 基于主動學習的半監督圖神經網絡模型來對分子性質進行預測方法
基于主動學習的半監督圖神經網絡模型來對分子性質進行預測方法
1 引言
最近,越來越多的研究開始將深度學習方法應用到圖數據領域。圖神經網絡在數據具有明確關系的結構場景,如物理系統,分子結構和知識圖譜中有著廣泛的研究價值和應用前景,本文將介紹在KDD 2020上發表的兩個在這一場景下的最新工作。
第一個工作是Research Track的《ASGN: An Active Semi-supervised Graph Neural Network for Molecular Property Prediction》,提出了一種基于主動學習的半監督圖神經網絡模型來對分子性質進行預測方法。
第二個工作是Research Track的《Hierarchical Attention Propagation for Healthcare Representation Learning》,基于注意力機制,提出了一種利用的層次信息表示醫學本體的表示學習模型。
2 ASGN: An Active Semi-supervised Graph Neural Network for Molecular Property Prediction
2.1 動機與貢獻
分子性質(如能量)預測是化學和生物學中的一個重要問題。遺憾的是,許多監督學習方法都存在著標記分子在化學空間中稀缺的問題,而這類屬性標記通常是通過密度泛函理論(DFT)計算得到的,計算量非常大。一個有效的解決方案是使用半監督方法使未標記的分子也能參與訓練。然而,學習大量分子的半監督表示具有挑戰性,存在包括分子本質和結構的聯合表征,表征與屬性學習的沖突等問題。本文作者提出了一個新的框架,結合了標記和未標記的分子來預測分子性質,稱為主動半監督圖神經網絡(ASGN)。
2.2 模型
本文提出了一種新的主動半監督圖神經網絡(ASGN)框架,通過在化學空間中合并標記和未標記的分子來預測分子的性質。總體框架如圖2所示。
總體來講,本文使用教師模型和學生模型來迭代訓練。每個模型都是一個圖神經網絡。在教師模型中,使用半監督的方式來獲得分子圖的一般表示。我們聯合訓練分子的無監督表示和基于屬性預測的embedding。在學生模型中,通過微調教師模型中的參數來處理損失沖突。之后,再使用學生模型為未標記的數據集分配偽標簽。作為對教師模型的反饋,教師模型可以從這些偽標簽中學習學生模型學到的知識。同時,為了提高標記效率,作者使用了主動學習來選擇新的有代表性的未標記分子進行標記。然后再將它們添加到標記的集合中,并反復fine-tune兩個模型,直到達到預設精度。整個模型的核心思想是利用教師模型輸出的embedding來尋找整個未標記集合中最具有多樣化性質的子集,然后再使用DFT等方法給這些分子分配基本的真值標簽。之后,將它們添加到標簽集中,并重復迭代以提高性能。
2.2.1 教師模型
在教師模型中,本文采用了半監督學習方式。教師模型的損失函數由三部分組成,一個具有標記的分子的性質損失函數和兩個無監督損失函數(分別從節點和圖層面)。
(1) 本文使用了一種消息傳遞圖神經網絡(MPGNN),先將分子圖轉化為基于消息傳遞圖神經網絡的表示向量,之后在預測和標記(即中的標記屬性)之間使用均方損失(MSE)來指導模型參數的優化
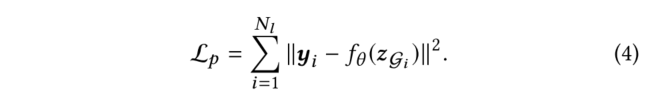
(2)在節點級表示學習中,模型主要學習從分子圖的幾何信息中獲取領域知識。其主要思想是使用node embedding從表示中重建節點類型和拓撲(節點之間的距離)。具體地說,我們首先從圖2所示的圖中對一些節點和邊進行隨機采樣,然后將這些節點的表示傳遞給MLP,并用它們重建節點類型和節點間的距離。從數學上講,本文最小化了以下交叉熵:
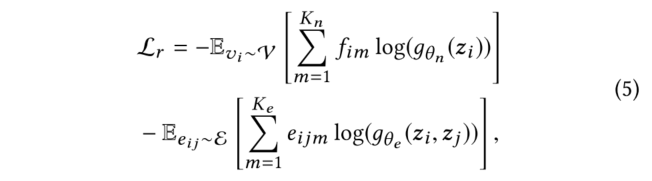
(3)雖然能夠重構分子拓撲結構的節點嵌入可以有效地表示分子的結構,然而結合圖級表示學習對屬性預測等下游任務也是有益的。為了學習圖級表示,關鍵是利用化學空間中分子之間的相互關系,即相似的分子具有相似的性質。本文提出了一種基于學習聚類的圖級表示方法。首先,計算網絡的圖級embedding。然后,我們使用一種基于隱式聚類的方法來為每個分子分配一個由隱式聚類過程生成的聚類ID,然后利用一個懲罰損失函數對模型進行優化,該過程迭代進行直到達到局部最小值。
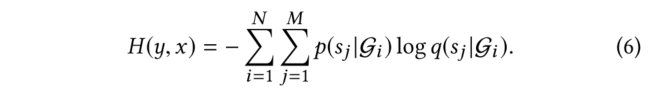
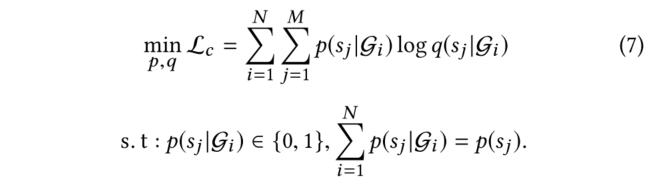
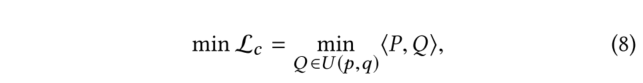
(4)總LOSS:
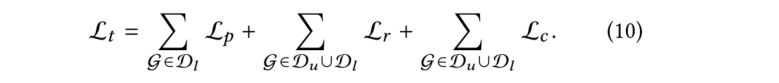
2.2.2 學生模型
在實際應用中,直接優化教師模型中的公式(10)對屬性預測的結果并不理想。由于教師模型中的優化目標之間存在沖突,每個聯合優化目標的性能都比單獨優化的性能要差。尤其是當帶標記分子遠少于無標記分子時,模型很少關注一個epoch內對的優化,但對于分子性質的預測是本文最關心的問題。因此,與只需學習分子性質的模型相比,教師模型對于分子預測的損失要高得多。為了緩解這個問題,本文引入了一個學生模型。具體過程為:使用教師模型,通過共同優化上述對象函數來學習分子表示,當教師模型的學習過程結束時,我們將教師模型的權重轉移到學生模型上,并使用學生模型僅對標記的數據集進行fine-tuning,以學習與圖2所示公式(4)相同的分子性質:
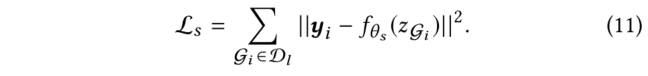
在fine-tuning之后,我們使用學生模型來推斷整個未標記的數據集,并為每個未標記的數據分配一個偽標簽,表示學生對其性質的預測,未標記的數據集為
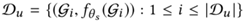
,其中為學生模型的參數。在下一次迭代中,教師模型還需要學習這樣的偽標簽,公式(10)變成:
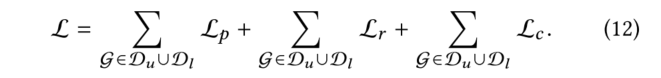
2.2.3 使用主動學習進行數據選擇
在模型中本文已經把這些信息包括在有標記和未標記的分子中。然而,由于可用標簽數量有限,準確度仍可能不盡如人意,所以需要尋找新的標簽數據來提高其性能。因此,在每一次迭代中,我們使用教師模型輸出的embedding迭代地選擇一個分子子集,并通過DFT計算其性質(真值標簽)。然后我們將這些通過主動學習輸出的分子加入到標記集中,以迭代的方式微調兩個模型。主動學習的關鍵策略是在化學空間中中找到一小批最多樣化的分子來進行標記。一個經過充分研究的測量多樣性的方法是從k-DPP中取樣。然而,由于子集選擇是NP難的,因此本文采用了貪婪近似,即k-中心法。用表示未標記的數據集,用表示有標記的數據集,我們采用一種貪婪的方法,在每次迭代中選擇一個子集,使標記集和未標記集之間的距離最大化。具體來說,對于第k批中的每個0
是兩個分子之間的距離。
2.3 實驗
2.3.1 實驗設置
? Datasets:
(1) QM9: 130,000 molecules, <9 heavy atoms
(2) OPV: 100,000 medium sized molecules
? Properties (All calculated by DFT)
(1) QM9:
(2) OPV:
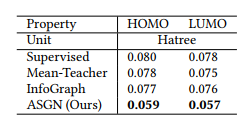
2.3.2 實驗結果
Results on QM9
Results on OPV
3 Hierarchical Attention Propagation for Healthcare Representation Learning
3.1 動機與貢獻
醫學本體論被廣泛用于表示和組織醫學術語。例如ICD-9、ICD-10、UMLS等。本體論通常以層次結構構建,編碼不同醫學概念之間的多層次子類關系,允許概念之間有非常細微的區別。醫學本體論為將領域知識整合到醫療預測系統中提供了一個很好的途徑,并可以緩解數據不足的問題,提高稀有類別的預測性能。為了整合這些領域知識,Gram是一種最新的圖形注意力模型,它通過一種注意機制將醫學概念表示為其祖先embedding到本體中的加權和。盡管表現出了不錯的性能,但Gram只考慮了概念的無序祖先,沒有充分地利用層次結構,因此表達能力有限。在本文中,我們提出了一種新的醫學本體嵌入模型HAP,該模型將注意力分層地傳播到整個本體結構中,醫學概念自適應地從層次結構中的所有其他概念學習其embedding,而不僅僅是它的祖先。本文證明了HAP能夠學習到更具表現力的醫學概念embedding——從任意醫學概念embedding中能夠完全還原整個本體結構。在兩個序列程序/診斷預測任務上的實驗結果表明,HAP的embedding質量優于Gram和其他baseline。此外,本文發現使用完整的本體并不總是最好的。有時只使用較低層次的概念比使用所有層次的效果要好。
3.2 模型
本文提出了一種新的醫學本體嵌入方法:
1)充分層次化知識的DAG(有向無環圖)
2)尊重層次內節點的有序性。
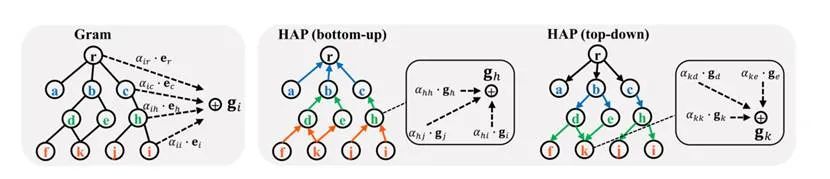
HAP對模型進行兩輪信息傳播,更新每一級節點的嵌入:第一次是自下而上的傳播,第二次是自上而下的傳播。
假設本體節點有L層,其中第一層只包括單個根節點,第L層只有葉子醫療代碼。第2,3,……L ?1層可以包含中間類別節點或葉醫療代碼(因為某些醫療代碼沒有完整的L層)。一開始,每個節點的embedding是由一個基本embedding 初始化的。在自底向上的信息傳播中,我們從第L-1層開始依次更新節點的embedding,直到第一層。對于第層的某一節點,本文通過使用注意力機制自適應地將當前embedding與第層的其子級embedding相結合來更新其embedding :
其中表示開始更新-1層節點前節點的embedding,表示embedding大小。注意力權重的計算公式為:
其中是一個用于計算和之間標量原始注意力的MLP。
自下而上的傳播從第二層直到根節點為止。同一級別的節點更新可以并行執行,而上層節點的更新必須等到其所有較低級別都已更新為止。給定由自下而上傳播計算的embedding,HAP以自頂向下的方式執行第二輪傳播。具體地說,我們從第二層,第三層……直到第L層順序更新節點的embedding。對于來自第-1層的節點,使用一個使用一個類似的注意力機制自適應地將當前節點的embedding與來自第層的其父級embedding相結合來更新其embedding :
其中表示開始更新+1層節點前節點的embedding。注意力權重的計算公式為:
最后,在兩輪傳播之后,每個節點都將其注意力傳播到整個知識DAG中。因此,每個節點的最終嵌入不僅有效地吸收了其祖先的知識,還吸收了其后代、兄弟姐妹,甚至一些遙遠節點的知識。此外,由于傳播順序與層次結構嚴格一致,因此保留了節點排序信息。例如,在自頂向下的傳播階段,節點的祖先按順序逐級向下傳遞信息,而不是像(1)中那樣一次性傳遞信息。這使得HAP能夠從不同層次上區分祖先/后代,并對排序信息進行編碼。
最終的醫學代碼嵌入用于順序程序/診斷預測任務。在之后,本文采用了端到端的RNN框架。將最終得到的embedding , ,…… 以列的形式進行拼接得到embedding矩陣 ,注意一個訪問記錄可以被表示為multi-hot向量。為了對于每一個屬于的醫學代碼都得到一個embedding向量,本文用與相乘并使用一個非線性變換:
之后我們依次將,,……,輸入RNN中,并對每一個訪問輸出一個中間隱藏態,隱藏狀態是通過過去所有的時間戳直到到t的訪問給出的:
之后,對于下一時間戳的預測由下式給出:
我們使用分批梯度下降來最小化所有時間戳(除了時間戳1)的預測損失。單個患者的預測損失由下式得出:
3.3 實驗
數據集設置:
結果:
?HAP (lv3): 所提出的HAP模型只使用最低的3個層次。也就是說,自下而上的傳播在L-2層停止,自頂向下的傳播也從L-2層開始。可以發現有時只使用較低層次的層次,就可以提供足夠的領域知識,同時降低了計算復雜度。
? HAP (lv2): HAP模型只使用最低的2個層次.
責任編輯:lq
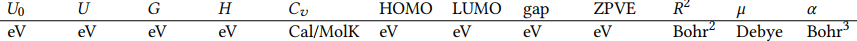


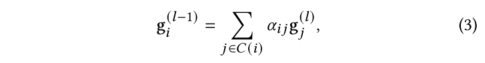
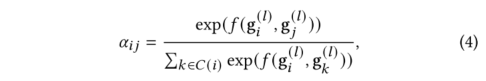
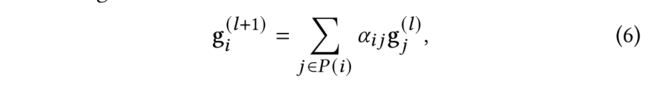
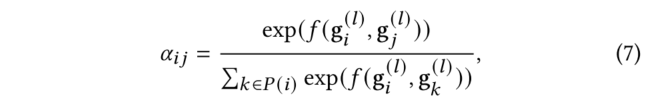
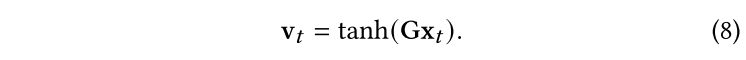
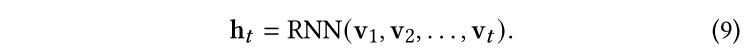
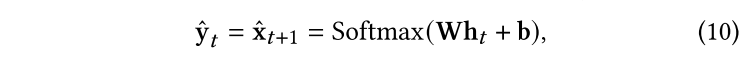
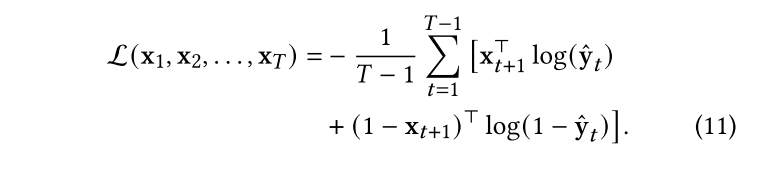
-
神經網絡
+關注
關注
42文章
4765瀏覽量
100568 -
函數
+關注
關注
3文章
4308瀏覽量
62445 -
模型
+關注
關注
1文章
3178瀏覽量
48731
原文標題:【KDD20】圖神經網絡在生物醫藥領域的應用
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論