") 機(jī)器學(xué)習(xí)并行化的自適應(yīng)、可組合與自動(dòng)化問題
機(jī)器學(xué)習(xí)并行化的自適應(yīng)、可組合與自動(dòng)化問題
CMU 機(jī)器人研究所張昊(Hao Zhang)博士論文新鮮出爐,主要圍繞著機(jī)器學(xué)習(xí)并行化的自適應(yīng)、可組合與自動(dòng)化問題展開。
隨著近年來,機(jī)器學(xué)習(xí)領(lǐng)域的創(chuàng)新不斷加速,SysML 的研究者已經(jīng)創(chuàng)建了在多個(gè)設(shè)備或計(jì)算節(jié)點(diǎn)上并行機(jī)器學(xué)習(xí)訓(xùn)練的算法和系統(tǒng)。機(jī)器學(xué)習(xí)模型在結(jié)構(gòu)上變得越來越復(fù)雜,許多系統(tǒng)都試圖提供全面的性能。尤其是,機(jī)器學(xué)習(xí)擴(kuò)展通常會(huì)低估從一個(gè)適當(dāng)?shù)姆植疾呗杂成涞侥P退枰闹R(shí)與時(shí)間。此外,將并行訓(xùn)練系統(tǒng)應(yīng)用于復(fù)雜模型更是增加了非常規(guī)的開發(fā)成本,且性能通常低于預(yù)期。 近日,CMU 機(jī)器人研究所博士張昊公布了自己的博士學(xué)位論文《機(jī)器學(xué)習(xí)并行化的自適應(yīng)、可組合與自動(dòng)化》,旨在找出并解決并行 ML 技術(shù)和系統(tǒng)實(shí)現(xiàn)在可用性和性能方面的研究挑戰(zhàn)。 具體而言,該論文從可編程性、并行化表示、性能優(yōu)化、系統(tǒng)架構(gòu)和自動(dòng)并行化技術(shù)等幾方面對分布式并行 ML 展開了研究,并認(rèn)為分布式并行機(jī)器學(xué)習(xí)可以同時(shí)實(shí)現(xiàn)簡潔性和高效性。此外,該論文表明,并行 ML 的性能可以通過生成自適應(yīng) ML 模型結(jié)構(gòu)和集群資源范式的策略實(shí)現(xiàn)大幅度提升,同時(shí)通過將「如何并行化」這一核心問題形式化為端到端優(yōu)化目標(biāo)以及構(gòu)建可組合分布式 ML 系統(tǒng)來自動(dòng)優(yōu)化這類自適應(yīng)、自定義策略,進(jìn)而可以解決可用性挑戰(zhàn)。
論文鏈接:https://www.cs.cmu.edu/~hzhang2/files/hao_zhang_doctoral_dissertation.pdf 機(jī)器之心對該論文的核心內(nèi)容進(jìn)行了簡要介紹,感興趣的讀者可以閱讀原論文。 論文內(nèi)容介紹 這篇論文主要由三部分組成,如下圖所示,第 1 部分(第三章 - 第五章):在單個(gè)機(jī)器學(xué)習(xí)并行化層面,使用自適應(yīng)并行化理解和優(yōu)化并行機(jī)器學(xué)習(xí)性能;第 2 部分(第六章 - 第七章):為機(jī)器學(xué)習(xí)并行開發(fā)統(tǒng)一的表示和可組合系統(tǒng);第 3 部分(第八章):機(jī)器學(xué)習(xí)并行化的自動(dòng)化。
論文結(jié)構(gòu)概覽 論文第一部分提出了一個(gè)簡單的設(shè)計(jì)原則自適應(yīng)并行(adaptive parallelism),根據(jù)模型構(gòu)建要素(比如層)的特定 ML 屬性,將合適的并行化技術(shù)應(yīng)用于模型組成要素中。作者以 BERT 為例,總結(jié)出了實(shí)現(xiàn)這種自適應(yīng)的基本原理和三個(gè)核心概念,分別是子模型策略組合、多個(gè)并行化方面的系統(tǒng)優(yōu)化和資源感知。此外,作者推導(dǎo)出了一系列優(yōu)化和實(shí)現(xiàn)方法,從不同層面去提升 ML 并行化。研究結(jié)果表明其顯著提高了 ML 訓(xùn)練在集群上的效率和可擴(kuò)展性。 第二部分對這種方法進(jìn)行了概述,并且面向機(jī)器學(xué)習(xí)并行化任務(wù)的兩個(gè)常見范式:單節(jié)點(diǎn)動(dòng)態(tài)批處理和分布式機(jī)器學(xué)習(xí)并行,作者將機(jī)器學(xué)習(xí)的并行化表述為端到端的優(yōu)化問題,并尋找其自動(dòng)化的解決方法。作者提出了原則表征來表示兩類機(jī)器學(xué)習(xí)并行,以及可組合的系統(tǒng)架構(gòu) Cavs 與 AutoDist。它們能夠快速組合不可見模型的并行化策略,提升并行化表現(xiàn),并簡化并行機(jī)器學(xué)習(xí)程序。
Facebook AI 提出的 DETR 的架構(gòu)圖 在此基礎(chǔ)上,論文第三部分提出一個(gè)自動(dòng)并行化框架 AutoSync,用于自動(dòng)優(yōu)化數(shù)據(jù)并行分布訓(xùn)練中的同步策略。它實(shí)現(xiàn)了「開箱即用」的高性能,可以通過提出的表征進(jìn)行空間導(dǎo)航,并自動(dòng)識(shí)別同步策略,這些策略比現(xiàn)有的手工優(yōu)化系統(tǒng)的速度提高了 1.2-1.6 倍,降低了分布式 ML 的技術(shù)障礙,并幫助更大范圍的用戶訪問它。總結(jié)來說,這篇論文提出的相關(guān)技術(shù)和系統(tǒng)驗(yàn)證了分布式環(huán)境下面向大規(guī)模機(jī)器學(xué)習(xí)訓(xùn)練的端到端編譯系統(tǒng)的概念與原型實(shí)現(xiàn)。

AutoSync 策略的自動(dòng)優(yōu)化流程算法
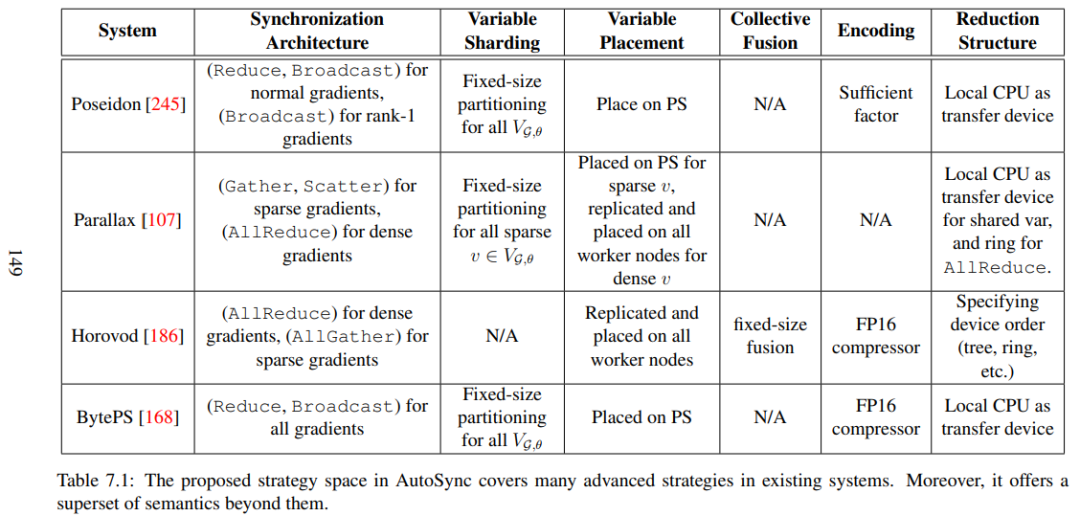
AutoSync 中的策略空間包含了現(xiàn)有系統(tǒng)中的很多高級(jí)策略 語言模型的分布式預(yù)訓(xùn)練示例 預(yù)訓(xùn)練語言表征已成為 NLP 系統(tǒng)中最普遍、最關(guān)鍵的部分。使用與任務(wù)無關(guān)的語言模型框架,可以對從 web 抓取的未標(biāo)記文本進(jìn)行無監(jiān)督的訓(xùn)練,只需預(yù)測下一個(gè)單詞或句子。預(yù)訓(xùn)練表征可以靈活地應(yīng)用于下游任務(wù),針對特定任務(wù)的損失和數(shù)據(jù)集進(jìn)行微調(diào),或是通過少量上下文學(xué)習(xí)。 近年來,人們在開發(fā)更強(qiáng)大的任務(wù)無關(guān) LM 架構(gòu)方面取得了巨大進(jìn)展,從單層詞向量表征到遞歸神經(jīng)網(wǎng)絡(luò)的多層表征和上下文狀態(tài),以及最新的基于遞歸 transformer 的架構(gòu)。 下圖展示了一個(gè)著名的例子——雙深度 Transformer(BERT)——屬于第三類。不管網(wǎng)絡(luò)架構(gòu)如何,語言模型通常包含許多參數(shù),而這些參數(shù)是在大規(guī)模文本語料庫上訓(xùn)練出來的,這是因?yàn)樗鼈兊慕D芰﹄S其大小以及文本掃描量成正比。
假設(shè)我們對訓(xùn)練 BERT 感興趣,在基于 AWS 的 GPU 集群上使用 TensorFlow 等框架實(shí)現(xiàn)。我們可以使用最先進(jìn)的開源訓(xùn)練系統(tǒng)——Horovod,開始數(shù)據(jù)并行訓(xùn)練。 應(yīng)用 Horovod 轉(zhuǎn)換單機(jī) BERT 訓(xùn)練代碼,涉及將原始的框架內(nèi)置優(yōu)化器與 Horovod 修補(bǔ)的優(yōu)化器包裝在一起。然后 Horovod 會(huì)在集群節(jié)點(diǎn)上使用 collective allreduce 或 allgather 來平均和應(yīng)用梯度。
這些 TensorFlow+Horovod 代碼片段展示了 Horovod 如何給優(yōu)化器打補(bǔ)丁,以及如何為分布式訓(xùn)練進(jìn)行非常小的代碼改變。 雖然可能會(huì)在目標(biāo)集群上部署訓(xùn)練,但獲得的擴(kuò)展不太可能隨著添加更多資源而成比例增長(理想情況下,線性擴(kuò)展與加速器的數(shù)量成比例增長):所有的語言模型都有嵌入層,這些層擁有很多模型參數(shù),但在每個(gè)設(shè)備上的每次訓(xùn)練迭代中訪問很少,減少或聚集其梯度都會(huì)導(dǎo)致不必要的網(wǎng)絡(luò)運(yùn)作;BERT 中的 transformer 是矩陣參數(shù)化、計(jì)算密集型的,與 Horovod 中的常規(guī)做法一樣,將梯度分組在一個(gè)縮減環(huán)(reduction ring)中,很容易使以太網(wǎng)帶寬或異構(gòu)集群 (如 AWS) 的設(shè)備 Flops 飽和。 在這兩種情況下,設(shè)置都容易出現(xiàn)通信或計(jì)算混亂的情況,即訓(xùn)練時(shí)間的縮短無法令人滿意,花費(fèi)在訓(xùn)練上的計(jì)算資源成本在經(jīng)濟(jì)上也不能接受。這表明,并行化的常規(guī)目標(biāo)并沒有實(shí)現(xiàn)。 所以,本文提出的這種自適應(yīng)并行策略,能夠?yàn)椴⑿谢阅苓M(jìn)行適當(dāng)?shù)膬?yōu)化。 作者介紹 張昊在今年 9 月 2 日完成了博士學(xué)位的論文答辯,導(dǎo)師為 CMU 教授、Petuum 創(chuàng)始人邢波(Eric Xing)。獲得 CMU 機(jī)器人研究所的博士學(xué)位后,他將以博士后身份進(jìn)入 UC 伯克利的 RISE 實(shí)驗(yàn)室,與計(jì)算機(jī)科學(xué)系教授 Ion Stoica 共同工作。
他的研究興趣包括可擴(kuò)展的機(jī)器學(xué)習(xí)、深度學(xué)習(xí)以及計(jì)算機(jī)視覺和自然語言處理領(lǐng)域的大規(guī)模機(jī)器學(xué)習(xí)應(yīng)用。他還協(xié)同設(shè)計(jì)了一系列模型、算法和系統(tǒng),在更大規(guī)模數(shù)據(jù)、問題、應(yīng)用中進(jìn)行機(jī)器學(xué)習(xí)擴(kuò)展,以簡化復(fù)雜機(jī)器學(xué)習(xí)模型和算法的原型開發(fā),使機(jī)器學(xué)習(xí)程序分布自動(dòng)化。
責(zé)任編輯:lq
-
計(jì)算機(jī)視覺
+關(guān)注
關(guān)注
8文章
1696瀏覽量
45927 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8377瀏覽量
132409 -
自然語言處理
+關(guān)注
關(guān)注
1文章
612瀏覽量
13504
原文標(biāo)題:229頁,CMU博士張昊畢業(yè)論文公布,探索機(jī)器學(xué)習(xí)并行化的奧秘
文章出處:【微信號(hào):TheBigData1024,微信公眾號(hào):人工智能與大數(shù)據(jù)技術(shù)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評(píng)論請先 登錄
相關(guān)推薦
下一代機(jī)器人技術(shù):工業(yè)自動(dòng)化的五大趨勢
機(jī)械自動(dòng)化和電氣自動(dòng)化區(qū)別是什么
機(jī)械自動(dòng)化是自動(dòng)化的一種嗎
工業(yè)機(jī)器人、PLC與自動(dòng)化之間的關(guān)系
機(jī)器視覺技術(shù)在工業(yè)自動(dòng)化中的應(yīng)用
機(jī)械制造與自動(dòng)化是自動(dòng)化類嗎
工業(yè)自動(dòng)化和自動(dòng)化區(qū)別是什么
機(jī)器視覺檢測技術(shù)在工業(yè)自動(dòng)化中的應(yīng)用
非標(biāo)自動(dòng)化設(shè)備
Zebra Aurora深度學(xué)習(xí)OCR算法榮獲CAIMRS頒發(fā)的自動(dòng)化創(chuàng)新獎(jiǎng)
工業(yè)自動(dòng)化系統(tǒng)設(shè)計(jì)

晶泰科技攜手ABB機(jī)器人打造柔性智能自動(dòng)化的實(shí)驗(yàn)室
電源測試怎么自動(dòng)化?電源模塊自動(dòng)化測試系統(tǒng)如何實(shí)現(xiàn)?
淺析中國工業(yè)自動(dòng)化與智能化應(yīng)用
傳感器推動(dòng)機(jī)器自動(dòng)化






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論