劉群老師,已被ACL2019所錄取,是較早的考慮將知識引入預訓練模型的論文。
該論文主要利用了從知識庫中提出的高信息量的實體信息,通過特殊的語義融合模塊,來增強文本中對應的表示。首先本文通過實體鏈接算法,將Wikipedia文本中包含的實體與Wikidata中的實體庫構建關聯,然后采用TransE算法,對Wikidata中的實體embedding進行預訓練,進而得到其初始的表示;之后本文采用一個特殊的信息融合結構,其模型框架如下圖所示:

從圖中可以看出,ERNIE的框架分為以下兩部分,T-Encoder和K-Encoder,以上兩部分均使用BERT的Transformer框架,并利用其中的參數進行初始化。其中Wikipedia中的每一句話首先被輸入給T-Encoder,其通過Transformer的多頭注意力機制對文本中的信息進行編碼;之后輸出的表示與其內部包含的實體被一起輸入給了K-Encoder,其內部包含兩個多頭注意力層以分別對文本信息和實體信息進行編碼;編碼后實體信息會得到兩種表示——詞級別和實體級別的表示,ERNIE通過將兩種信息concat之后輸入給DNN層,進而融合得到知識增強的表示;為進一步促進該部分融合,ERNIE采用一個denoising entity auto-encoder (dEA)來對該部分進行監督,其采用類似于BERT中的Mask機制,基于一定的概率對其中的實體進行mask或替換,然后還原該部分實體信息。
在采用以上過程預訓練后,本文將ERNIE在多個NLP任務上進行微調,并在多個數據集上獲得了State-of-the-art的結果。
K-BERT: Enabling Language Representation with Knowledge Graph
論文鏈接:https://arxiv.org/pdf/1909.07606v1.pdf
這篇論文來自于北大和騰訊,已被AAAI2020所錄取,是較早的考慮將知識圖譜中的邊關系引入預訓練模型的論文。
該論文主要通過修改Transformer中的attention機制,通過特殊的mask方法將知識圖譜中的相關邊考慮到編碼過程中,進而增強預訓練模型的效果。首先本文利用CN-DBpedia、HowNet和MedicalKG作為領域內知識圖譜,對每一個句子中包含的實體抽取其相關的三元組,這里的三元組被看作是一個短句(首實體,關系,尾實體),與原始的句子合并一起輸入給Transformer模型;針對該方法,本文采用基于可見矩陣的mask機制,如下圖所示:
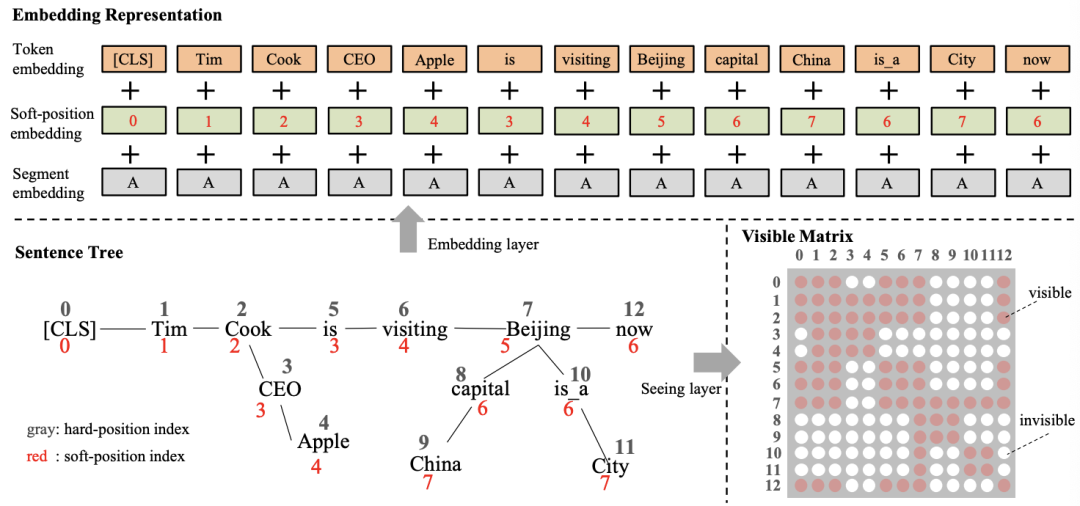
從圖中可以看出,輸入的句子增加了許多三元組構成的短句,在每次編碼時針對每一個詞,模型通過可視矩陣(0-1變量)來控制該詞的視野,使其計算得到的attention分布不會涵蓋與其無關的詞,進而模擬一個句子樹的場景;由于該策略僅僅改動了mask策略,故其可以支持BERT,RoBERTa等一系列模型;該方法最終在8個開放域任務和4個特定領域任務下取得了一定的提升。
KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation
論文鏈接:https://arxiv.org/pdf/1911.06136.pdf
這篇論文來源于清華和Mila實驗室,其主要關注于如何使用BERT增強知識圖譜embedding,并幫助增強對應的表示。
該論文主要通過添加類似于TransE的預訓練機制來增強對應文本的表示,進而增強預訓練模型在一些知識圖譜有關任務的效果。首先本文基于Wikipedia和Wikidata數據集,將每個entity與對應的維基百科描述相鏈接,則每個entity均獲得其對應的文本描述信息;之后對于每一個三元組——<頭實體,關系,尾實體>,本文采用基于BERT對encoder利用entity的描述信息,對每個實體進行編碼,如下圖所示:
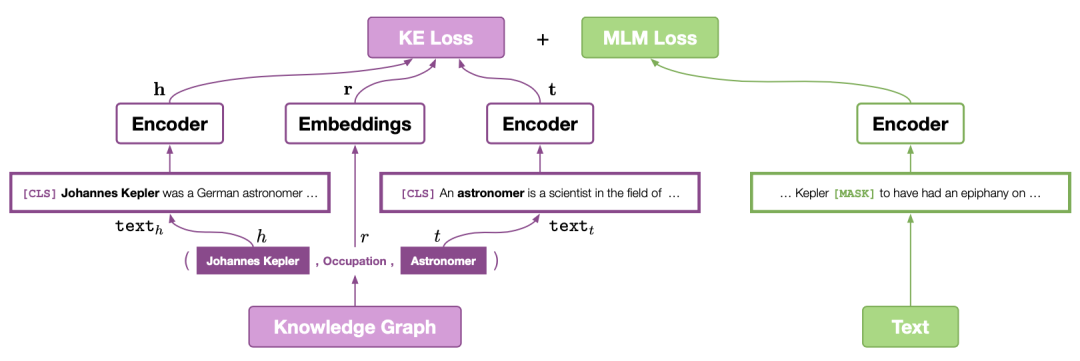
從圖中可以看出,在通過encoder得到頭實體和尾實體對應的表示之后,本文采用類似于TransE的訓練方法,即基于頭實體和關系預測尾實體;此外本文還采用BERT經典的MLM損失函數,并使用RoBERTa的原始參數進行初始化;最終本文提出的方法在知識圖譜補全和若干NLP任務上均帶來了增益。
CoLAKE: Contextualized Language and Knowledge Embedding
論文鏈接:https://arxiv.org/pdf/2010.00309.pdf
這篇論文來源于復旦和亞馬遜,其主要關注于如何使用知識圖譜以增強預訓練模型的效果。
本文首先將上下文看作全連接圖,并根據句子中的實體在KG上抽取子圖,通過兩個圖中共現的實體將全連接圖和KG子圖融合起來;然后本文將該圖轉化為序列,使用Transformer進行預訓練,并在訓練時采用特殊的type embedding來表示實體、詞語與其他子圖信息,如下圖所示:

最終本文將文本上下文和知識上下文一起用MLM進行預訓練,將mask的范圍推廣到word、entity和relation;為訓練該模型,本文采用cpu-gpu混合訓練策略結合負采樣機制減少訓練時間;最終本文提出的方法在知識圖譜補全和若干NLP任務上均帶來了增益。
Exploiting Structured Knowledge in Text via Graph-Guided Representation Learning
論文鏈接:https://arxiv.org/pdf/2004.14224.pdf
這篇論文來源于悉尼科技大學和微軟,其主要關注于如何使用知識圖譜增強預訓練模型。
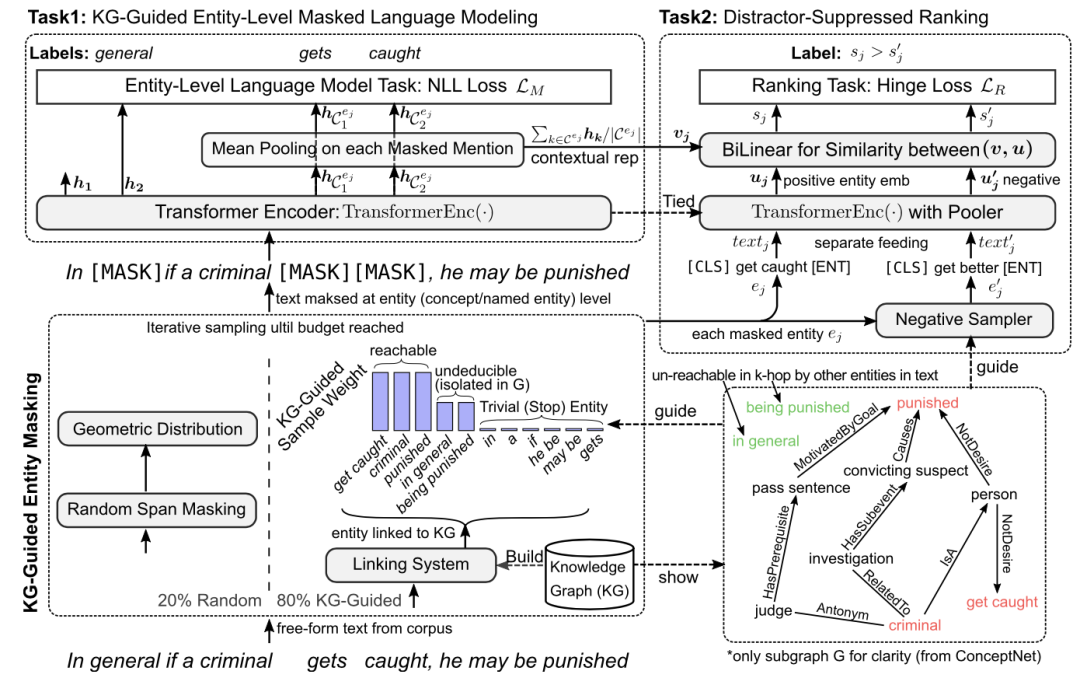
本文思路比較簡潔,其提出了一個基于entity的mask機制,結合一定的負采樣機制來增強模型。首先對于輸入的每一句話,本文首先進行實體鏈接工作,得到其中的entity,并從知識圖譜conceptnet和freebase中召回其鄰接的三元組;本文利用一個特殊的權重,防止在mask時關注于句子中過于簡單和過于難的entity,這樣模型在entity-level MLM訓練時就關注于較為適合學習的信息;此外本文還引入了基于知識圖譜的負采樣機制,其利用relation來選擇高質量的負例,以進一步幫助訓練;最終本文提出的方法在知識圖譜補全和若干NLP任務上均帶來了增益。
K-ADAPTER: Infusing Knowledge into Pre-Trained Models with Adapters
論文鏈接:https://arxiv.org/pdf/2002.01808v3.pdf
這篇論文來源于復旦和微軟,其考慮自適應的讓BERT與知識相融合。
這篇論文考慮如何通過不同的特殊下游任務來幫助向預訓練模型融入任務相關的知識。首先本文針對不同的預訓練任務,定義了對應的adapter;在針對具體的下游任務進行fine-tune時,可以采用不同的adapter來針對性的加入特征,進而增強其效果;如下圖所示:
基于該思想,本文提出了兩種特殊的adapter,分別利用factor knowledge和linguistic knowledge;針對這兩個adapter,本文提出了針對entity之間的關系分類任務和基于依存關系的分類任務;再fine-tune階段,兩個adapter得到的特征可以與BERT或RoBERTa得到的特征一起拼接來進行預測,該策略在三個知識驅動數據集上均取得了較大增益。
Integrating Graph Contextualized Knowledge into Pre-trained Language Models
論文鏈接:https://arxiv.org/pdf/1912.00147.pdf
這篇論文來自于華為和中科大,其主要關注于如何將上下文有關的知識信息加入到預訓練模型里。
這篇論文的思想類似于graph-BERT和K-BERT,其針對給出文本首先檢索返回相關的entity三元組,再在知識圖譜上搜集其相鄰的節點以構成子圖;然后將該子圖轉換成序列的形式,輸入給傳統的Transformer模型(類似graph-BERT),通過特殊的mask來約束注意力在相鄰節點上(K-BERT);最后用類似于ERNIE的策略將子圖中的信息加入到Transformer中;最終該模型在下游的幾個醫療相關數據集上取得了增益。
JAKET: Joint Pre-training of Knowledge Graph and Language Understanding
論文鏈接:https://arxiv.org/pdf/2010.00796.pdf
這篇論文來自于CMU和微軟,其主要關注于如何同時對知識圖譜和語言模型一起預訓練。
本文使用RoBERTa作為語言模型對文本進行編碼,增加了relation信息的graph attention模型來對知識圖譜進行編碼;由于文本和知識圖譜的交集在于其中共有的若干entity,本文采用一種交替訓練的方式來幫助融合兩部分的知識,如下圖所示:

可以看出,語言模型得到的信息會首先對輸入文本以及entity/relation的描述信息進行編碼,以得到對應的表示;之后語言模型得到的entity embedding會被送給R-GAT模型以聚合鄰居節點的信息,以得到更強的entity表示;然后該部分信息會被輸入給語言模型繼續融合并編碼,以得到強化的文本表示信息;為了訓練該模型,本文還采用embedding memory機制來控制訓練時梯度的更新頻率和優化目標的權重,并提出四種特殊的損失函數來進行預訓練;最終本文提出的模型在多個知識驅動的下游任務均取得較好效果。
責任編輯:xj
原文標題:BERT meet Knowledge Graph:預訓練模型與知識圖譜相結合的研究進展
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
-
深度學習
+關注
關注
73文章
5492瀏覽量
120975 -
知識圖譜
+關注
關注
2文章
132瀏覽量
7693 -
訓練模型
+關注
關注
1文章
35瀏覽量
3802
原文標題:BERT meet Knowledge Graph:預訓練模型與知識圖譜相結合的研究進展
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
58大新質生產力產業鏈圖譜

三星自主研發知識圖譜技術,強化Galaxy AI用戶體驗與數據安全
易智瑞榮獲“信息技術應用創新工作委員會技術活動單位”

放大電路中引入反饋的作用
三星電子將收購英國知識圖譜技術初創企業
知識圖譜與大模型之間的關系
如何在idf工程中引入mdf WiFi-Mesh函數?
維智科技入選《2024中國數據智能產業圖譜1.0》

如何在啟動軟件時將信息存儲在非易失性存儲器中,以便在COLD PORST之后恢復?
利用知識圖譜與Llama-Index技術構建大模型驅動的RAG系統(下)

知識圖譜基礎知識應用和學術前沿趨勢
中軟國際成功上榜信通院《數據治理產業圖譜2.0》,全面滿足數據治理全鏈路需求







 工商網監
工商網監
評論