 十三個MySQL的經典面試題免費下載
十三個MySQL的經典面試題免費下載
想進大廠,mysql不會那可不行,來接受mysql面試挑戰吧,看看你能堅持到哪里?
1. 能說下myisam 和 innodb的區別嗎?
myisam引擎是5.1版本之前的默認引擎,支持全文檢索、壓縮、空間函數等,但是不支持事務和行級鎖,所以一般用于有大量查詢少量插入的場景來使用,而且myisam不支持外鍵,并且索引和數據是分開存儲的。
innodb是基于聚簇索引建立的,和myisam相反它支持事務、外鍵,并且通過MVCC來支持高并發,索引和數據存儲在一起。
2. 說下mysql的索引有哪些吧,聚簇和非聚簇索引又是什么?
索引按照數據結構來說主要包含B+樹和Hash索引。
假設我們有張表,結構如下:
create table user( id int(11) not null, age int(11) not null, primary key(id), key(age));
B+樹是左小右大的順序存儲結構,節點只包含id索引列,而葉子節點包含索引列和數據,這種數據和索引在一起存儲的索引方式叫做聚簇索引,一張表只能有一個聚簇索引。假設沒有定義主鍵,InnoDB會選擇一個唯一的非空索引代替,如果沒有的話則會隱式定義一個主鍵作為聚簇索引。

這是主鍵聚簇索引存儲的結構,那么非聚簇索引的結構是什么樣子呢?非聚簇索引(二級索引)保存的是主鍵id值,這一點和myisam保存的是數據地址是不同的。
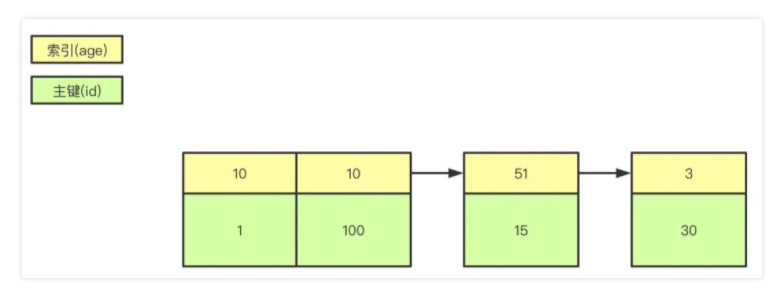
最終,我們一張圖看看InnoDB和Myisam聚簇和非聚簇索引的區別

3. 那你知道什么是覆蓋索引和回表嗎?
覆蓋索引指的是在一次查詢中,如果一個索引包含或者說覆蓋所有需要查詢的字段的值,我們就稱之為覆蓋索引,而不再需要回表查詢。
而要確定一個查詢是否是覆蓋索引,我們只需要explain sql語句看Extra的結果是否是“Using index”即可。
以上面的user表來舉例,我們再增加一個name字段,然后做一些查詢試試。
explain select * from user where age=1; //查詢的name無法從索引數據獲取explain select id,age from user where age=1; //可以直接從索引獲取
4. 鎖的類型有哪些呢
mysql鎖分為共享鎖和排他鎖,也叫做讀鎖和寫鎖。
讀鎖是共享的,可以通過lock in share mode實現,這時候只能讀不能寫。
寫鎖是排他的,它會阻塞其他的寫鎖和讀鎖。從顆粒度來區分,可以分為表鎖和行鎖兩種。
表鎖會鎖定整張表并且阻塞其他用戶對該表的所有讀寫操作,比如alter修改表結構的時候會鎖表。
行鎖又可以分為樂觀鎖和悲觀鎖,悲觀鎖可以通過for update實現,樂觀鎖則通過版本號實現。
5. 你能說下事務的基本特性和隔離級別嗎?
事務基本特性ACID分別是:
原子性指的是一個事務中的操作要么全部成功,要么全部失敗。
一致性指的是數據庫總是從一個一致性的狀態轉換到另外一個一致性的狀態。比如A轉賬給B100塊錢,假設中間sql執行過程中系統崩潰A也不會損失100塊,因為事務沒有提交,修改也就不會保存到數據庫。
隔離性指的是一個事務的修改在最終提交前,對其他事務是不可見的。
持久性指的是一旦事務提交,所做的修改就會永久保存到數據庫中。
而隔離性有4個隔離級別,分別是:
read uncommit 讀未提交,可能會讀到其他事務未提交的數據,也叫做臟讀。
用戶本來應該讀取到id=1的用戶age應該是10,結果讀取到了其他事務還沒有提交的事務,結果讀取結果age=20,這就是臟讀。
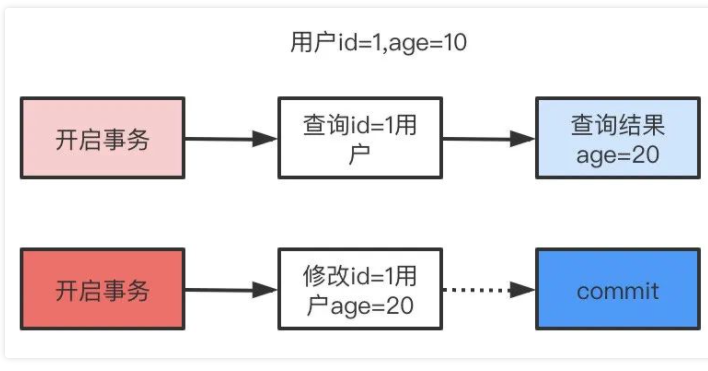
read commit 讀已提交,兩次讀取結果不一致,叫做不可重復讀。
不可重復讀解決了臟讀的問題,他只會讀取已經提交的事務。
用戶開啟事務讀取id=1用戶,查詢到age=10,再次讀取發現結果=20,在同一個事務里同一個查詢讀取到不同的結果叫做不可重復讀。
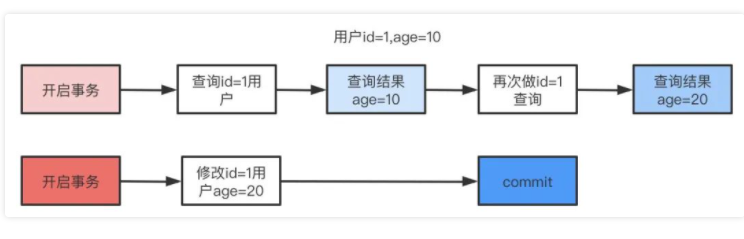
repeatable read 可重復復讀,這是mysql的默認級別,就是每次讀取結果都一樣,但是有可能產生幻讀。
serializable 串行,一般是不會使用的,他會給每一行讀取的數據加鎖,會導致大量超時和鎖競爭的問題。
6. 那ACID靠什么保證的呢?
A原子性由undo log日志保證,它記錄了需要回滾的日志信息,事務回滾時撤銷已經執行成功的sql
C一致性一般由代碼層面來保證
I隔離性由MVCC來保證
D持久性由內存+redo log來保證,mysql修改數據同時在內存和redo log記錄這次操作,事務提交的時候通過redo log刷盤,宕機的時候可以從redo log恢復
7. 那你說說什么是幻讀,什么是MVCC?
要說幻讀,首先要了解MVCC,MVCC叫做多版本并發控制,實際上就是保存了數據在某個時間節點的快照。
我們每行數實際上隱藏了兩列,創建時間版本號,過期(刪除)時間版本號,每開始一個新的事務,版本號都會自動遞增。
還是拿上面的user表舉例子,假設我們插入兩條數據,他們實際上應該長這樣。
idnamecreate_versiondelete_version
1張三1
2李四2
這時候假設小明去執行查詢,此時current_version=3
select * from user where id《=3;
同時,小紅在這時候開啟事務去修改id=1的記錄,current_version=4
update user set name=‘張三三’ where id=1;
執行成功后的結果是這樣的
idnamecreate_versiondelete_version
1張三1
2李四2
1張三三4
如果這時候還有小黑在刪除id=2的數據,current_version=5,執行后結果是這樣的。
idnamecreate_versiondelete_version
1張三1
2李四25
1張三三4
由于MVCC的原理是查找創建版本小于或等于當前事務版本,刪除版本為空或者大于當前事務版本,小明的真實的查詢應該是這樣
select * from user where id《=3 and create_version《=3 and (delete_version》3 or delete_version is null);
所以小明最后查詢到的id=1的名字還是‘張三’,并且id=2的記錄也能查詢到。這樣做是為了保證事務讀取的數據是在事務開始前就已經存在的,要么是事務自己插入或者修改的。
明白MVCC原理,我們來說什么是幻讀就簡單多了。舉一個常見的場景,用戶注冊時,我們先查詢用戶名是否存在,不存在就插入,假定用戶名是唯一索引。
小明開啟事務current_version=6查詢名字為‘王五’的記錄,發現不存在。
小紅開啟事務current_version=7插入一條數據,結果是這樣:
idNamecreate_versiondelete_version
1張三1
2李四2
3王五7
小明執行插入名字‘王五’的記錄,發現唯一索引沖突,無法插入,這就是幻讀。
8. 那你知道什么是間隙鎖嗎?
間隙鎖是可重復讀級別下才會有的鎖,結合MVCC和間隙鎖可以解決幻讀的問題。我們還是以user舉例,假設現在user表有幾條記錄
idAge
110
220
330
當我們執行:
begin;select * from user where age=20 for update;begin;insert into user(age) values(10); #成功insert into user(age) values(11); #失敗insert into user(age) values(20); #失敗insert into user(age) values(21); #失敗insert into user(age) values(30); #失敗
只有10可以插入成功,那么因為表的間隙mysql自動幫我們生成了區間(左開右閉)
(negative infinity,10],(10,20],(20,30],(30,positive infinity)
由于20存在記錄,所以(10,20],(20,30]區間都被鎖定了無法插入、刪除。
如果查詢21呢?就會根據21定位到(20,30)的區間(都是開區間)。
需要注意的是唯一索引是不會有間隙索引的。
9. 你們數據量級多大?分庫分表怎么做的?
首先分庫分表分為垂直和水平兩個方式,一般來說我們拆分的順序是先垂直后水平。
垂直分庫
基于現在微服務拆分來說,都是已經做到了垂直分庫了

垂直分表
如果表字段比較多,將不常用的、數據較大的等等做拆分
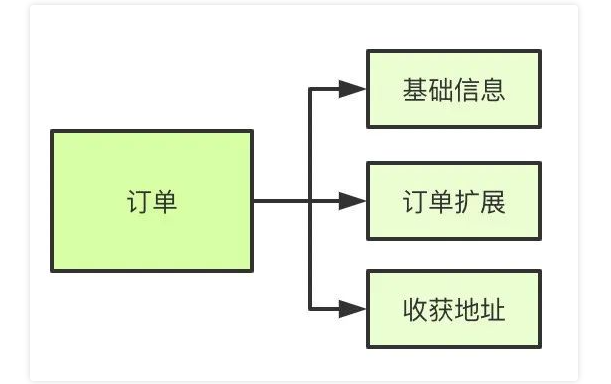
水平分表
首先根據業務場景來決定使用什么字段作為分表字段(sharding_key),比如我們現在日訂單1000萬,我們大部分的場景來源于C端,我們可以用user_id作為sharding_key,數據查詢支持到最近3個月的訂單,超過3個月的做歸檔處理,那么3個月的數據量就是9億,可以分1024張表,那么每張表的數據大概就在100萬左右。
比如用戶id為100,那我們都經過hash(100),然后對1024取模,就可以落到對應的表上了。
10. 那分表后的ID怎么保證唯一性的呢?
因為我們主鍵默認都是自增的,那么分表之后的主鍵在不同表就肯定會有沖突了。有幾個辦法考慮:
設定步長,比如1-1024張表我們分別設定1-1024的基礎步長,這樣主鍵落到不同的表就不會沖突了。
分布式ID,自己實現一套分布式ID生成算法或者使用開源的比如雪花算法這種
分表后不使用主鍵作為查詢依據,而是每張表單獨新增一個字段作為唯一主鍵使用,比如訂單表訂單號是唯一的,不管最終落在哪張表都基于訂單號作為查詢依據,更新也一樣。
11. 分表后非sharding_key的查詢怎么處理呢?
可以做一個mapping表,比如這時候商家要查詢訂單列表怎么辦呢?不帶user_id查詢的話你總不能掃全表吧?所以我們可以做一個映射關系表,保存商家和用戶的關系,查詢的時候先通過商家查詢到用戶列表,再通過user_id去查詢。
打寬表,一般而言,商戶端對數據實時性要求并不是很高,比如查詢訂單列表,可以把訂單表同步到離線(實時)數倉,再基于數倉去做成一張寬表,再基于其他如es提供查詢服務。
數據量不是很大的話,比如后臺的一些查詢之類的,也可以通過多線程掃表,然后再聚合結果的方式來做。或者異步的形式也是可以的。
List》》 taskList = Lists.newArrayList();for (int shardingIndex = 0; shardingIndex 《 1024; shardingIndex++) { taskList.add(() -》 (userMapper.getProcessingAccountList(shardingIndex)));}List list = null;try { list = taskExecutor.executeTask(taskList);} catch (Exception e) { //do something}public class TaskExecutor { public List executeTask(Collection》 tasks) throws Exception { List result = Lists.newArrayList(); List》 futures = ExecutorUtil.invokeAll(tasks); for (Future future : futures) { result.add(future.get()); } return result; }}
12. 說說mysql主從同步怎么做的吧?
首先先了解mysql主從同步的原理
master提交完事務后,寫入binlog
slave連接到master,獲取binlog
master創建dump線程,推送binglog到slave
slave啟動一個IO線程讀取同步過來的master的binlog,記錄到relay log中繼日志中
slave再開啟一個sql線程讀取relay log事件并在slave執行,完成同步
slave記錄自己的binglog

由于mysql默認的復制方式是異步的,主庫把日志發送給從庫后不關心從庫是否已經處理,這樣會產生一個問題就是假設主庫掛了,從庫處理失敗了,這時候從庫升為主庫后,日志就丟失了。由此產生兩個概念。
全同步復制
主庫寫入binlog后強制同步日志到從庫,所有的從庫都執行完成后才返回給客戶端,但是很顯然這個方式的話性能會受到嚴重影響。
半同步復制
和全同步不同的是,半同步復制的邏輯是這樣,從庫寫入日志成功后返回ACK確認給主庫,主庫收到至少一個從庫的確認就認為寫操作完成。
13. 那主從的延遲怎么解決呢?
這個問題貌似真的是個無解的問題,只能是說自己來判斷了,需要走主庫的強制走主庫查詢。
-
數據庫
+關注
關注
7文章
3765瀏覽量
64276 -
數據結構
+關注
關注
3文章
573瀏覽量
40093 -
MySQL
+關注
關注
1文章
802瀏覽量
26445
發布評論請先 登錄
相關推薦










 工商網監
工商網監
評論