") 融合3D場(chǎng)景幾何信息的視覺定位算法
融合3D場(chǎng)景幾何信息的視覺定位算法
視覺定位是自動(dòng)駕駛和移動(dòng)機(jī)器人領(lǐng)域的核心技術(shù)之一,旨在估計(jì)移動(dòng)平臺(tái)當(dāng)前的全局位姿,為環(huán)境感知和路徑規(guī)劃等其他環(huán)節(jié)提供參考和指導(dǎo)。國(guó)內(nèi)知名互聯(lián)網(wǎng)公司-美團(tuán)無人配送團(tuán)隊(duì)長(zhǎng)期在該方面進(jìn)行深入探索,積累了大量創(chuàng)新性工作。不久前,視覺定位組提出的融合3D場(chǎng)景幾何信息的視覺定位算法被ICRA2020收錄,本文將對(duì)該方法進(jìn)行介紹。
背景
1. 視覺定位算法介紹1.1 傳統(tǒng)視覺定位算法 傳統(tǒng)的視覺定位方法通常需要預(yù)先構(gòu)建視覺地圖,然后在定位階段,根據(jù)當(dāng)前圖像和地圖的匹配關(guān)系來估計(jì)相機(jī)的位姿(位置和方向)。在這種定位框架中,視覺地圖通常用帶有三維信息和特征描述子的稀疏關(guān)鍵點(diǎn)表示。然后,通過當(dāng)前圖像與地圖之間的關(guān)鍵點(diǎn)匹配獲取2D-3D對(duì)應(yīng)關(guān)系,利用PnP結(jié)合RANSAC的策略來估計(jì)相機(jī)位姿。其中,獲得準(zhǔn)確的2D-3D對(duì)應(yīng)關(guān)系對(duì)定位結(jié)果至關(guān)重要。近年來,許多工作為提高2D-3D的匹配精度進(jìn)行了各方面的探索,但大多傳統(tǒng)方法[1,3,4]還是基于SIFT、SURF、ORB等底層特征,很難處理具有挑戰(zhàn)性(光照改變或季節(jié)改變)的情況。
1.2 深度學(xué)習(xí)視覺定位算法 最近幾年,融合神經(jīng)網(wǎng)絡(luò)的視覺定位算法被廣泛研究,大家希望用神經(jīng)網(wǎng)絡(luò)取代傳統(tǒng)方法中的部分模塊(例如關(guān)鍵點(diǎn)和描述子生成)或者直接端到端的估計(jì)相機(jī)位姿。本論文研究?jī)?nèi)容屬于對(duì)后面這種類型算法的優(yōu)化。端到端視覺定位算法用神經(jīng)網(wǎng)絡(luò)的權(quán)值來表征場(chǎng)景信息,網(wǎng)絡(luò)的訓(xùn)練過程實(shí)現(xiàn)建圖,定位由網(wǎng)絡(luò)的推理過程實(shí)現(xiàn)。PoseNet[2]是第一個(gè)基于神經(jīng)網(wǎng)絡(luò)的端到端視覺定位算法,它利用GoogLeNet的基礎(chǔ)架構(gòu)直接對(duì)輸入的RGB圖像進(jìn)行6DoF相機(jī)位姿回歸。在該思路的基礎(chǔ)上,后續(xù)的改進(jìn)包括加深網(wǎng)絡(luò)結(jié)構(gòu)、增加約束關(guān)系、融合時(shí)序信息和多任務(wù)聯(lián)合建模等,例如,[5]加入貝葉斯CNN來建模精度不確定性;[6]將網(wǎng)絡(luò)改為encoder-decoder結(jié)構(gòu);[7]和[8]引入了LSTM,利用視頻流的時(shí)間和運(yùn)動(dòng)平滑性約束網(wǎng)絡(luò)學(xué)習(xí);[9]和[10]提出了多任務(wù)學(xué)習(xí)框架,聯(lián)合建模視覺定位、里程計(jì)估計(jì)和語義分割三個(gè)任務(wù),以上的工作都取得了定位精度的提升。
1.3 研究目的及意義 在上述提到的優(yōu)化方法中,雖然[9]和[10]在定位精度上表現(xiàn)的更有優(yōu)勢(shì),但是往往需要語義分割等大量的標(biāo)注信息,在大規(guī)模的場(chǎng)景下代價(jià)太大。對(duì)于加深網(wǎng)絡(luò)結(jié)構(gòu)的優(yōu)化方法,又可能帶來訓(xùn)練的難度,因此,我們認(rèn)為合理利用容易獲取的信息來優(yōu)化約束關(guān)系,具有更好的普適性和靈活性,這也是本研究的動(dòng)機(jī)之一。一些其他研究者也在這方面開展了工作,例如受傳統(tǒng)方法的啟發(fā),幾何一致性誤差、重投影誤差、相對(duì)變換誤差等被構(gòu)建為正則化項(xiàng)加入損失函數(shù)中。這些改進(jìn)比僅公式化預(yù)測(cè)位姿和真值位姿之間歐式距離的效果更好,并且不受網(wǎng)絡(luò)結(jié)構(gòu)的約束,可以靈活的適用于各種網(wǎng)絡(luò)做進(jìn)一步的性能提升。
在此基礎(chǔ)上,我們進(jìn)一步探索以更好的方式用幾何信息來約束網(wǎng)絡(luò)權(quán)重的更新。在SLAM應(yīng)用和無人車平臺(tái)中,深度信息是不可或缺的。例如,室內(nèi)情況,利用現(xiàn)有的深度估計(jì)算法,可以直接從結(jié)構(gòu)光相機(jī)、ToF相機(jī)或立體相機(jī)中獲取深度信息;室外環(huán)境,通常采用三維激光雷達(dá)來獲取深度/距離信息。因此,我們的改進(jìn)也對(duì)深度信息加以利用。此外,我們使用了光度一致性的假設(shè),也就是說,根據(jù)三維幾何知識(shí),當(dāng)在多個(gè)圖像中觀察三維場(chǎng)景中的同一個(gè)點(diǎn)時(shí),我們認(rèn)為其對(duì)應(yīng)的像素強(qiáng)度應(yīng)該是相同的,這也被用于許多視覺里程計(jì)或光流算法。受此啟發(fā),我們構(gòu)建了光度差損失項(xiàng),并自然而然地搭配結(jié)構(gòu)相似性(SSIM)損失項(xiàng)。前者為像素級(jí)約束,后者為圖像級(jí)約束,和常用的歐式距離一起作為網(wǎng)絡(luò)的損失函數(shù),訓(xùn)練過程中約束網(wǎng)絡(luò)權(quán)重的更新。我們優(yōu)化后的損失函數(shù)融合了運(yùn)動(dòng)信息、3D場(chǎng)景幾何信息和圖像內(nèi)容,幫助訓(xùn)練過程更高效、定位效果更準(zhǔn)確。
2. 相關(guān)工作介紹2.1 幾何一致性約束 幾何一致性約束最近被用來幫助提高位姿回歸的準(zhǔn)確性,并被證明比單獨(dú)使用歐氏距離約束更有效。[9]和[10]通過懲罰與相對(duì)運(yùn)動(dòng)相矛盾的位姿預(yù)測(cè),將幾何一致性引入到損失函數(shù)中。[11]利用圖像對(duì)之間的相對(duì)運(yùn)動(dòng)一致性來約束絕對(duì)位姿的預(yù)測(cè)。[12]引入了重投影誤差,使用真值和預(yù)測(cè)位姿分別將3D點(diǎn)投影到2D圖像平面上,將像素點(diǎn)位置的偏差作為約束項(xiàng)。這些方法都被認(rèn)為是當(dāng)時(shí)使用幾何一致性損失的最先進(jìn)方法。在本研究中,我們探索了一個(gè)3D場(chǎng)景幾何約束即光度差約束,通過聚合三維場(chǎng)景幾何結(jié)構(gòu)信息,使得網(wǎng)絡(luò)不僅能將預(yù)測(cè)的位姿與相機(jī)運(yùn)動(dòng)對(duì)齊,還能利用圖像內(nèi)容的光度一致性。
2.2 光度差約束 光度差約束通常用于處理帶監(jiān)督或無監(jiān)督學(xué)習(xí)的相對(duì)位姿回歸、光流估計(jì)和深度預(yù)測(cè)。例如,[13]研究了視頻序列的時(shí)間關(guān)系,為深度補(bǔ)全網(wǎng)絡(luò)提供額外的監(jiān)督。[14]利用無監(jiān)督學(xué)習(xí)的稠密深度和帶有光度差損失的相機(jī)位姿構(gòu)建了神經(jīng)網(wǎng)絡(luò),以學(xué)習(xí)場(chǎng)景級(jí)一致性運(yùn)動(dòng)。[15]提出了一種多任務(wù)無監(jiān)督學(xué)習(xí)稠密深度、光流和ego-motion的方法,其中光度差約束對(duì)不同任務(wù)之間的一致性起著重要作用。由于光度差約束在相對(duì)位姿回歸和深度預(yù)測(cè)中被證明是有效的,我們引入并驗(yàn)證了它在絕對(duì)位姿預(yù)測(cè)中的有效性。 與上述工作相比,我們的研究擴(kuò)展了以下幾點(diǎn)工作:
搭建了一個(gè)深度神經(jīng)網(wǎng)絡(luò)模型,可以直接從輸入圖像估計(jì)相應(yīng)的相機(jī)絕對(duì)位姿。
利用深度傳感器信息,構(gòu)建了 3D 場(chǎng)景幾何約束來提高位姿預(yù)測(cè)精度。并且,稀疏深度信息足以獲得顯著的定位精度提升,這意味著我們的方法可以適用于任何類型的深度傳感器(稀疏或稠密)。
在室內(nèi)和室外數(shù)據(jù)集上進(jìn)行了廣泛的實(shí)驗(yàn)評(píng)估,證明了加入 3D 場(chǎng)景幾何約束后,可以提高網(wǎng)絡(luò)的定位精度,并且這一約束可以靈活地加入到其他網(wǎng)絡(luò)中,幫助進(jìn)一步提高算法性能。
算法介紹
1. 算法框架
本研究提出的算法框架和數(shù)據(jù)流如圖a所示,藍(lán)色部分是算法中的神經(jīng)網(wǎng)絡(luò)部分(圖b),綠色部分是warping計(jì)算過程,黃色部分是網(wǎng)絡(luò)的損失函數(shù)項(xiàng),只有藍(lán)色部分包含可訓(xùn)練的權(quán)重。 藍(lán)色部分的網(wǎng)絡(luò)模型采用主流的ResNet-50網(wǎng)絡(luò),保留原來的block設(shè)置,并在最后一個(gè)block后加入3個(gè)全連接層,分別預(yù)測(cè)3維的translation(x)和3維的rotation(q)。網(wǎng)絡(luò)的訓(xùn)練過程需要輸入兩張連續(xù)的有共視的圖像以及其中一張圖像的深度圖,建立真值位姿和預(yù)測(cè)位姿之間的歐式距離約束作為損失項(xiàng)。大部分先前文獻(xiàn)中的工作僅以這個(gè)損失項(xiàng)作為損失函數(shù),我們的工作則進(jìn)一步融入了3D場(chǎng)景幾何信息,通過利用比較容易獲取的深度信息將這個(gè)約束公式化為光度差和SSIM。相比之下,3D場(chǎng)景幾何約束是像素級(jí)的,可以利用更多的信息包括相機(jī)運(yùn)動(dòng),場(chǎng)景的三維結(jié)構(gòu)信息和圖像內(nèi)容相關(guān)的光度信息,從而使網(wǎng)絡(luò)的學(xué)習(xí)更加高效,更好地朝著全局極小值的方向收斂。

2.Warping計(jì)算 綠色部分的warping計(jì)算利用連續(xù)兩張圖像之間的相對(duì)位姿變換和其中一張圖像的深度圖,將本張圖像上的像素投影到另一張圖像的視角上,生成視warping后的圖像,計(jì)算公式如下所示。

在warping計(jì)算中,從二維圖像像素重建三維結(jié)構(gòu)需要深度信息,實(shí)際應(yīng)用中我們可以從深度傳感器(結(jié)構(gòu)光相機(jī)、ToF相機(jī)和三維激光雷達(dá))獲取深度信息或通過相關(guān)算法回歸深度,例如從兩個(gè)重疊的圖像中提取匹配點(diǎn)的三角測(cè)量方法。為了不引入誤差,我們更傾向于選擇來自深度傳感器的比較魯棒的深度信息。為了方便反向傳播的梯度計(jì)算,我們采用雙線性插值作為采樣機(jī)制,生成與當(dāng)前圖像格式相同的合成圖像。此外,這部分計(jì)算不含可訓(xùn)練的參數(shù),并且inference過程不需要進(jìn)行這部分的計(jì)算,因此不會(huì)帶來額外的時(shí)間或者資源開銷。 3. 損失函數(shù) 在訓(xùn)練過程中,應(yīng)用了三個(gè)約束條件來幫助訓(xùn)練收斂:一個(gè)經(jīng)典的歐式距離損失項(xiàng)來約束預(yù)測(cè)位姿和真值位姿的距離,歐式距離損失項(xiàng)此處不再贅述,直接給出公式如下:
 ? 當(dāng)視角變化較小且環(huán)境光不變時(shí),同一個(gè)三維點(diǎn)在不同圖像中的光強(qiáng)應(yīng)該相同。這種光度一致性用于解決許多問題,如光流估計(jì)、深度估計(jì)、視覺里程計(jì)等。在這里,我們使用它來進(jìn)行絕對(duì)位姿估計(jì),并光度差損失項(xiàng)公式化為warping計(jì)算后的圖像與原始圖像對(duì)應(yīng)像素點(diǎn)的光度差值: ?
? 當(dāng)視角變化較小且環(huán)境光不變時(shí),同一個(gè)三維點(diǎn)在不同圖像中的光強(qiáng)應(yīng)該相同。這種光度一致性用于解決許多問題,如光流估計(jì)、深度估計(jì)、視覺里程計(jì)等。在這里,我們使用它來進(jìn)行絕對(duì)位姿估計(jì),并光度差損失項(xiàng)公式化為warping計(jì)算后的圖像與原始圖像對(duì)應(yīng)像素點(diǎn)的光度差值: ?
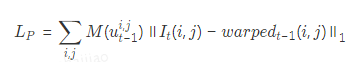
其中,M是用來過濾沒有深度信息或者不服從光度一致性的像素。在我們的實(shí)驗(yàn)中,主要用它來屏蔽兩種類型的像素:移動(dòng)目標(biāo)對(duì)應(yīng)的像素和帶有無效深度信息的像素。光度差損失項(xiàng)會(huì)約束預(yù)測(cè)的位姿離真值位姿不遠(yuǎn),以保證在相鄰圖像間進(jìn)行warping計(jì)算后重建的圖像與原始圖像對(duì)應(yīng)像素的光度值一致。考慮到warping計(jì)算后,獲得了視角重建后的圖像,自然而然的引入結(jié)構(gòu)相似性約束作為損失項(xiàng)。這個(gè)約束反映了場(chǎng)景結(jié)構(gòu)的一致性,計(jì)算公式如下所示:
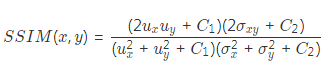

網(wǎng)絡(luò)的損失函數(shù)定義為三個(gè)損失項(xiàng)的加權(quán)和,用三個(gè)加權(quán)系數(shù)進(jìn)行尺度均衡。 
實(shí)驗(yàn)結(jié)果
為了驗(yàn)證我們提出的算法的性能,進(jìn)行了以下實(shí)驗(yàn): 1. 與其他算法定位結(jié)果對(duì)比 在7Scene數(shù)據(jù)集中,除了MapNet[11]在chess場(chǎng)景中的表現(xiàn)稍好之外,我們的方法在其他場(chǎng)景都取得了最優(yōu)的結(jié)果(見table 1)。在所需的訓(xùn)練時(shí)間上,MapNet 需要300個(gè)epochs和PoseNet[2]需要多于120個(gè)epochs,我們的方法只需要50個(gè)epochs。同時(shí),在室外的Oxford robotcar數(shù)據(jù)集上,我們的方法也取得了較大的定位精度提升。Figure2顯示了在7Scene中隨機(jī)挑選的場(chǎng)景的測(cè)試結(jié)果。很明顯,PoseNet的預(yù)測(cè)位姿噪聲較大,MapNet表現(xiàn)的更穩(wěn)定,但預(yù)測(cè)精度欠佳,我們的定位結(jié)果更為精確。
2. 損失項(xiàng)的消融實(shí)驗(yàn) 為了充分驗(yàn)證我們提出的光度差損失和SSIM損失對(duì)視覺定位算法性能提升的貢獻(xiàn),分別進(jìn)行兩個(gè)訓(xùn)練:在PoseNet網(wǎng)絡(luò)的損失函數(shù)中加入光度差損失和SSIM損失后訓(xùn)練網(wǎng)絡(luò)。在我們的算法中去掉這兩項(xiàng)損失項(xiàng),只在歐式距離的約束下訓(xùn)練網(wǎng)絡(luò)。結(jié)果表明加入光度差和SSIM損失項(xiàng)總是能提高網(wǎng)絡(luò)的定位性能(詳細(xì)結(jié)果見論文)。同時(shí),也表明新的損失項(xiàng)可以靈活的加入其他網(wǎng)絡(luò),用于進(jìn)一步提高定位精度。
3. 深度稀疏實(shí)驗(yàn) 實(shí)際視覺定位應(yīng)用中,并不總是有可靠的稠密深度可用,如果我們的算法在稀疏深度上依然可以表現(xiàn)的很好,則可以證明我們的方法具有較廣泛的適用性。我們把可用的深度隨機(jī)稀疏至原來的20%和60%后,重新訓(xùn)練網(wǎng)絡(luò),最終的結(jié)果如Table3所示,定位精度并沒有被嚴(yán)重惡化。
4. 自監(jiān)督方法的實(shí)驗(yàn) 在進(jìn)行warping計(jì)算時(shí),我們用了輸入兩幀圖像的位姿預(yù)測(cè)結(jié)果來計(jì)算相對(duì)位姿變換,進(jìn)而做warping計(jì)算,單就光度差和SSIM損失項(xiàng)來說,這是一種自監(jiān)督的學(xué)習(xí)方法,那么,也可以一幀圖像用預(yù)測(cè)結(jié)果,另一幀用真值來計(jì)算相對(duì)位姿變換。通過實(shí)驗(yàn)對(duì)比這兩種方法,實(shí)驗(yàn)結(jié)果(詳細(xì)結(jié)果見論文)表明,自監(jiān)督策略的結(jié)果更優(yōu)。除了網(wǎng)絡(luò)被訓(xùn)練的次數(shù)更多這一原因外,它有助于網(wǎng)絡(luò)以一種更自然的方式學(xué)習(xí)相機(jī)位姿的連續(xù)性和一致性,因?yàn)閷?duì)于共視的圖像,其相應(yīng)的位姿應(yīng)該是高度相關(guān)的。


結(jié)論與展望
本文提出了一種新的視覺定位算法,搭建一個(gè)新的網(wǎng)絡(luò)框架端到端的估計(jì)相機(jī)位姿,在對(duì)網(wǎng)絡(luò)約束關(guān)系的優(yōu)化中,通過融合3D場(chǎng)景幾何結(jié)構(gòu)、相機(jī)運(yùn)動(dòng)和圖像信息,引入了3D場(chǎng)景幾何約束,幫助監(jiān)督網(wǎng)絡(luò)訓(xùn)練,提高網(wǎng)絡(luò)的定位精度。實(shí)驗(yàn)結(jié)果表明,我們的方法優(yōu)于以往的同類型工作。并且,在不同的網(wǎng)絡(luò)中加入新的約束關(guān)系后可以進(jìn)一步提高定位精度。
基于深度學(xué)習(xí)的視覺定位算法正在被廣泛而又深入的研究,無論是提升算法的精度還是增強(qiáng)實(shí)際場(chǎng)景的適用性,各方面的嘗試和努力都是迫切需要的。希望在未來的工作中,能夠通過融入語義信息或者采用從粗到精多階段級(jí)連的方法,在室內(nèi)外場(chǎng)景上實(shí)現(xiàn)更高精度更加魯棒的位姿估計(jì),更多細(xì)節(jié)見論文.
論文原文:3D Scene Geometry-Aware Constraint for Camera Localization with Deep Learning 鏈接:https://arxiv.org/abs/2005.06147 參考文獻(xiàn) [1] Ke, Yan and R. Sukthankar. “PCA-SIFT: a more distinctive representation for local image descriptors.” Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), 2004. [2] A. Kendall, M. Grimes, and R. Cipolla, “Posenet: A convolutional network for real-time 6-dof camera relocalization,” in ICCV, 2015. [3] Bay, Herbert, et al. “Speeded-up robust features (SURF).” Computer vision and image understanding 110.3 (2008): 346-359.
[4] Rublee, Ethan, et al. “ORB:An efficient alternative to SIFT or SURF.” ICCV. Vol. 11. No. 1. 2011. [5] A. Kendall and R. Cipolla,“Modelling uncertainty in deep learning for camera relocalization,” ICRA, 2016. [6] I. Melekhov, J. Ylioinas, J. Kannala, and E. Rahtu, “Image-based localization using hourglass networks,” arXiv:1703.07971, 2017. [7] F. Walch, C. Hazirbas, et al.,“Image-based localization using lstms for structured feature correlation,” in ICCV, 2017. [8] Xue, Fei, et al. “Beyond Tracking: Selecting Memory and RefiningPoses for Deep Visual Odometry.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019
[9] A. Valada, N. Radwan, and W. Burgard, “Deep auxiliary learning for visual localization and odometry,” in ICRA, 2018. [10] N. Radwan, A. Valada, W. Burgard, “VLocNet++: Deep MultitaskLearning for Semantic Visual Localization and Odometry”, IEEE Robotics and Automation Letters (RA-L), 3(4): 4407-4414, 2018. [11] Brahmbhatt, Samarth, et al. “Geometry-aware learning of maps for camera localization.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018. [12] A. Kendall and R. Cipolla, “Geometric loss functions for camera pose regression with deep learning,” CVPR, 2017. [13] Ma, Fang chang, Guilherme Venturelli Cavalheiro, and Sertac Karaman.“Self-supervised sparse-to-dense: Self-supervised depth completion from lidar and monocular camera.” 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019. [14] Zhou, Tinghui, et al. “Unsupervised Learning of Depth and Ego-Motion from Video.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017. [15] Yin, Zhichao, and Jianping Shi. “Geonet: Unsupervised learning of dense depth, optical flow and camera pose.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
責(zé)任編輯:xj
原文標(biāo)題:機(jī)器視覺干貨 | 場(chǎng)景幾何約束在視覺定位中的探索
文章出處:【微信公眾號(hào):機(jī)器人創(chuàng)新生態(tài)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
機(jī)器人
+關(guān)注
關(guān)注
210文章
28231瀏覽量
206614 -
機(jī)器視覺
+關(guān)注
關(guān)注
161文章
4348瀏覽量
120134 -
視覺定位
+關(guān)注
關(guān)注
5文章
49瀏覽量
12377
原文標(biāo)題:機(jī)器視覺干貨 | 場(chǎng)景幾何約束在視覺定位中的探索
文章出處:【微信號(hào):robotplaces,微信公眾號(hào):機(jī)器人創(chuàng)新生態(tài)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
3d場(chǎng)景建模可視化,場(chǎng)景1:1還原
蘇州吳中區(qū)多色PCB板元器件3D視覺檢測(cè)技術(shù)

3D視覺引導(dǎo)方案解決工廠產(chǎn)線上下料難題
機(jī)器人3D視覺引導(dǎo)系統(tǒng)框架介紹
解決方案|基于3D視覺技術(shù)的鋁合金板件刷油烘干自動(dòng)化上下料
包含具有多種類型信息的3D模型
工業(yè)自動(dòng)化,3D視覺在五金件上下料中的應(yīng)用

一種用于2D/3D圖像處理算法的指令集架構(gòu)以及對(duì)應(yīng)的算法部署方法
ad中3d封裝放到哪個(gè)層
基于3D點(diǎn)云的多任務(wù)模型在板端實(shí)現(xiàn)高效部署
2D與3D視覺技術(shù)的比較
圖漾科技發(fā)布3D工業(yè)視覺應(yīng)用開發(fā)平臺(tái)Vision++
3D視覺的三大優(yōu)勢(shì)

深度解析3D視覺成像幾種典型方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論