 C和C++是一回事嗎
C和C++是一回事嗎
C語言雖說經常和c++在一起被大家提起,但可千萬不要以為它們是一個東西。現在我們常用的C語言是C89標準,C++是C++99標準的。C89就是在1989年制定的標準。本文在討論的時候使用的C語言標準是C89,C++標準是C++99。
我們來介紹C語言和C++中那些不同的地方。
函數默認值
在C++中我們在定義或聲明一個函數的時候,有時會在形參中給它賦一個初始值作為不傳參數時候的缺省值,例如:
int FUN(int a = 10);
代表沒有傳參調用的時候,自動給a賦一個10的初始值。然而這種操作在c89下是行不通的,在c語言下這么寫就會報錯。
我們都知道,系統在調用任何一個函數的時候都有函數棧幀的開辟,如果函數有參數則需要壓入實參。平常在我們人為給定實參的時候,是按照參數列表從右向左依次將參數通過以下指令傳入寄存器,再通過push指令壓入。現在我們已經給定了函數參數的默認值,那么在壓實參的時候只需要一步push初始值即可,效率更高。
mov eax/ecx dword ptr[ebp-4] //假設是int數據
另外需要注意的是,賦初始值必須從參數列表的右邊開始賦值,從左邊開始賦值將會出錯:
intsum1(inta=10,intb);//錯誤int sum2(int a,int b = 20); //正確
因為如果sum1的聲明是正確的,那么我們調用的時候怎么調用?sum1( ,20)?很可惜這樣屬于語法錯誤,調用這么寫既然不對那就當然不能這樣賦初始值了。相反,sum2的調用:sum2(20);合情合理,沒有任何問題。
實際在寫工程的時候,我們都習慣將函數的聲明寫在頭文件中而非本文件里,然后在不同的文件中寫出它們的定義。那么這種情況可以賦初始值嗎?當然可以,不論是定義還是聲明處,只要你遵守從右向左賦的規則就可以。甚至你還可以這樣給初始值:
int fun(int a ,int b = 10);int fun(int a = 20,int b);
眼尖的同學看見了下面的那行代碼大喊錯誤,因為先給左邊賦值了!
其實這樣聲明完全沒有問題,兩句聲明是同一個函數(函數多次聲明沒有問題),第一句已經給b了一個初始值,運行到第二句時已經等價于int fun(int a = 20,int b = 10);了。但是注意,這兩句的順序不能反轉,否則就是錯誤的。
總結:C89標準的C語言不支持函數默認值,C++支持函數默認值,且需要遵循從右向左賦初始值。
inline內聯函數
說到內聯函數大家應當不陌生,它又是一個C89標準下C語言沒有的函數。它的具體做法和宏非常相似,也是在調用處直接將代碼展開,只不過宏它是在預編譯階段展開,而內聯函數是在 編譯階段進行處理的。同時,宏作為預處理并不進行類型檢查,而inline函數是要進行類型檢查的,也就可以稱作“更安全的宏”。
內聯函數和普通函數的區別:內聯函數沒有棧幀的開辟回退,一般我們直接把內聯函數寫在頭文件中,include之后就可以使用,由于調用時直接代碼展開所以我們根本不需要擔心什么重定義的問題——它連符號都沒有生成當然不會所謂重定義了。普通函數生成符號,內聯函數不會生成符號。
關于inline還需要注意的一點是,我們在使用它的時候往往是用來替換函數體非常小(1~5行代碼)的函數的。這種情況下函數的堆棧開銷相對函數體大小來說就非常大了,這種情況使用內聯函數可以大大提高效率。相反如果是一個需要很多代碼才能實現的函數,則不適合使用。一是此時函數堆棧調用開銷與函數體相比已經是微不足道了,二是大量的代碼直接展開的話會給調試帶來很大的不便。三是如果代碼體達到一個閾值,編譯器會將它變成普通函數。
同時,遞歸函數不能聲明為inline函數。說到底inline只是對編譯器的建議,最終能否成功也不一定。同時,我們平常生成的都是debug版本,在這個版本下inline是不起作用的。只有生成release版時才會起作用。
總結:C89沒有,在調用點直接展開,不生成符號,沒有棧幀的開辟回退,僅在Release版本下生效。一般寫在頭文件中。
函數重載
C語言中產生函數符號的規則是根據名稱產生,這也就注定了c語言不存在函數重載的概念。而C++生成函數符號則考慮了函數名、參數個數、參數類型。需要注意的是函數的返回值并不能作為函數重載的依據,也就是說int sum和double sum這兩個函數是不能構成重載的!
我們的函數重載也屬于多態的一種,這就是所謂的靜多態。
靜多態:函數重載,函數模板
動多態(運行時的多態):繼承中的多態(虛函數)。
使用重載的時候需要注意作作用域問題:請看如下代碼。
#include
我在全局作用域定義了兩個函數,它們由于參數類型不同可以構成重載,此時main函數中調用則可以正確的調用到各自的函數。
但是請看main函數中被注釋掉的一句代碼。如果我將它放出來,則會提出警告:將double類型轉換成int類型可能會丟失數據。
這就意味著我們編譯器針對下面兩句調用都調用了參數類型int的compare。由此可見,編譯器調用函數時優先在局部作用域搜索,若搜索成功則全部按照該函數的標準調用。若未搜索到才在全局作用域進行搜索。
總結:C語言不存在函數重載,C++根據函數名參數個數參數類型判斷重載,屬于靜多態,必須同一作用域下才叫重載。
const
這一部分非常重要。在我的另一篇博客“C語言的32個關鍵字”中對C語言中的const也有所講解。當中提到了這么一個問題:C語言中被const修飾的變量不是常量,叫做常變量或者只讀變量,這個常變量是無法當作數組下標的。然而在C++中const修飾的變量可以當作數組下標使用,成為了真正的常量。這就是C++對const的擴展。
C語言中的const:被修飾后不能做左值,可以不初始化,但是之后沒有機會再初始化。不可以當數組的下標,可以通過指針修改。簡單來說,它和普通變量的區別只是不能做左值而已。其他地方都是一樣的。
C++中的const:真正的常量。定義的時候必須初始化,可以用作數組的下標。const在C++中的編譯規則是替換(和宏很像),所以它被看作是真正的常量。也可以通過指針修改。需要注意的是,C++的指針有可能退化成C語言的指針。比如以下情況:
int b = 20;const int a = b;
這時候的a就只是一個普通的C語言的const常變量了,已經無法當數組的下標了。(引用了一個編譯階段不確定的值)
const在生成符號時,是local符號。即在本文件中才可見。如果非要在別的文件中使用它的話,在文件頭部聲明:extern cosnt int data = 10;這樣生成的符號就是global符號。
總結:C中的const叫只讀變量,只是無法做左值的變量;C++中的const是真正的常量,但也有可能退化成c語言的常量,默認生成local符號。
引用
說到引用,我們第一反應就是想到了他的兄弟:指針。引用從底層來說和指針就是同一個東西,但是在編譯器中它的特性和指針完全不同。
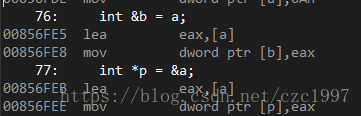
int a = 10;int &b = a;int*p=&a;//b=20;//*p = 20;
首先定義一個變量a = 10,然后我們分別定義一個引用b以及一個指針p指向a。我們來轉到反匯編看看底層的實現:
可以看到底層實現完全一致,取a的地址放入eax寄存器,再將eax中的值存入引用b/指針p的內存中。至此我們可以說(在底層)引用本質就是一個指針。
了解了底層實現,我們回到編譯器。我們看到對a的值的修改,指針p的做法是*p = 20;即進行解引用后替換值。底層實現:
再來看看引用修改:
我們看到修改a的值的方法也是一樣的,也是解引用。只是我們在調用的時候有所不同:調用p時需要*p解引用,b則直接使用就可以。由此我們推斷出:引用在直接使用時是指針解引用。p直接使用則是它自己的地址。這樣我們也了解了,我們給引用開辟的這塊內存是根本訪問不到的。如果直接用就直接解引用了。即使打印&b,輸出的也是a的地址。
在此附上將指針轉為引用的小技巧:int *p = &a,我們將 引用符號移到左邊 將 *替換即可:int &p = a。
接下來看看如何創建數組的引用:
int array[10] = {0};//定義一個數組
我們知道,array拿出來使用的話就是數組array的首元素地址。即是int *類型。
那么&array是什么意思呢?int **類型,用來指向array[0]地址的一個地址嗎?不要想當然了,&array是整個數組類型。
那么要定義一個數組引用,按照上面的小訣竅,先來寫寫數組指針吧:
int (*q) [10] = &array;
將右側的&對左邊的*進行覆蓋:
int (&q)[10] = array;
測試sizeof(q) = 10。我們成功創建了數組引用。
經過上面的詳解 ,我們知道了引用其實就是取地址。那么我們都知道一個立即數是沒有地址的,即
int &b = 10;
這樣的代碼是無法通過編譯的。那如果你就是非要引用一個立即數,其實也不是沒有辦法:
const int &b = 10;
即將這個立即數用const修飾一下,就可以了。為什么呢?
這時因為被const修飾的都會產生一個臨時量來保存這個數據,自然就有地址可取了。
總結:引用底層就是指針,使用時會直接解引用,可以配合const對一個立即數進行引用。
malloc,free && new,delete
這個問題很有意思,也是重點需要關注的問題。malloc()和free()是C語言中動態申請內存和釋放內存的標準庫中的函數。而new和delete是C++運算符、關鍵字。new和delete底層其實還是調用了malloc和free。它們之間的區別有以下幾個方面:
①:malloc和free是函數,new和delete是運算符。
②:malloc在分配內存前需要大小,new不需要。
例如:
int *p1 = (int *)malloc(sizeof(int));int *p2 = new int; int *p3 = new int(10);
malloc時需要指定大小,還需要類型轉換。new時不需要指定大小因為它可以從給出的類型判斷,并且還可以同時賦初始值。
③:malloc不安全,需要手動類型轉換,new不需要類型轉換。
④:free只釋放空間,delete先調用析構函數再釋放空間(如果需要)。與第⑤條對應,如果使用了復雜類型,先析構再call operator delete回收內存。
⑤:new是先調用構造函數再申請空間(如果需要)。
與第④條對應,我們在調用new的時候(例如int *p2 = new int;這句代碼 ),底層代碼的實現是:首先push 4字節(int類型的大小),隨后call operator new函數分配了內存。由于我們這句代碼并未涉及到復雜類型(如類類型),所以也就沒有構造函數的調用。如下是operator new的源代碼,也是new實現的重要函數:
void *__CRTDECL operator new(size_t size) _THROW1(_STD bad_alloc){ // try to allocate size bytes void *p;while ((p = malloc(size)) == 0)if (_callnewh(size) == 0){ // report no memory _THROW_NCEE(_XSTD bad_alloc, );}return (p);}
我們可以看到,首先malloc(size)申請參數字節大小的內存,如果失敗(malloc失敗返回0)則進入判斷:如果_callnewh(size)也失敗的話,拋出bad_alloc異常。_callnewh()這個函數是在查看new handler是否可用,如果可用會釋放一部分內存再返回到malloc處繼續申請,如果new handler不可用就會拋出異常。
⑥:內存不足(開辟失敗)時處理方式不同。
malloc失敗返回0,new失敗拋出bad_alloc異常。
⑦:new和malloc開辟內存的位置不同。
malloc開辟在堆區,new開辟在自由存儲區域。
⑧:new可以調用malloc(),但malloc不能調用new。
new就是用malloc()實現的,new是C++獨有malloc當然無法調用。
作用域
C語言中作用域只有兩個:局部,全局。C++中則是有:局部作用域,類作用域,名字空間作用域三種。
所謂名字空間就是namespace,我們定義一個名字空間就是定義一個新作用域。訪問時需要以如下方式訪問,以std為例:
std::cin<< "123" <
例如我們有一個名字空間叫Myname,其中有一個變量叫做data。如果我們希望在其他地方使用data的話,需要在文件頭聲明:using Myname::data;這樣一來data就使用的是Myname中的值了。可是這樣每個符號我們都得聲明豈不是累死?
我們只要using namespace Myname;就可以將其中所有符號導入了。這也就是我們經常看到的using namespace std;的意思啦。
責任編輯:xj
原文標題:C和C++是同一個東西嗎
-
C語言
+關注
關注
180文章
7601瀏覽量
136251 -
編程
+關注
關注
88文章
3596瀏覽量
93610 -
C++
+關注
關注
22文章
2104瀏覽量
73503
原文標題:C和C++是同一個東西嗎
文章出處:【微信號:c-stm32,微信公眾號:STM32嵌入式開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Laird Eccosorb吸波材料的應用案例

使用Tina ti仿真ths3201時,發生源兩路輸入則輸出不對是怎么回事?
數字工廠與智能工廠是一回事嗎
用STM8L152使用一個矩陣鍵盤,信號一直處于低電平狀態的原因?
電機和馬達是一回事嗎 馬達和電機有什么區別
SMT生產過程中拋料是怎么一回事呢?具體需要怎么解決?
M453VG6AE中ISP Flash和LDROM是不是一回事?它們基地址分別是什么?
密封性和氣密性:并非同一回事

C++簡史:C++是如何開始的

開關磁阻電機和交流磁阻同步電機是一回事嗎?
整流和檢波是一回事嗎?整流二極管和檢波二極管能互相代替嗎?
學了這些射頻圈“黑話”,咱們就是射頻人






 工商網監
工商網監
評論