") 微軟亞洲研究院的研究員們提出了一種模型壓縮的新思路
微軟亞洲研究院的研究員們提出了一種模型壓縮的新思路
編者按:深度學(xué)習(xí)的發(fā)展推動(dòng)了很多大型神經(jīng)網(wǎng)絡(luò)模型的誕生,這些模型在多個(gè)領(lǐng)域中都取得了當(dāng)前最優(yōu)的性能,基于Transformer的預(yù)訓(xùn)練模型也在自然語(yǔ)言理解(NLU)和自然語(yǔ)言生成(NLG)領(lǐng)域中成為主流。然而,這些模型所包含的參數(shù)量巨大,計(jì)算成本高昂,極大地阻礙了此類模型在生產(chǎn)環(huán)境中的應(yīng)用。為了解決該問(wèn)題,來(lái)自微軟亞洲研究院自然語(yǔ)言計(jì)算組的研究員們提出了一種模型壓縮的新思路。
隨著深度學(xué)習(xí)的流行,很多大型神經(jīng)網(wǎng)絡(luò)模型誕生,并在多個(gè)領(lǐng)域中取得當(dāng)前最優(yōu)的性能。尤其是在自然語(yǔ)言處理(NLP)領(lǐng)域中,預(yù)訓(xùn)練和調(diào)參已經(jīng)成為其中大多數(shù)任務(wù)的新范式。基于 Transformer 的預(yù)訓(xùn)練模型在自然語(yǔ)言理解(NLU)和自然語(yǔ)言生成(NLG)領(lǐng)域中成為主流。盡管這些模型從“過(guò)參數(shù)化”的特性中獲益,但它們往往包含數(shù)百萬(wàn)甚至數(shù)十億個(gè)參數(shù),這就使得此類模型的計(jì)算成本高昂,且從內(nèi)存消耗和高延遲的角度來(lái)看計(jì)算低效。這一缺陷極大地阻礙了此類模型在生產(chǎn)環(huán)境中的應(yīng)用。
為了解決該問(wèn)題,研究人員提出了很多神經(jīng)網(wǎng)絡(luò)壓縮技術(shù)。一般而言,這些技術(shù)可以分為三類:量化、權(quán)重剪枝和知識(shí)蒸餾(Knowledge Distillation)。其中,由于知識(shí)蒸餾能夠壓縮預(yù)訓(xùn)練語(yǔ)言模型,所以得到了極大關(guān)注。知識(shí)蒸餾利用大型教師模型“教”緊湊的學(xué)生模型模仿教師的行為,從而將教師模型中嵌入的知識(shí)遷移到較小的模型中。但是,學(xué)生模型的性能狀況取決于設(shè)計(jì)良好的蒸餾損失函數(shù),正是這個(gè)函數(shù)使得學(xué)生模型可以模仿教師的行為。近期關(guān)于知識(shí)蒸餾的研究甚至利用更復(fù)雜的模型特定蒸餾損失函數(shù),以實(shí)現(xiàn)更好的性能。
近日,來(lái)自微軟亞洲研究院自然語(yǔ)言計(jì)算組的研究員們提出了一種與顯式地利用蒸餾損失函數(shù)來(lái)最小化教師模型與學(xué)生模型距離的知識(shí)蒸餾不同的模型壓縮新方法。受到著名哲學(xué)思想實(shí)驗(yàn)“忒修斯之船”的啟發(fā)(即如果船上的木頭逐漸被替換,直到所有的木頭都不是原來(lái)的木頭,那這艘船還是原來(lái)的那艘船嗎?),研究員們?cè)?EMNLP 2020 上發(fā)表了 Theseus Compression for BERT (BERT-of-Theseus),該方法逐步將 BERT 的原始模塊替換成參數(shù)更少的替代模塊(點(diǎn)擊文末閱讀原文,了解論文詳情)。研究員們將原始模型叫做“前輩”(predecessor),將壓縮后的模型叫做“接替者”(successor),分別對(duì)應(yīng)知識(shí)蒸餾中的教師和學(xué)生。
該方法的工作流程如下圖所示。首先為每個(gè)前輩模塊指定一個(gè)接替者模塊,然后在訓(xùn)練階段中以一定的概率(如拋硬幣)決定是否用替代模塊隨機(jī)替換對(duì)應(yīng)的前輩模塊,并按照新舊模塊組合的方式繼續(xù)訓(xùn)練。在模型收斂后,將所有接替者模塊組合成接替者模型,進(jìn)而執(zhí)行推斷。這樣就可以將大型前輩模型壓縮成緊湊的接替者模型了。
舉例來(lái)說(shuō),假設(shè)現(xiàn)在有兩支籃球隊(duì)每支各五人,一支是經(jīng)驗(yàn)老道的全明星球隊(duì),另一支則是年輕球員組成的青訓(xùn)隊(duì)。為了提高青訓(xùn)隊(duì)的水平,所以隨機(jī)選派青訓(xùn)隊(duì)員去替換掉全明星隊(duì)中的球員,然后讓這個(gè)混合的球隊(duì)不斷地練習(xí)、比賽。通過(guò)向前輩學(xué)習(xí)經(jīng)驗(yàn),新加入成員的實(shí)力會(huì)有所提升,也能學(xué)會(huì)和其他隊(duì)員的配合,逐漸的這個(gè)混合球隊(duì)就擁有了接近全明星球隊(duì)的實(shí)力。之后重復(fù)這個(gè)過(guò)程,直到青訓(xùn)隊(duì)員都被充分訓(xùn)練,最終青訓(xùn)隊(duì)員也能自己組成一支實(shí)力突出的球隊(duì)。相比之下,如果沒(méi)有“老司機(jī)”來(lái)帶一帶,青訓(xùn)隊(duì)無(wú)論如何訓(xùn)練,水平也不會(huì)達(dá)到全明星隊(duì)的實(shí)力。
事實(shí)上,Theseus 壓縮與知識(shí)蒸餾的思路有些類似,都是鼓勵(lì)壓縮模型模仿原始模型的行為,但 Theseus 壓縮有很多獨(dú)特的優(yōu)勢(shì)。
首先,Theseus 壓縮在壓縮過(guò)程中僅使用任務(wù)特定的損失函數(shù)。而基于知識(shí)蒸餾的方法除了使用任務(wù)特定的損失函數(shù)外,還需加入繁瑣的蒸餾損失函數(shù)作為優(yōu)化目標(biāo)。
其次,與近期研究 TinyBERT 等不同,Theseus 壓縮不使用Transformer 特定特征進(jìn)行壓縮,這就為壓縮廣泛模型提供了可能性。與知識(shí)蒸餾僅使用原始模型執(zhí)行推斷不同,該方法允許前輩模型與壓縮后的接替者模型共同訓(xùn)練,從而實(shí)現(xiàn)更深層次的梯度級(jí)交互,并簡(jiǎn)化訓(xùn)練過(guò)程。
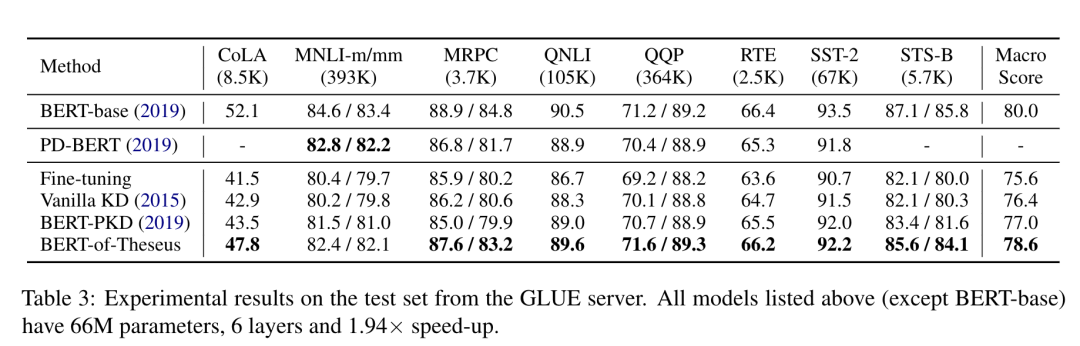
此外,混合了前輩模塊和接替者模塊的不同模塊組合還添加了額外的正則化項(xiàng)(類似于 Dropout)。該方法基于課程學(xué)習(xí)(Curriculum Learning)方法來(lái)驅(qū)動(dòng)模塊替換,將模塊替換概率從低到高逐漸增加,從而實(shí)現(xiàn)優(yōu)異的 BERT 壓縮性能。利用Theseus 壓縮方法壓縮得到的 BERT 模型運(yùn)算速度是之前的1.94 倍,并且保留了原始模型超過(guò)98% 的性能,優(yōu)于其它基于知識(shí)蒸餾的壓縮的基線方法。
通過(guò)在預(yù)訓(xùn)練語(yǔ)言模型 BERT 上的成功實(shí)驗(yàn),微軟亞洲研究院的研究員們希望可以為模型壓縮打開(kāi)一種全新的思路,并希望看到這一方法在計(jì)算機(jī)視覺(jué)等領(lǐng)域的更廣泛應(yīng)用。
責(zé)任編輯:lq
-
微軟
+關(guān)注
關(guān)注
4文章
6572瀏覽量
103963 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4765瀏覽量
100568 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4308瀏覽量
62447
原文標(biāo)題:【EMNLP2020】忒修斯之船啟發(fā)下的知識(shí)蒸餾新思路 - 微軟研究院
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
微軟在東京開(kāi)設(shè)日本首個(gè)研究基地
藍(lán)思科技將新增昆山創(chuàng)新研究院,重點(diǎn)服務(wù)蘋果
摩爾線程攜手智源研究院完成基于Triton的大模型算子庫(kù)適配
長(zhǎng)沙北斗研究院總部基地正式奠基
航天宏圖與天儀研究院合作共同推動(dòng)遙感衛(wèi)星數(shù)據(jù)應(yīng)用創(chuàng)新

微軟亞洲研究院發(fā)布VASA-1模型,實(shí)現(xiàn)圖片人物自動(dòng)言語(yǔ)表達(dá)
本源入榜胡潤(rùn)研究院2024全球獨(dú)角獸榜單!

依托廣立微建設(shè)的浙江省集成電路EDA技術(shù)重點(diǎn)企業(yè)研究院正式掛牌

谷歌DeepMind資深A(yù)I研究員創(chuàng)辦AI Agent創(chuàng)企
廣東腐蝕科學(xué)與技術(shù)創(chuàng)新研究院選購(gòu)HS-DR-5導(dǎo)熱系數(shù)測(cè)試儀

微軟內(nèi)部對(duì)亞洲研究院的未來(lái)持有不同看法
LabVIEW進(jìn)行癌癥預(yù)測(cè)模型研究
周禮棟對(duì)話比爾·蓋茨:深入的科學(xué)研究比以往任何時(shí)候都更加重要






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論